格式化输出
print("This is %s" % "test") # This is test
print("%s , %d , %s" % ('a', 12, 'b')) # a , 12 , b
print('3%% %s' % "abc") # 显示%号
str_ = '''
a b c d %s
a b c %s
a b %s
a %s
%s
''' % ("e", "d", "c", "b", "a")
# a b c d e
# a b c d
# a b c
# a b
# a
# format() 输出
# 位置显示
'a1 ={}, a2={}, a3={}'.format("1", "2", "3") # a1 =1, a2=2, a3=3
'a1 ={1}, a2={2}, a3={0}'.format("1", "2", "3") # a1 =2, a2=3, a3=1
"Your name is{name}, age is {age}".format(name="A", age=12) # Your name isA, age is 12
"Your name is{name}, age is {age}".format(age=12, name="A") # Your name isA, age is 12 和位置无关
# 对象的的属性
class A:
def __init__(self, name, age): # 构造函数
self.name = name
self.age = age
```
P = A("B", 18)
"name is: {p.name}, age is:{p.age}".format(p=P) # name is: B, age is:18
```
# 通过下标
s1 = [1, "23", "S"]
s2 = ["s2.1", "s2.2", "s2.3"]
'{0[1]} {0[2]} {1[2]} {1[0]}'.format(s2, s1) # s2.2 s2.3 S 1
# 格式化输出
a = '[{:<10}]'.format('12') # 默认填充空格的 输出左对齐定长为10位 [12 ]
b = "[{:>10}]".format("abc") # 默认填充空格的 输出左对齐定长为10位 [ abc]
c = "[{:*>10}]".format("abc") # 输出左对齐定长为10位 填入一个ascii字符 [*******abc]
d = "[{:*<10}]".format("abc") # 输出右对齐定长为10位 填入一个ascii字符 [abc*******]
e = "[{:*^10}]".format("abc") # 输出居中对其为10位 填入一个ascii字符 [***abc****]
# 浮点小数输出
import math
a1 = "{:.6f}".format(math.pi) # 3.141593 通常都是配合 f 使用,其中.2表示长度为2的精度,f表示float类型
a2 = "{:,}".format(12345945852326.1524512345) # 12,345,945,852,326.152
# 进制及其他显示
```
'''
```
b : 二进制
d :十进制
o :八进制
!s :将对象格式化转换成字符串
!a :将对象格式化转换成ASCII
!r :将对象格式化转换成repr
'''
b1 = '{:b}'.format(10) #二进制 :1010
b2 = '{:d}'.format(10) # 10进制 :10
b3 = '{:o}'.format(45) # 8进制 :55
b4 = '{:x}'.format(45) # 16进制 :2d
b5 = '{!s}'.format('45') # 45
b6 = "{!a}".format("10") # '10'
b7 = "{!r}".format("10") # '10'
print(b7)
while循环
while 语句用于循环执行程序,即在某条件下,循环执行某段程序,以处理需要重复处理的相同任务,例如输入账号,密码等。
while循环的基本结构:
[初始化部分一般是用来定义循环变量]
while 循环条件:
循环体语句
[循环变量更改部分]
[else :
语句体]
执行的顺序:
1. 初始化部分:一般是用来定义循环变量或新赋值
2. 判断循环条件:
真:
执行循环体语句
是否执行了break语句
执行了:跳过else
没执行:当while正常执行完后,执行else
回到第二步条件判断
假:执行else
break:停止:直接停止当前的循环,不论还剩下多少次循环。
continue:跳过当前循环后面的语句,直接执行下一轮循环。
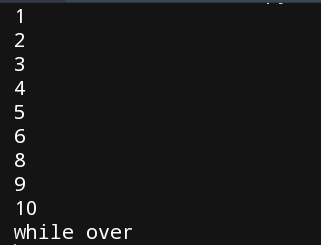
测试
i = 0
while i < 10:
i += 1
if i == 7:
continue
print(i)
else:
print("while over")
结果:
运算符
算术运算符(arithmetic operator)###
以下假设变量: a=10,b=20:
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 - 两个对象相加 | a + b 输出结果 30 |
| - | 减 - 得到负数或是一个数减去另一个数 | a - b 输出结果 -10 |
| * | 乘 - 两个数相乘或是返回一个被重复若干次的字符串 | a * b 输出结果 200 |
| / | 除 - x除以y | b / a 输出结果 2 |
| % | 取模 - 返回除法的余数 | b % a 输出结果 0 |
| ** | 幂 - 返回x的y次幂 | a**b 为10的20次方, 输出结果 100000000000000000000 |
| // | 取整除 - 返回商的整数部分(向下取整) | 9//2= 4 -9//2= -5 |
取模操作
% : 取余,取模。取的是第一个操作数和第二个操作数除法的余数。整除结果为0.
10 % 3 1
10 % 5 0
10 % -3 -1
10 % -5 ?
-10%3 ?
