Tesseract-ocr可以OCR识别藏文、梵文,识别为Unicode字符,效果还不错
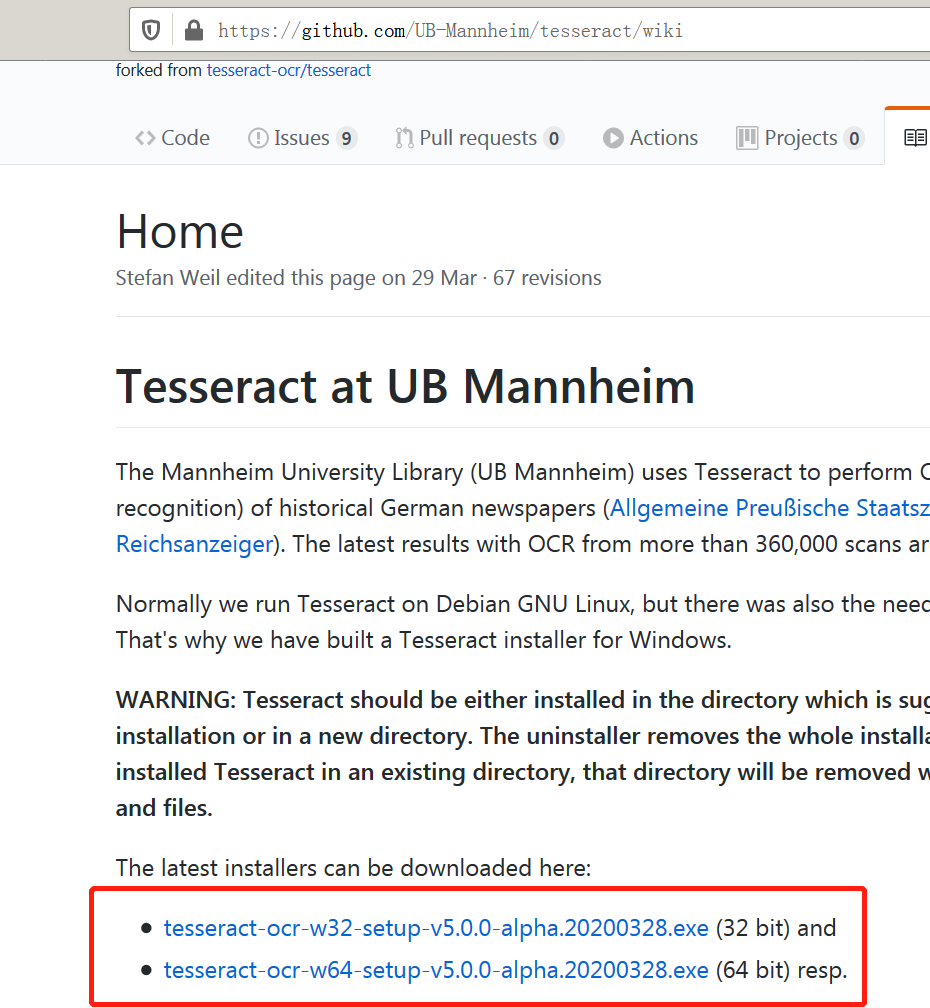
1、下载Windows安装版
Windows安装版地址:
https://github.com/UB-Mannheim/tesseract/wiki
所有版本下载地址:
https://digi.bib.uni-mannheim.de/tesseract/
推荐使用5.0版本,4.0版本支持API,编程需要4.0版本。
2、下载识别文件包
https://tesseract-ocr.github.io/tessdoc/Data-Files
有普通、best、fast三种模式可选,下载相应traineddata数据。可以下载4.0的数据。
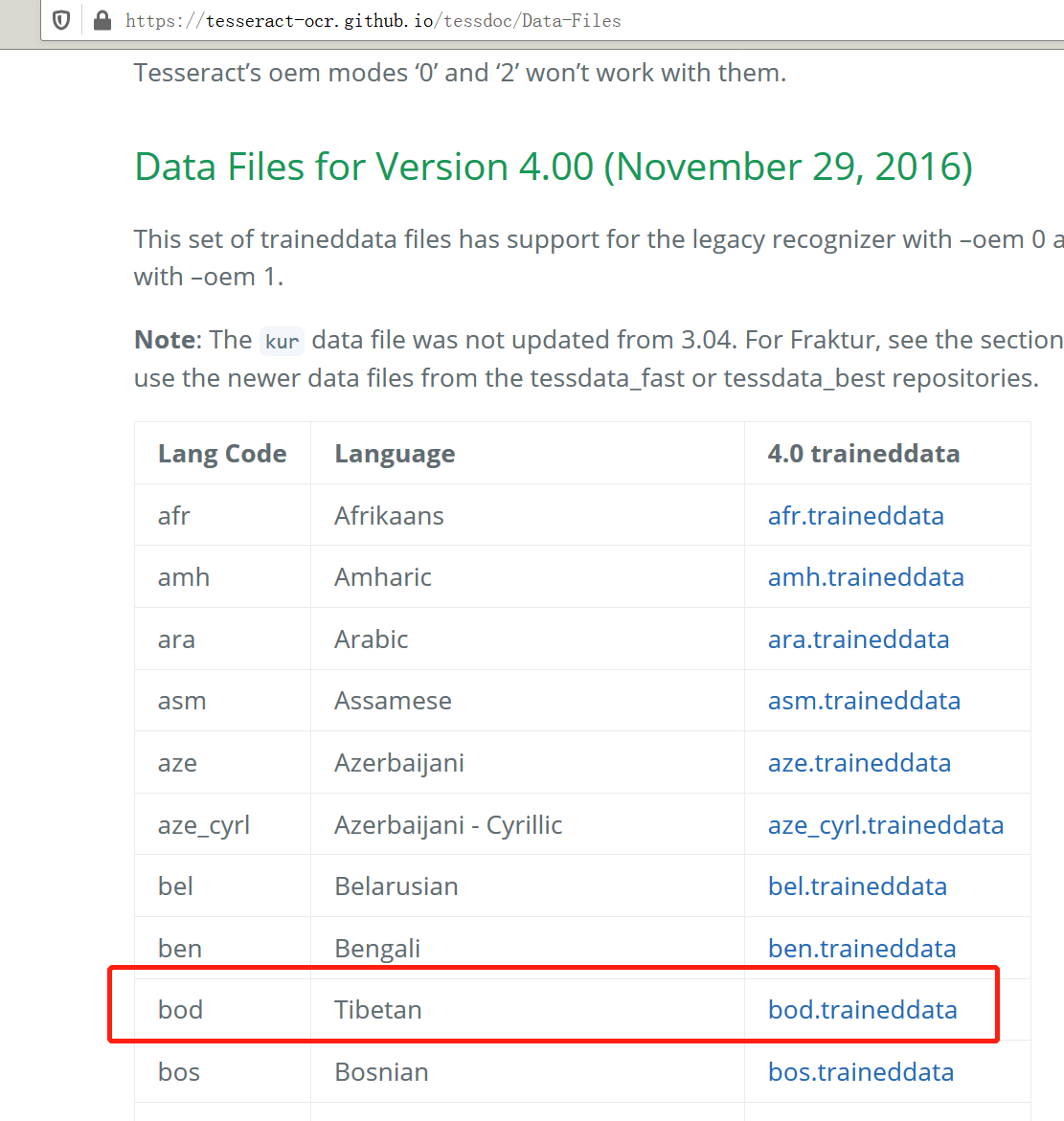
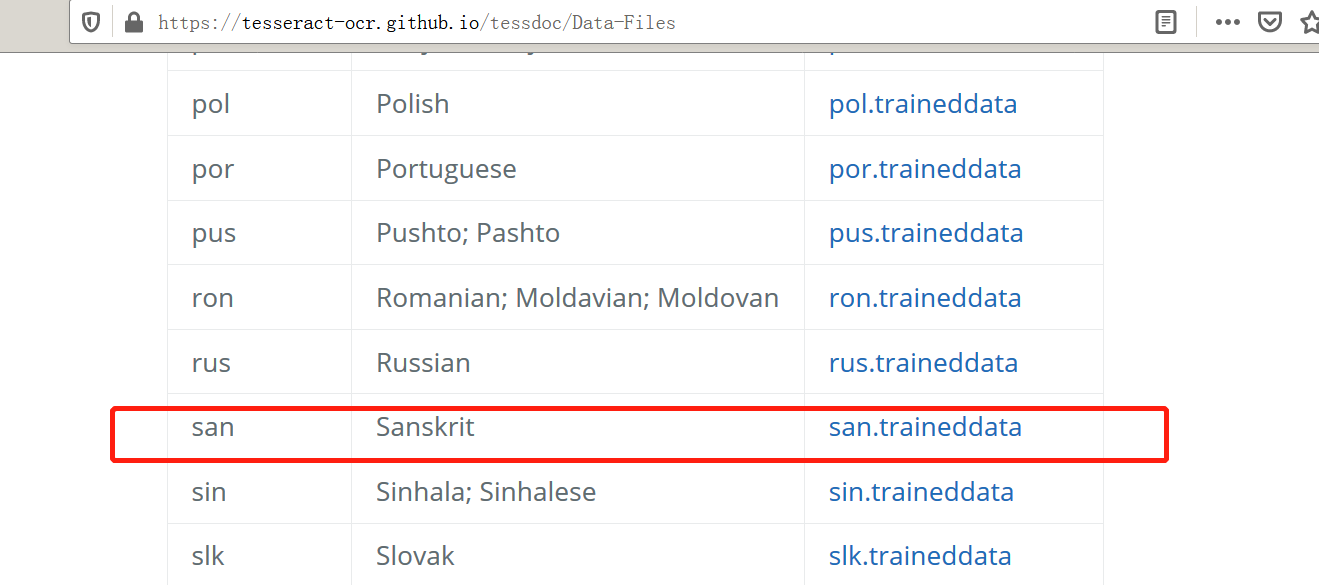
还有很多其他语言,可以去探索。
注:汉语、日语、韩语等语言,Finereader的OCR效果要比Tesseract-ocr强很多,但是Finereader是收费的。西方语言还可以选用OmniPage,但是OmniPage也是收费的。网上有破解版,但是现在越来越不少找了。
3、配置TESSDATA_PREFIX变量
参考网页:https://blog.csdn.net/weixin_41982136/article/details/82747499
如将traineddata拷贝至C:Program FilesTesseract-OCR essdata,则将TESSDATA_PREFIX设置为C:Program FilesTesseract-OCR essdata

4、在命令行下使用

参考网页:
https://tesseract-ocr.github.io/tessdoc/Command-Line-Usage.html
识别藏文
tesseract 藏文图片 保存地址 -l bod
识别梵文
tesseract 梵文图片 保存地址 -l san
cmd示例:
进入安装目录
cd C:Program FilesTesseract-OCR
测试语言安装是否正确,有哪些训练语言
tesseract --list-langs
识别一张图片
tesseract tib_001.jpg D: ib_001 -l bod
经测试,识别铅字印刷的图片,效果还可以。
经过优化处理的图片,可以显著提高识别率,参见:
https://tesseract-ocr.github.io/tessdoc/ImproveQuality.html
处理图片推荐使用老马软件ComicEnhancerPro。
老马的博客地址:https://www.cnblogs.com/stronghorse/