首先页面需要一个a标签直接指向下载文件的Action并传值:图片地址,以及图片名称(记住要带后缀名的).
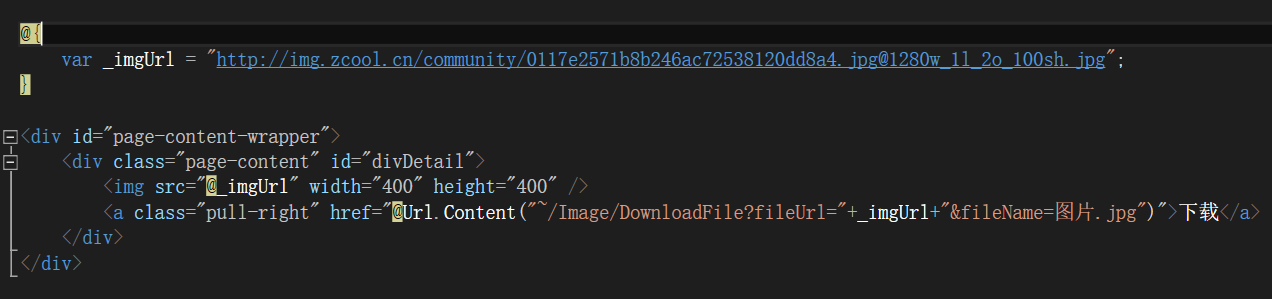
然后是Action里面的代码.
/// <summary> /// 根据文件地址下载文件 /// </summary> /// <param name="fileUrl">图片完整路径</param> /// <param name="fileName">图片名称</param> /// <returns></returns> public ActionResult DownloadFile(string fileUrl, string fileName) { var _buffer = SiteHelper.DownloadFile(fileUrl); return File(_buffer, MimeMapping.GetMimeMapping(fileUrl), fileName); }
SiteHelper.DownloadFile(fileUrl)方法是根据路径,请求出文件流,然后返回出来.
MimeMapping.GetMimeMapping()方法是返回映射指定的文件名的MIME.
fileName就是文件的完整名称.(注意后缀名:.jpg.txt.png等等).
下面贴出SiteHelper.DownloadFile()代码:
/// <summary> /// 根据文件地址返回文件流 /// </summary> /// <param name="fileUrl">文件地址</param> /// <returns></returns> public static byte[] DownloadFile(string fileUrl) { //创建一个请求对象 HttpWebRequest request = (HttpWebRequest)WebRequest.Create(fileUrl); //超时时间 request.Timeout = 60000; //获取回写流 WebResponse response = request.GetResponse(); byte[] buffer = new byte[1024]; int actual = 0; using (Stream s = response.GetResponseStream()) { //先保存到内存流中MemoryStream MemoryStream ms = new MemoryStream(); while ((actual = s.Read(buffer, 0, 1024)) > 0) { ms.Write(buffer, 0, actual); } ms.Position = 0; //再从内存流中读取到byte数组中 buffer = ms.ToArray(); } return buffer; }
这个循环是为了取出完整的文件而写(文件太大,有可能一次并没有取完).
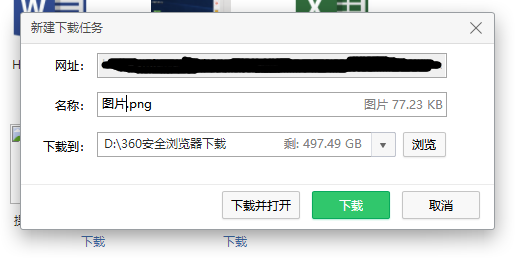
最后结果: