声明:师从老男孩太白金星,不对代码做任何保证,如有问题请自携兵刃直奔沙河
前两天咱们已经讲了编码,我相信大家对编码有一定的了解了,那么,咱们先回顾一下:
首先来说,编码即是密码本,编码记录的就是二进制与文字之间的对应关系,现存的编码本有:
ASCII码:包含英文字母,数字,特殊字符与01010101对应关系。
a 01000001 一个字符一个字节表示。
GBK:只包含本国文字(以及英文字母,数字,特殊字符)与0101010对应关系。
a 01000001 ascii码中的字符:一个字符一个字节表示。
中 01001001 01000010 中文:一个字符两个字节表示。
Unicode:包含全世界所有的文字与二进制0101001的对应关系。
a 01000001 01000010 01000011 00000001
b 01000001 01000010 01100011 00000001
中 01001001 01000010 01100011 00000001
UTF-8:包含全世界所有的文字与二进制0101001的对应关系(最少用8位一个字节表示一个字符)。
a 01000001 ascii码中的字符:一个字符一个字节表示。
To 01000001 01000010 (欧洲文字:葡萄牙,西班牙等)一个字符两个字节表示。
中 01001001 01000010 01100011 亚洲文字;一个字符三个字节表示。
简单回顾完编码之后,再给大家普及一些知识点:
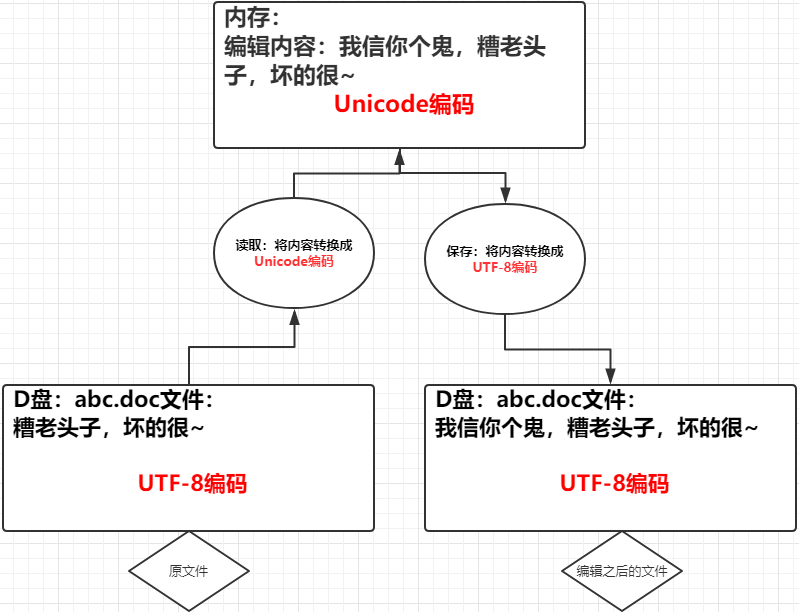
1. 在计算机内存中,统一使用Unicode编码,当需要将数据保存到硬盘或者需要网络传输的时候,就转换为非Unicode编码比如:UTF-8编码。
其实这个不用深入理解,他就是规定,举个例子:用文件编辑器(word,wps,等)编辑文件的时候,从文件将你的数据(此时你的数据是非Unicode(可能是UTF-8,也可能是gbk,这个编码取决于你的编辑器设置))字符被转换为Unicode字符读到内存里,进行相应的编辑,编辑完成后,保存的时候再把Unicode转换为非Unicode(UTF-8,GBK 等)保存到文件。
2. 不同编码之间,不能直接互相识别。
比如你的一个数据:‘老铁没毛病’是以utf-8的编码方式编码并发送给一个朋友,那么你发送的肯定是通过utf-8的编码转化成的二进制01010101,那么你的朋友接收到你发的这个数据,他如果想查看这个数据必须将01010101转化成汉字,才可以查看,那么此时那也必须通过utf-8编码反转回去,如果要是通过gbk编码反转,那么这个内容可能会出现乱码或者报错。
那么了解完这两点之后,咱们开始进入编码进阶的最重要的内容。
前提条件:python3x版本(python2x版本与这个不同)。
主要用途:数据的存储或者传输。
刚才咱们也说过了,在计算机内存中,统一使用Unicode编码,当需要将数据保存到硬盘或者需要网络传输的时候,就转换为非Unicode编码比如:UTF-8编码。
咱们就以网络传输为例:
好那么接下来咱们继续讨论,首先先声明一个知识点就是这里所说的'数据',这个数据,其实准确的说是以字符串(特殊的字符串)类型的数据。那么有同学就会问到,python中的数据类型很多,int bool list dict str等等,如果我想将一个列表数据通过网络传输给小明同学,不行么? 确切的说不行,你必须将这个列表转化成一个特殊的字符串类型,然后才可以传输出去,数据的存储也是如此。
那么你就清楚一些了,你想通过存储或者网络传输的数据是一个特殊的字符串类型,那么我就直接将这个字符串传出去不就行了么?比如我这有一个数据:'今晚10点吃鸡,大吉大利' 这不就是字符串类型么?我直接将这个数据通过网络发送给小明不就可以了么?不行。这里你还没有看清一个问题,就是特殊的字符串。为什么?

