其他知识点
1,上下文管理
例1.
import contextlib
@contextlib.contextmanager
def f1():
try:
yield "ok" # --------------- 2
except Exception as e:
print(e)
finally:
print("Finally") # ------------------- 3
with f1() as a: #----------------------1
print("a:", a)
注意:执行流程,首先会执行with,在执行with的过程中会执行f1()函数,一直到yield停止,然后在with退出的一瞬间会执行finally
例2.
import contextlib import socket @contextlib.contextmanager def context_socket(host, port): sk = socket.socket() sk.bind((host, port)) sk.listen(5) try: yield sk finally: sk.close() with context_socket as sock: # data = sock.accept() # .... print(sock)
这个是上下文管理比较实用的一个例子,with下面可以做很多的操作,省去了关闭文件的这一步。
2, redis的发布和订阅
首先先定义一个redis的类, redis1.py


class RedisHelper: def __init__(self): self.__conn = redis.Redis(host='10.1.1.3') def publish(self, msg, chan): self.__conn.publish(chan, msg) return True def subscribe(self, chan): pub = self.__conn.pubsub() pub.subscribe(chan) pub.parse_response() return pub
import redis1 obj = redis1.RedisHelper() data = obj.subscribe('fm111.7') print(data.parse_response())
import redis1 obj = redis1.RedisHelper() obj.publish('alex db', 'fm111.7') #主要执行完redis3.py的发布,redis2就能及时的收到消息。
概念
RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现。
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消 息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用。通常是用于诸如远程过程调用的技术。排队指的是应用程序通过 队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。
一,基础
安装配置epel源 $ rpm -ivh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm 安装erlang $ yum -y install erlang 安装RabbitMQ $ yum -y install rabbitmq-server 启动:/etc/init.d/rabbitmq-server start
安装API操作RabbitMQ
pip install pika
对于RabbitMQ来说,生产和消费不再针对内存里的一个Queue对象,而是某台服务器上的RabbitMQ Server实现的消息队列。
首先举个小例子

import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host='10.1.1.3')) # 创建连接 channel = connection.channel() # 创建频道 channel.queue_declare(queue='hello') # 定义一个队列: 'hello'(如果RabbitMQ有'hello'这个队列,这一句就没有意义了) channel.basic_publish(exchange='', routing_key='hello', # 要发送的队列 body='Hello World!') # 发送数据的内容 print(" [x] Sent 'Hello World!'") connection.close()
import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host='10.1.1.3')) channel = connection.channel() # 创建频道 channel.queue_declare(queue='hello') # 如果RabbitMQ中有这个队列什么都不用干,如果没有,则创建队列'hello' def callback(ch, method, properties, body): # 依次为:ch为频道,方法,属性,以及取到的内容 print(" [x] Received %r" % body) channel.basic_consume(callback, queue='hello', no_ack=True) # 消费者去队列'hello'中取数据,并执行回调函数callback print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming() # 等待接收消息
二, RabbitMQ的使用
1,acknowledgment消息不丢失
no_ack = False,如果消费者遇到(its channel is closed, connection is closed, or TCP connection is lost)挂掉了,那么RabbitMQ会重新将该任务添加到队列中。主要体会在消费者
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='10.1.1.3'))
channel = connection.channel()
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
import time
time.sleep(10)
print('ok')
ch.basic_ack(delivery_tag=method.delivery_tag) # 告诉消息队列已经执行完毕
channel.basic_consume(callback,
queue='hello',
no_ack=False)
# 设置no_ack=False,表示消费者在取数据的时候,如果没有返回值说已经取完了,那么还会把该消息放入队列中去
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
注意:这样会在一定程度上降低性能,但是保证的数据的不丢失。
2. durable 持久化
生产者
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='10.211.55.4'))
channel = connection.channel()
# make message persistent
channel.queue_declare(queue='hello', durable=True) # 声明要做持久化
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!',
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent,告诉RabbitMQ要做持久化
))
print(" [x] Sent 'Hello World!'")
connection.close()
消费者
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='10.211.55.4'))
channel = connection.channel()
# make message persistent
channel.queue_declare(queue='hello', durable=True)
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
import time
time.sleep(10)
print('ok')
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(callback,
queue='hello',
no_ack=False)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
注意:如果在生产端配置说做消息的持久化,消费者配置了不丢失。那么,服务器挂掉,数据在了持久化保存;客户端挂了,消息有被重新加到了消息队列当中,在一定程度上保证了数据的可靠性。
3. prefetch_count=1

默认消息队列里的数据是按照顺序被消费者拿走,例如:消费者1 去队列中获取 奇数 序列的任务,消费者2去队列中获取 偶数 序列的任务。channel.basic_qos(prefetch_count=1) 表示谁先来谁取,不再按照奇偶数排列
import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host='10.1.1.3')) channel = connection.channel() # make message persistent channel.queue_declare(queue='hello') def callback(ch, method, properties, body): print(" [x] Received %r" % body) import time time.sleep(10) print('ok') ch.basic_ack(delivery_tag=method.delivery_tag) channel.basic_qos(prefetch_count=1) channel.basic_consume(callback, queue='hello', no_ack=False) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming()
4. 发布和订阅

