1.Hive简介
Hive是一个基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一个表。并提供类SQL查询功能,
可以将sql语句转换为MapReduce任务运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce
统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析
2.数据仓库(面向主题、历史):
数据库是用来支撑在线联机业务的。如页面上数据的展示,保存客户操作产生的数据。这类要求变更是实时的、
事务的。
数据仓库:如果联机数据库中的数据太大了,需要将历史信息导入到离线的仓库中。数据仓库中可以存入各种
业务系统的数据,并按照一定主题来组织这些数据表。数据仓库中的数据一般用来做统计,数据分析。比如统计年
度销售额,月度销售额,广告推荐等,简而言之,数据仓库是用来做查询分析的数据库,基本不用来做插入,修改,
删除。
3.Hive的工作机制:
将清洗过的数据放入到HDFS中,就可进行各种统计了。但有些需求用MapReduce写起来非常难,所以有了Hive;
Hive运行时,元数据信息存储在关系型数据库里面,如mysql、derby。Hive中的元数据包括表的名字,表的列和
分区及其属性,表的属性(是否为外部表等),表的数据所在目录等;
Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询,比如select * from tbl不会
生成MapRedcue任务)
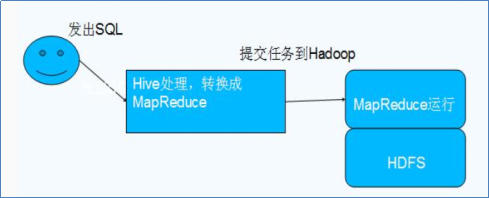
4.Hive和Hadoop的关系:
Hive利用HDFS存储数据,利用MapReduce查询数据
5.Hive的数据存储:
1、Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,RCFILE等)
2、只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
3、Hive 中包含以下数据模型:DB、Table,External Table,Partition,Bucket。
db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
table:在hdfs中表现所属db目录下一个文件夹
external table:与table类似,不过其数据存放位置可以在任意指定路径
partition:在hdfs中表现为table目录下的子目录
bucket:在hdfs中表现为同一个表目录下根据hash散列之后的多个文件