4 模块开发—数据预处理
4.1 主要目的:
过滤“不合规”数据
格式转换和规整
根据后续的统计需求,过滤分离出各种不同主题(不同栏目path)的基础数据
4.2 实现方式:
开发一个MapReduce程序WeblogPreProcess来实现逻辑;
运行mr对数据进行预处理:hadoop jar click.jar cn.itcast.bigdata.hive.mr.pre.WeblogPreProcess /azaz /fenazaz
如上步骤即就是:将采集的日志文件access.log,进行清洗;
4.3 点击流模型数据梳理
由于大量的指标统计从点击流模型中更容易得出,所以在预处理阶段,可以使用mr程序来生成点击流模型的数据
4.3.1 点击流模型pageviews表(按session聚集的访问页面信息)
hadoop jar click.jar cn.itcast.bigdata.hive.mr.ClickStreamThree /fenazaz /pageviews
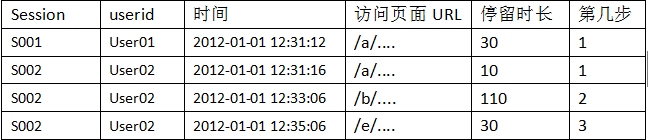
4.3.2 点击流模型visit信息表:用MR程序从pageviews数据中,梳理出每一次visit的起止时间、页面信息
hadoop jar click.jar cn.itcast.bigdata.hive.mr.ClickStreamVisit /pageviews /visitout
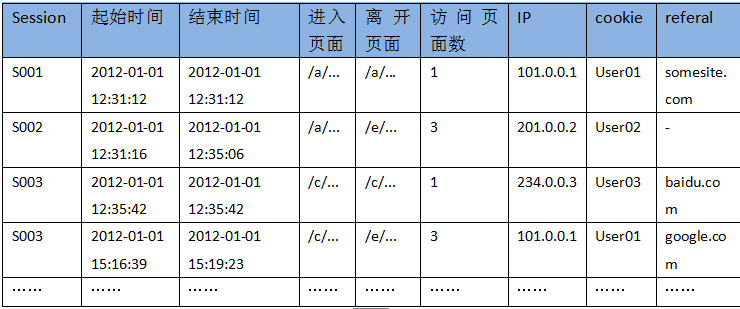
这就是点击流模型。当WEB日志转化成点击流数据的时候,很多网站分析度量的计算变得简单了,这就是点击流
的“魔力”所在。基于点击流数据我们可以统计出许多常见的网站分析度量
然后,在hive仓库中建点击流visit模型表:
drop table if exist click_stream_visit; create table click_stream_visit( session string, remote_addr string, inTime string, outTime string, inPage string, outPage string, referal string, pageVisits int) partitioned by (datestr string);
然后,将MR运算得到的visit数据导入visit模型表
load data inpath '/visitout' into table click_stream_visit partition(datestr='2013-09-18');
|
load data inpath '/weblog/visitout' into table click_stream_visit partition(datestr='2013-09-18'); |