发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。exchange type = fanout(exchange的默认类型)
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='10.1.1.3')) channel = connection.channel() channel.exchange_declare(exchange='logs', type='fanout') # 创建了exchange,name为'log',类型为'fanout' message = ' '.join(sys.argv[1:]) or "info: Hello World!" channel.basic_publish(exchange='logs', routing_key='', body=message) # 直接把消息发送给exchange print(" [x] Sent %r" % message) connection.close()
import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host='10.1.1.3')) channel = connection.channel() channel.exchange_declare(exchange='logs', type='fanout') # 创建了exchange,name为'log',类型为'fanout' result = channel.queue_declare(exclusive=True) queue_name = result.method.queue # 随机创建队列名 channel.queue_bind(exchange='logs', queue=queue_name) # 把exchange和队列做了一个绑定 print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r" % body) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()
注意:此时订阅端可以启动多个,因为队列名是随机创建而且唯一,启动几次相当于创建几个订阅者,而这几个订阅者都绑定了,同一个队列。所以只要发布端只要发消息,多个订阅者全都能接收到消息。
5. 关键字发送
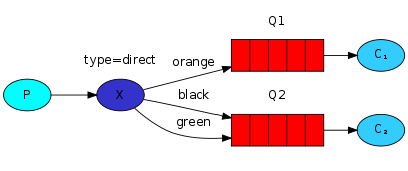
exchange type = direct
之前事例,发送消息时明确指定某个队列并向其中发送消息,RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据,根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='10.1.1.3')) channel = connection.channel() channel.exchange_declare(exchange='direct_logs', type='direct') # 声明类型为direct,即发送关键字 # severity = sys.argv[1] if len(sys.argv) > 1 else 'warning' # message = ' '.join(sys.argv[2:]) or 'Hello World!' severity = 'warning' message = 'hello world!' channel.basic_publish(exchange='direct_logs', routing_key=severity, # 关键字为severity,此时绑定了关键字为warning body=message) print(" [x] Sent %r:%r" % (severity, message)) connection.close()
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='10.1.1.3')) channel = connection.channel() channel.exchange_declare(exchange='direct_logs', type='direct') # 声明类型为direct,即关键字接收 result = channel.queue_declare(exclusive=True) # queue_name = result.method.queue # 这两句为随机创建队列,也可以自己去定义 # severities = sys.argv[1:] # if not severities: # sys.stderr.write("Usage: %s [info] [warning] [error] " % sys.argv[0]) # sys.exit(1) severities = ['warning','error','info'] for severity in severities: channel.queue_bind(exchange='direct_logs', queue=queue_name, routing_key=severity) # 直接接收关键字为severities的消息 print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()
注意:此时的生产者发送的关键字为warning,消费者绑定关键字为warning,error,info。如果再启动一个消费者,绑定的关键字为info,那么此时生产者发送的消息,消费者只有前者能够接收得到。
6,模糊匹配

