1.需求:将Json格式的数据处理后插入新表中
数据文件如下:rating.json,文件格式:{"movie":"2858","rate":"5","timeStamp":"978159467","uid":"17"}
{"movie":"2028","rate":"5","timeStamp":"978301619","uid":"1"}
{"movie":"531","rate":"4","timeStamp":"978302149","uid":"1"}
{"movie":"3114","rate":"4","timeStamp":"978302174","uid":"1"}
{"movie":"608","rate":"4","timeStamp":"978301398","uid":"1"}
{"movie":"1246","rate":"4","timeStamp":"978302091","uid":"1"}
{"movie":"1357","rate":"5","timeStamp":"978298709","uid":"2"}
{"movie":"3068","rate":"4","timeStamp":"978299000","uid":"3"}
{"movie":"1537","rate":"4","timeStamp":"978299620","uid":"3"}
{"movie":"434","rate":"2","timeStamp":"978300174","uid":"4"}
{"movie":"2126","rate":"3","timeStamp":"978300123","uid":"5"}
{"movie":"2067","rate":"5","timeStamp":"978298625","uid":"6"}
{"movie":"1265","rate":"3","timeStamp":"978299712","uid":"7"}
实现步骤:
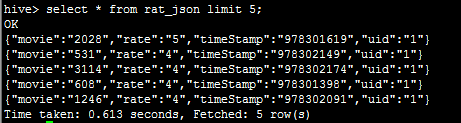
1.使用Hive创建原始表rate_json,并将rating.json文件加载到该表
hive> create table rat_json(line string) row format delimited;
hive> load data local inpath '/root/rating.json' into table rat_json;
2.实现方案1:自定义函数实现json数据字段的切分
2.1:开发java类继承UDF,然后重载evaluate方法
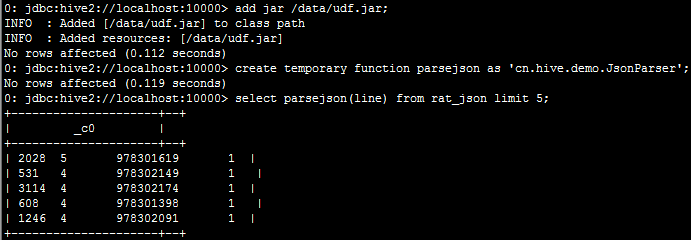
2.2:上传jar包至服务器,并将jar包添加到hive的classpath下:hive>add jar /data/udf.jar;
2.3:创建临时函数与开发好的java class关联:create temporary function parsejson as 'cn.hive.demo.JsonParser';
3.实现方案2:使用内置函数split进行字段切分,然后保存到一张新表中;

insert overwrite table t_rating
select split(parsejson(line),' ')[0]as movieid,split(parsejson(line),' ')[1] as rate,
split(parsejson(line),' ')[2] as timestring,split(parsejson(line),' ')[3] as uid
from rat_json limit 10;

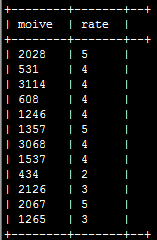
4.实现方案3:使用内置jason函数;
select get_json_object(line,'$.movie') as moive,get_json_object(line,'$.rate') as rate from rat_json;
5.实现方案4:Hive的 Transform 关键字提供了在SQL中调用自写脚本的功能,适合实现Hive中没有的功能又不想写UDF的情况
使用transform+python脚本的方式
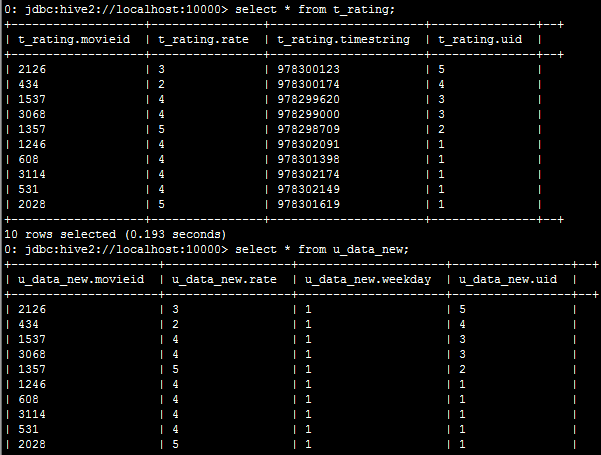
根据上述过程,将原始表rat_json中的json格式的数据进行切分并存储到t_rating表中:
5.1:编辑一个Python脚本:weekday_mapper.py
#!/bin/python import sys import datetime for line in sys.stdin://标准输出到屏幕上的东西 line = line.strip() movieid, rating, unixtime,userid = line.split(' ')//t_rating表输出到屏幕上的数据是以table键隔开显示的 weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday() print ' '.join([movieid, rating, str(weekday),userid])
5.2:将文件加入hive的classpath:hive> add file /root/weekday_mapper.py;
5.3:执行查询
hive>create table u_data_new as
SELECT
TRANSFORM (movieid, rate, timestring,uid)
USING 'python weekday_mapper.py'
AS (movieid, rate, weekday,uid)
FROM t_rating;
使用transform+python的方式去转换unixtime为weekday