现在很火的微服务架构所设计的系统是分布式系统。分布式系统有一个著名的CAP理论,即一个分布式系统要同时满足一致性(Consistency)、可用性(Availablility)和分区容错(Partition Tolerance)三个特性是一件不可能的事情。
CAP理论的简介
CAP理论是由Eric Brewer在2000年的PODC会议上提出的,该理论在两年后被证明成立。
CAP理论告诉架构师不要妄想设计出同时满足三者的系统,应该有所取舍,设计出适合业务的系统。
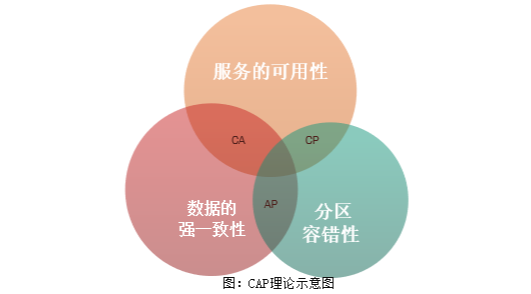
一致性(Consistency):一致性指的是数据的强一致性。每次的读操作都是读取的最新数据。即如果写入某个数据成功的话,之后的读取都应该读的是新写入的数据;如果写入失败的话,之后读取的都不应该是写入失败的数据。
可用性(Availability):可用性指的是服务的可用性。即每个请求都能在合理的时间内获得符合预期的响应结果。
分区容错性(Partition Tolerance):分区容错性指的是当节点之间的网络出现问题之后,系统仍然能够正常提供服务。
在分布式的系统中,P是基本要求,而单体应用则是CA系统。微服务系统通常是一个AP系统,即同时满足可用性和分区容错性。这样就有了一个在分布式系统中保证数据强一致性的难题,这个难题的一个解决方案就是分布式事务。
分布式事务的解决方案
在微服务系统中,每个服务都是独立的进程单元,每个服务都有自己的数据库。在通常情况下,只有关系型数据库在特定的数据引擎下才会支持事务(本地事务),而大多数非关系型数据库是不支持事务的,比如MongDB完全不支持事务,而Redis是支持事务的,虽然支持得不完整。
两阶段提交
网上购物在日常生活中是一个非常普通的场景,假设静静在某宝上购买了一个玩具,需要从静静的账户中扣除200块钱,同时玩具的库存数量需要减1,卖家的账户中增加200块钱。
如果这是一个单体应用,并且使用支持事务的数据库(比如InnoDB数据库引擎的MySQL、Oracle和SQL Server等),我们可能是这样写代码的:
@Transactional public void update() throws RuntimeException{ updateAccountTable(); // 更新账户表 updateGoodsTable(); // 更新商品表 }
如果是微服务架构的话,账户是一个服务,商品是一个服务,两个独立的服务就不能使用数据库自带的事务了,因为这两个数据表可能并不在一个数据库中,这就需要用到两阶段提交的解决方案。
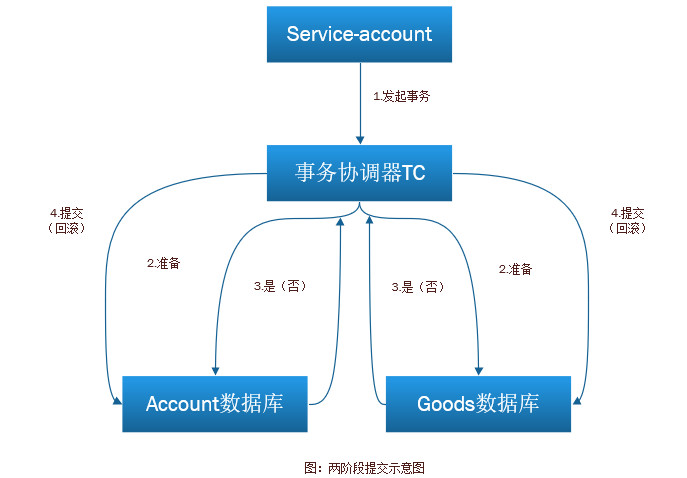
第一阶段,service-account发起一个分布式事务,交给事务式事务TC处理,事务协调器TC向所有参与事务的节点发送处理事务操作的准备操作。所有参与节点执行准备操作,将Undo和Redo信息写入日志中,并向事务管理器返回准备操作是否成功的消息。
第二阶段,事务管理器收集所有节点的准备操作是否都成功,如果都成功的话则通知所有的节点执行提交操作,如果有一个失败则执行回滚操作。
两阶段提交将事务分成了两个部分,大大提高了分布式事务的成功概率。然而,如果在第一阶段都成功了,而执行第二阶段的某一个节点失败,仍然会导致数据不准确。这种情况下一般需要人工去处理,这也是为什么要在第一步记录日志的原因。
另外,如果分布式事务涉及的节点很多,一旦某一个节点的网络出现异常,就会导致整个事务处于阻塞状态,大大降低数据库的性能。因此如果不是必要的话,建议是尽量少用分布式事务,有些时候过度设计反而会造成相反的效果。
三阶段提交
三阶段提交在两阶段提交的步骤中间加了一层预提交事务阶段。
1.CanCommit阶段。这个阶段和上面说的两阶段提交的准备阶段类似,不同的地方就是并没有进行诸如将Undo和Redo的信息写入事务日志的其他操作。
2.PreCommit阶段。这个阶段是一个缓冲,目的是推迟Commit的决定,只有保证所有参与者都知道了Commit的决定之后,才会真正发出Commit的决定。所有的参与者都会在这个阶段记录Undo和Redo的信息,并且当协调者发生故障之后,所有的参与者还能互相通信来确定事务是提交还是终止。
3.DoCommit阶段。这个阶段就是事务的真正提交,如果所有的参与者都向协调者发送了ACK响应,那么协调者就会完成事务,否则中断事务。

三阶段提交的方案引入了对参与者的超时机制,相比于两阶段提交只有协调者拥有超时的机制,三阶段提交解决了协调者突然挂掉引起的参与者一直阻塞的问题。
本质上来说,三阶段提交避免了状态停滞的问题。在两阶段提交的过程中有可能会因为各种原因产生状态停滞的问题,最明显的就是协调者突然宕机的情况。但是三阶段提交即使是协调者宕机也会让状态继续下去,参与者们也会互相通信确定事务是提交还是终止,从而使状态继续下去,哪怕状态是错的。
"在心碎中认清遗憾,生命漫长也短暂。"