1. torch.nn.RNNCell
用于定义循环神经网络的一个 Cell,网络结构图如下所示:

右侧是这个网络的工作过程,都是同一个 RNN Cell(不是定义多个的意思),每个 Cell 内部就是一个全连接的神经网络。函数原型如下:
""" input_size – 输入层输入的特征向量维度 hidden_size – 隐藏层输出的特征向量维度 bias – bool 类型,如果是 False,那么不提供偏置, 默认为 True nonlinearity – 字符串类型,进行激活函数选择,可以是 'tanh' 或 'relu'. 默认为 'tanh' """ class torch.nn.RNNCell(input_size, hidden_size, bias, nonlinearity)
调用的时候需要提供两个参数,一个是上一次的隐藏层输出 $h_{t-1}$,另一个是这一次的输入 $x_t$,它们形状的第一个维度是 batchSize。
使用 nn.RNNCell 来定义 RNN 的话就需要自己写循环函数,举个例子:
import torch
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)
dataset = torch.randn(seq_len, batch_size, input_size)
hidden = torch.zeros(batch_size, hidden_size) # 先把 h0 置为 0 向量
for idx, input in enumerate(dataset):
print('=' * 20, idx, '=' * 20)
print('Input size:', input.shape)
hidden = cell(input, hidden)
print('Outputs size:', hidden.shape)
print(hidden)
"""
==================== 0 ====================
Input size: torch.Size([1, 4])
Outputs size: torch.Size([1, 2])
tensor([[ 0.8961, -0.5659]], grad_fn=<TanhBackward>)
==================== 1 ====================
Input size: torch.Size([1, 4])
Outputs size: torch.Size([1, 2])
tensor([[ 0.7983, -0.9240]], grad_fn=<TanhBackward>)
==================== 2 ====================
Input size: torch.Size([1, 4])
Outputs size: torch.Size([1, 2])
tensor([[-0.9468, -0.2731]], grad_fn=<TanhBackward>)
"""
2. torch.nn.RNN
用于定义多层循环神经网络,网络结构图如下:
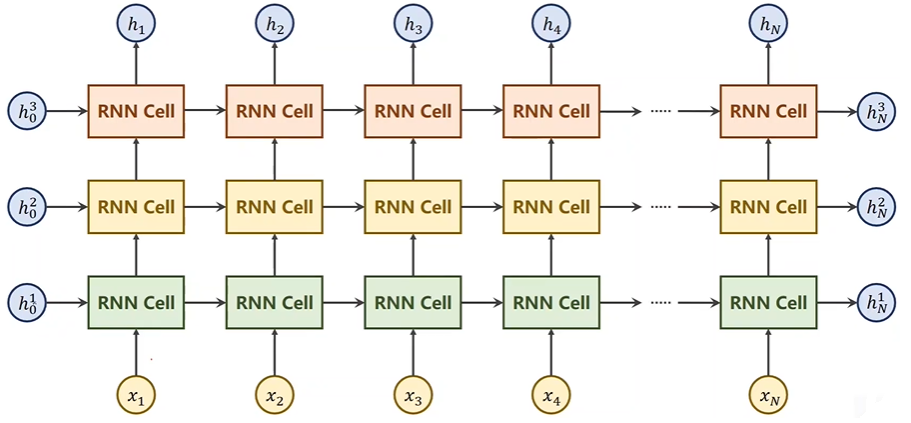
函数原型如下:
""" input_size - 输入特征的维度 hidden_size - 隐藏层神经元个数,或者也叫输出的维度 num_layers - 网络的层数,或者说是隐藏层的层数 nonlinearity - 激活函数,默认为 tanh bias - 是否使用偏置 """ class torch.nn.RNN(input_size, hidden_size, num_layers=1, nonlinearity=tanh, bias=True)
举个例子:
import torch
seq_len = 3
batch_size = 2
input_size = 4
hidden_size = 3
num_layers = 1
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers)
inputs = torch.randn(seq_len, batch_size, input_size)
hidden = torch.zeros(num_layers, batch_size, hidden_size)
"""
各个变量的形状如下:
inputs: (seq_len, batch_size, input_size)
hidden: (num_layers, batch_size, hidden_size)
outputs: (seq_len, batch_size, hidden_size)
hiddens: (num_layers, batch_size, hidden_size)
"""
outputs, hiddens = cell(inputs, hidden)
print('Output size:', outputs.shape)
print('Output:', outputs)
print('Hidden size:', hiddens.shape)
print('Hidden', hiddens)
"""
Output size: torch.Size([3, 2, 3])
Output: tensor([[[-0.9422, 0.5505, -0.8300],
[-0.5703, 0.6713, -0.3232]],
[[-0.8878, -0.7763, -0.8536],
[-0.9227, -0.9407, -0.7844]],
[[-0.8496, -0.3460, -0.1831],
[-0.6766, -0.6941, -0.0992]]], grad_fn=<StackBackward>)
Hidden size: torch.Size([1, 2, 3])
Hidden: tensor([[[-0.8496, -0.3460, -0.1831],
[-0.6766, -0.6941, -0.0992]]], grad_fn=<StackBackward>)
"""