一、基础
HashMap不是线程安全的,JDK1.8之前是头插法,多线程扩容可能出现循环链
HashMap只能有一个Null键,可以有多个Null值
HashMap在JDK1.8之前由数组+链表构成,1.8之后,如果当前数组的长度不小于 64(小于则扩容),并且当链表长度大于等于阈值(默认为8)时,将链表转化为红黑树,如果红黑树元素个数小于等于6时,重新转化为链表
HashMap扩容负载因子默认0.75
二、构造方法
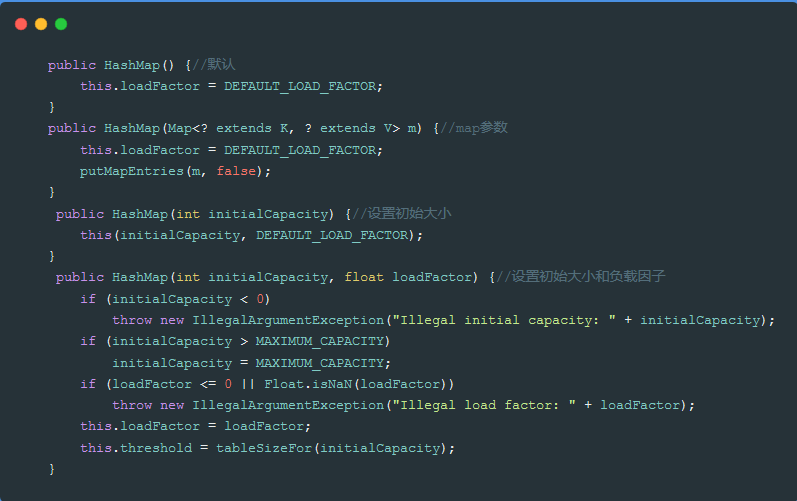
三、HashMap的扩容
默认情况下,数组大小为16,扩容负载因子默认0.75,当HashMap中元素个数超过16*0.75=12时,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作。所以如果我们已经预知hashmap中元素的个数,最好设置数组的初始大小,初始大小设置为大于(已知元素个数/0.75)的最小的2的倍数。
四、头插法、多线程、扩容时循环链的形成
JDK1.8之前,HashMap的插入是用的头插法(避免尾部遍历效率高),所以在扩容时,依然在同一链表的元素的次序会反过来。那么在多线程情况下,线程一正在使用之前的顺序遍历链表,然后线程切换,线程二进行扩容,导致链表顺序倒置,再切换为线程一,遍历链表取值的时候就发生了循环,就会在get()时占满cpu。
五、JDK1.8的扩容
优化了效率,不是单纯的rehash():
1、通过增加tail指针(记录新旧链表的头部和尾部位置),可以让数据直接插入到队尾,避免了尾部遍历。同时不会出现链表倒置现象,避免了死循环问题。
2、hash 值本来就是随机性的,让hash值 按位与 newTable 得到的 0和 1,0就保持原hashmap数组位置,1的位置就是扩容前索引位置加上扩容前数组长度的数值,所以扩容的过程就能把之前哈希冲突的元素再随机的分布到不同的索引去,这也算是 JDK1.8 的一个优化点