% 真正操作步骤:
- 用第一个数除以第二个数,得到最相近的两个商。取最小的数。
- 用第一个数减去第二个数和第一步的到的数的乘积。
10 % -5 # 0
-10%3 # 1:则两个数为-4,-3,取最小的那个数,则是-4;
# 2:-10-(3*-4)= 2 则余数为2
赋值运算符(assignment operator)
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
逻辑运算符(logic operator)
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔"与" - 如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值。 | (a and b) 返回 20。 |
| or | x or y | 布尔"或" - 如果 x 是非 0,它返回 x 的值,否则它返回 y 的计算值。 | (a or b) 返回 10。 |
| not | not x | 布尔"非" - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not(a and b) 返回 False |
逻辑运算符的结果到底是什么类型???
结果取决于两个操作数的类型!!!
针对and操作:第一个操作数如果是可以转成False的话,那么第一个操作数的值,就是整个逻辑表达式的值。
如果第一个操作数可以转成True,第二个操作数的值就是整个表达式的值。
针对or操作:第一个操作数如果是可以转成False的话,第二个操作数的值就是整个表达式的值。
如果第一个操作数可以转成True, 第一个操作数的值,就是整个逻辑表达式的值。
1)1 > 1 or 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6 # True
2)not 2 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6 # False
3) 8 or 3 and 4 or 2 and 0 or 9 and 7 # 8
4) 0 or 2 and 3 and 4 or 6 and 0 or 3 # 4
5) 6 or 2 > 1 # 6
6) 5 < 4 or 3 # 3
7) 2 > 1 or 6 # True
8) 3 and 2 > 1 #True
9) 0 and 3 > 1 # 0
10) 2 > 1 and 3 # 3
11) 3 > 1 and 0 # 0
12) 3 > 1 and 2 or 2 < 3 and 3 and 4 or 3 > 2 # 2
成员运算
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 | x 在 y 序列中 , 如果 x 在 y 序列中返回 True。 |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。 |
编码的初始
字符编码
ASCII
最早的计算机是采用在设计的时候采用了8个比特(bit),一个字节一个字节能表示的最大的整数就是255(11111111 二进制),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
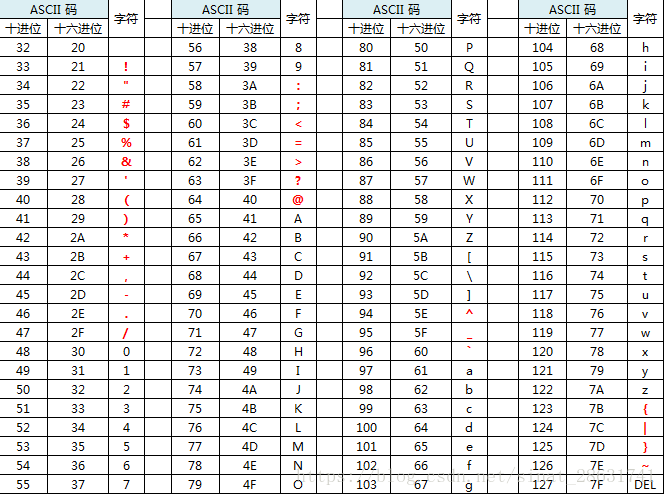
早期,计算机的编码只有127个字符被编码到计算机里,其就是大小为英文、数字、和一些符号。这个编码则被称为ASCII码,早期的ascii都是7位一段,但是为了以后的发展,拓展了一位,具体的ASCII码如下所示:
但是相对于中国的汉字,有91251个,但是常用字只有3000个左右,其他都是生僻字。两个字节就可以满足我们的日常的需求了(2字节=65536),为了不和ASCII进行冲突,中国就制定了GBK:GB2312编码,将中文进行编码。
**Unicode **
Unicode(万国码)把所有语言都统一到一套编码里。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
ASCII编码和Unicode编码的区别:
子母a用ASCII编码的十进制97,二进制是01100001
特别注意的是:数字0和子母o的编码是不一样的。
汉字杨已经超出了ASCII编码的范围,用Unicode编码是十进制的26472,二进制的01100111 01101000
UTF_8
问题出现了,当美国的作者写文章的时候,如果使用Unicode编码,要比使用ASCII编码多出一倍的存储空间,导致资源上的浪费。
在这种情况下,就出现了也为节约为目的,将Unicode编码转换为'可变长编码'的utf-8,UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间.
| 字符 | ASCII | Unicode | utf-8 |
|---|---|---|---|
| 'a' | 01100001 | 00000000 01100001 | 01100001 |
| '杨' | ----------- | 0110011101101000 | 11100110 10011101 10101000 |
python3,是也unicode进行编码的。
测试:
>>> print("杨") # unicode编码
杨
>>> ord("a") # 转化为10进制
97
>>> bin(97) # 转换为2进制
'0b1100001'
>>> chr(97) # 数字转换为字符(ASCII)
'a'
>>> chr(26472)
'杨
在unicode编码中,可以使用encode转换到其他的编码;
data = '杨'
a = data.encode(encoding='utf-8')
print(a) # b'xe6x9dxa8'