exchange type = topic
在topic类型下,可以让队列绑定几个模糊的关键字,之后发送者将数据发送到exchange,exchange将传入”路由值“和 ”关键字“进行匹配,匹配成功,则将数据发送到指定队列。
*(星号)可以替换正好一个单词。
#(hash)可以替换零个或多个单词。
注意:这里是RabbitMQ的用法
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='10.1.1.3')) channel = connection.channel() channel.exchange_declare(exchange='topic_logs', type='topic') # 类型为topic # routing_key = sys.argv[1] if len(sys.argv) > 2 else 'anonymous.info' # message = ' '.join(sys.argv[2:]) or 'Hello World!' routing_key = 'www.baidu.com' message = 'hello everybody !' channel.basic_publish(exchange='topic_logs', routing_key=routing_key, body=message) print(" [x] Sent %r:%r" % (routing_key, message)) connection.close()
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='10.1.1.3')) channel = connection.channel() channel.exchange_declare(exchange='topic_logs', type='topic') #要项进行模糊匹配,记住类型为:topic result = channel.queue_declare(exclusive=True) queue_name = result.method.queue # binding_keys = sys.argv[1:] # if not binding_keys: # sys.stderr.write("Usage: %s [binding_key]... " % sys.argv[0]) # sys.exit(1) binding_keys = ['www.*.#', "hello.*" ] # 用 '*' 和 '#' 进行关键字的模糊匹配 for binding_key in binding_keys: channel.queue_bind(exchange='topic_logs', queue=queue_name, routing_key=binding_key) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming() # 收消息
注意:此时客户端发送www.baidu.com,消费者端在进行模糊匹配的时候就可以匹配得到。
ZeroMQ是基于内存级别,速度比RabbitMQ快,saltstack用的就是ZeroMQ,openstack中用的是RabbitMQ
7. rpc
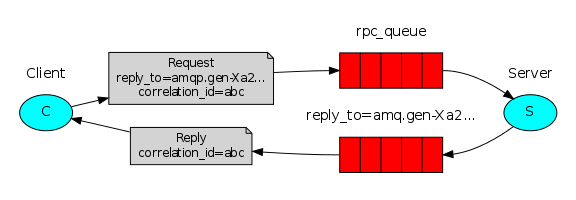
RPC(Remote Procedure Call Protocol)——远程过程调用协议。
和前面不同的是前面,前面是工作队列在多个工作线程间分配耗时的任务。也就是说一个发消息,一个收消息。而RPC是在远程主机上,运行一个函数并等待结果!
RPC原理简单点说,假设这是一个saltstack的master和三个saltstack的minion,master端要执行命令cmd,这时minion端过来取任务,然后拿到minion端去执行,注意这时minion端拿到的既有cmd命令,也有master端生成的以md5命名的队列。minion端执行完任务之后把结果返回给master端的队列md5,然后master端从队列里面取出返回的结果,输出到客户端,然后删除队列。
#!/usr/bin/env python import pika import uuid class FibonacciRpcClient(object): def __init__(self): self.connection = pika.BlockingConnection(pika.ConnectionParameters( host='10.1.1.3')) # 连接服务器端 self.channel = self.connection.channel() # 建立频道 result = self.channel.queue_declare(exclusive=True) # self.callback_queue = result.method.queue # 随机生成一个队列 self.channel.basic_consume(self.on_response, no_ack=True, # 只要一收到消息就调用on_response queue=self.callback_queue) # 提前声明要从self.callback_que这个队列中收数据 def on_response(self, ch, method, props, body): if self.corr_id == props.correlation_id: # 在客户端接收服务端返回值的时候首先检查UUID值是否为自己生成的UUID,从而确定是否为自己请求的返回值 self.response = body def call(self, n): self.response = None self.corr_id = str(uuid.uuid4()) # 随机生成一个唯一的UUID编码 self.channel.basic_publish(exchange='', routing_key='rpc_queue', # 要发出数据的队列 properties=pika.BasicProperties( reply_to=self.callback_queue, # 设置回调队列为上面生成的随机队列 correlation_id=self.corr_id, # 为每个请求设置唯一值 ), body=str(n)) # 客户端发送的内容包括:路由值(routing_key),随机生成的那个队列,以及随机生成的UUID编码 while self.response is None: self.connection.process_data_events() # 非阻塞版的start_consuming() return int(self.response) fibonacci_rpc = FibonacciRpcClient() print(" [x] Requesting fib(30)") response = fibonacci_rpc.call(6) print(" [.] Got %r" % response)
#!/usr/bin/env python import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host='10.1.1.3')) channel = connection.channel() channel.queue_declare(queue='rpc_queue') def fib(n): # 计算斐波那契值的函数 if n == 0: return 0 elif n == 1: return 1 else: return fib(n-1) + fib(n-2) def on_request(ch, method, props, body): n = int(body) print(" [.] fib(%s)" % n) response = fib(n) ch.basic_publish(exchange='', routing_key=props.reply_to, # 发送数据给客户端设置的随机生成的那个随机队列。 properties=pika.BasicProperties(correlation_id = props.correlation_id), body=str(response)) # 服务端回应客户端的信息包括: 队列(路由值), 客户端发送过来的UUID,计算出斐波那契值 ch.basic_ack(delivery_tag = method.delivery_tag) # 确认已经接收完毕了 channel.basic_qos(prefetch_count=1) # 规定谁先来,谁取 channel.basic_consume(on_request, queue='rpc_queue') print(" [x] Awaiting RPC requests") channel.start_consuming()
上例RPC会这样工作:
1,当客户端启动时,它创建一个匿名独占回调队列。
2,对于RPC请求,客户端发送具有两个属性的消息: reply_to(设置为回调队列)和correlation_id(为每个请求设置唯一值)。
3,请求被发送到rpc_queue队列。
4,RPC工作程序(又名:服务器)正在等待该队列上的请求。当出现请求时,它执行作业,并使用reply_to字段中的队列将带有结果的消息发送回客户端。
5,客户端等待回调队列上的数据。当出现消息时,它将检查correlation_id属性。如果它匹配来自请求的值,则它将响应返回到应用程序。
在进行上述求斐波那契函数的值时需要注意以下几点:
消息属性(properties)
AMQP协议预定义了一组包含消息的14个属性。大多数属性很少使用,除了以下:
delivery_mode:将消息标记为persistent(值为2)或transient(任何其他值)。
content_type:用于描述编码的mime类型。例如对于经常使用的JSON编码,一个好的做法是将此属性设置为:application / json。
reply_to:常用于命名回调队列。
correlation_id:用于将RPC响应与请求相关联