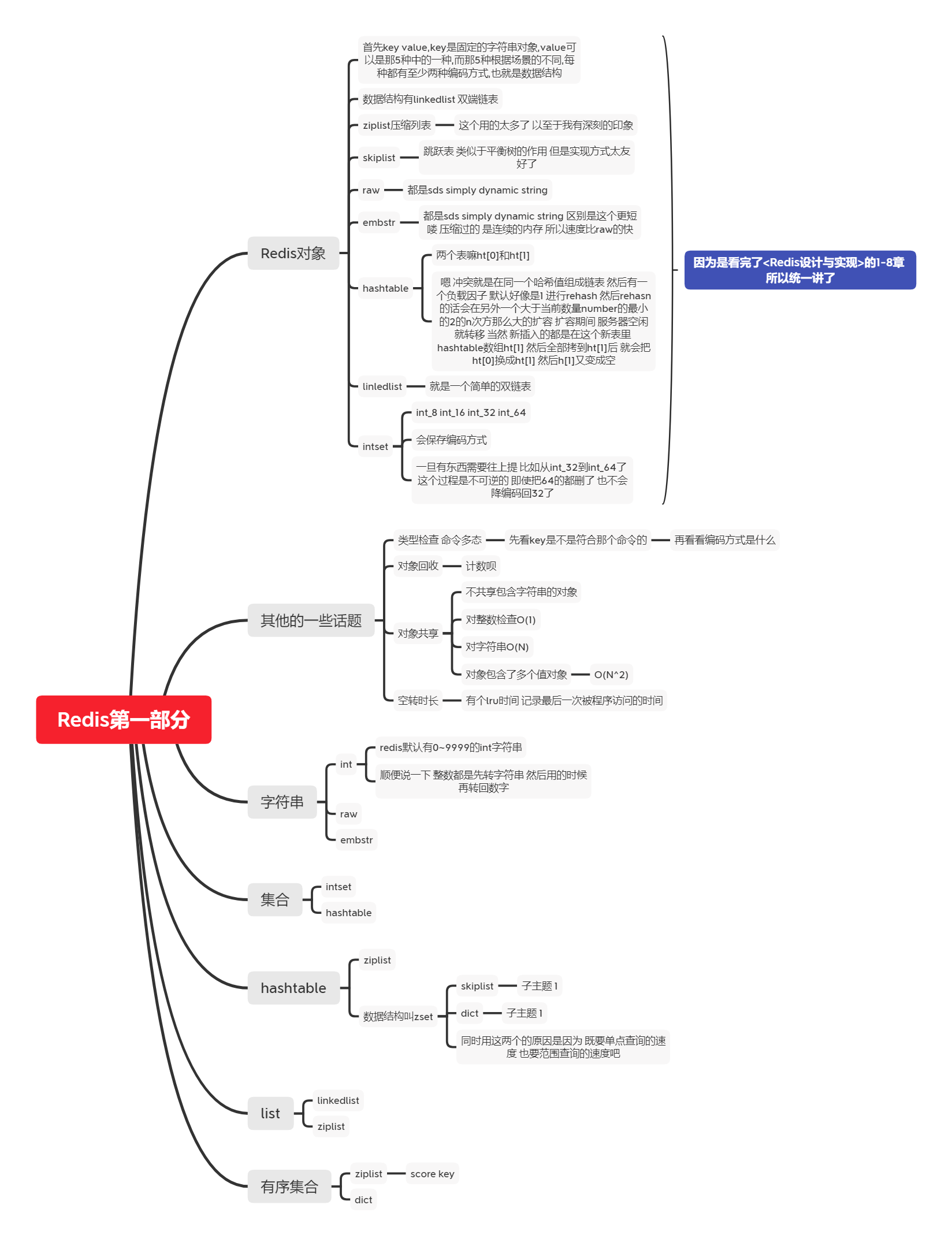
Redis第一部分
建议已经有这部分知识的人看 用来查漏补缺
我会迭代更新
Redis对象
首先key value,key是固定的字符串对象,value可以是那5种中的一种,而那5种根据场景的不同,每种都有至少两种编码方式,也就是数据结构
数据结构有linkedlist 双端链表
ziplist压缩列表
- 这个用的太多了 以至于我有深刻的印象
skiplist
- 跳跃表 类似于平衡树的作用 但是实现方式太友好了
raw
- 都是sds simply dynamic string
embstr
- 都是sds simply dynamic string 区别是这个更短喽 压缩过的 是连续的内存 所以速度比raw的快
hashtable
- 两个表嘛ht[0]和ht[1]
- 嗯 冲突就是在同一个哈希值组成链表 然后有一个负载因子 默认好像是1 进行rehash 然后rehasn的话会在另外一个大于当前数量number的最小的2的n次方那么大的扩容 扩容期间 服务器空闲就转移 当然 新插入的都是在这个新表里 hashtable数组ht[1] 然后全部拷到ht[1]后 就会把ht[0]换成ht[1] 然后h[1]又变成空
linledlist
- 就是一个简单的双链表
intset
- int_8 int_16 int_32 int_64
- 会保存编码方式
- 一旦有东西需要往上提 比如从int_32到int_64了 这个过程是不可逆的 即使把64的都删了 也不会降编码回32了
其他的一些话题
类型检查 命令多态
-
先看key是不是符合那个命令的
- 再看看编码方式是什么
对象回收
- 计数呗
对象共享
-
不共享包含字符串的对象
-
对整数检查O(1)
-
对字符串O(N)
-
对象包含了多个值对象
- O(N^2)
空转时长
- 有个lru时间 记录最后一次被程序访问的时间
字符串
int
- redis默认有0~9999的int字符串
- 顺便说一下 整数都是先转字符串 然后用的时候再转回数字
raw
embstr
集合
intset
hashtable
hashtable
ziplist
数据结构叫zset
-
skiplist
- 子主题 1
-
dict
- 子主题 1
-
同时用这两个的原因是因为 既要单点查询的速度 也要范围查询的速度吧
list
linkedlist
ziplist
有序集合
ziplist
- score key
dict
XMind: ZEN - Trial Version