那么这个解决方式是什么呢?

那么这个bytes类型是个什么类型呢?其实他也是Python基础数据类型之一:bytes类型。
这个bytes类型与字符串类型,几乎一模一样,可以看看bytes类型的源码,bytes类型可以用的操作方法与str相差无几.
class bytes(object):
"""
bytes(iterable_of_ints) -> bytes
bytes(string, encoding[, errors]) -> bytes
bytes(bytes_or_buffer) -> immutable copy of bytes_or_buffer
bytes(int) -> bytes object of size given by the parameter initialized with null bytes
bytes() -> empty bytes object
Construct an immutable array of bytes from:
- an iterable yielding integers in range(256)
- a text string encoded using the specified encoding
- any object implementing the buffer API.
- an integer
"""
def capitalize(self): # real signature unknown; restored from __doc__
"""
B.capitalize() -> copy of B
Return a copy of B with only its first character capitalized (ASCII)
and the rest lower-cased.
"""
pass
def center(self, width, fillchar=None): # real signature unknown; restored from __doc__
"""
B.center(width[, fillchar]) -> copy of B
Return B centered in a string of length width. Padding is
done using the specified fill character (default is a space).
"""
pass
def count(self, sub, start=None, end=None): # real signature unknown; restored from __doc__
"""
B.count(sub[, start[, end]]) -> int
Return the number of non-overlapping occurrences of subsection sub in
bytes B[start:end]. Optional arguments start and end are interpreted
as in slice notation.
"""
return 0
def decode(self, *args, **kwargs): # real signature unknown
"""
Decode the bytes using the codec registered for encoding.
encoding
The encoding with which to decode the bytes.
errors
The error handling scheme to use for the handling of decoding errors.
The default is 'strict' meaning that decoding errors raise a
UnicodeDecodeError. Other possible values are 'ignore' and 'replace'
as well as any other name registered with codecs.register_error that
can handle UnicodeDecodeErrors.
"""
pass
def endswith(self, suffix, start=None, end=None): # real signature unknown; restored from __doc__
"""
B.endswith(suffix[, start[, end]]) -> bool
Return True if B ends with the specified suffix, False otherwise.
With optional start, test B beginning at that position.
With optional end, stop comparing B at that position.
suffix can also be a tuple of bytes to try.
"""
return False
def expandtabs(self, tabsize=8): # real signature unknown; restored from __doc__
"""
B.expandtabs(tabsize=8) -> copy of B
Return a copy of B where all tab characters are expanded using spaces.
If tabsize is not given, a tab size of 8 characters is assumed.
"""
pass
def find(self, sub, start=None, end=None): # real signature unknown; restored from __doc__
"""
B.find(sub[, start[, end]]) -> int
Return the lowest index in B where subsection sub is found,
such that sub is contained within B[start,end]. Optional
arguments start and end are interpreted as in slice notation.
Return -1 on failure.
"""
return 0
@classmethod # known case
def fromhex(cls, *args, **kwargs): # real signature unknown; NOTE: unreliably restored from __doc__
"""
Create a bytes object from a string of hexadecimal numbers.
Spaces between two numbers are accepted.
Example: bytes.fromhex('B9 01EF') -> b'\xb9\x01\xef'.
"""
pass
def hex(self): # real signature unknown; restored from __doc__
"""
B.hex() -> string
Create a string of hexadecimal numbers from a bytes object.
Example: b'xb9x01xef'.hex() -> 'b901ef'.
"""
return ""
def index(self, sub, start=None, end=None): # real signature unknown; restored from __doc__
"""
B.index(sub[, start[, end]]) -> int
Return the lowest index in B where subsection sub is found,
such that sub is contained within B[start,end]. Optional
arguments start and end are interpreted as in slice notation.
Raises ValueError when the subsection is not found.
"""
return 0
def isalnum(self): # real signature unknown; restored from __doc__
"""
B.isalnum() -> bool
Return True if all characters in B are alphanumeric
and there is at least one character in B, False otherwise.
"""
return False
def isalpha(self): # real signature unknown; restored from __doc__
"""
B.isalpha() -> bool
Return True if all characters in B are alphabetic
and there is at least one character in B, False otherwise.
"""
return False
def isdigit(self): # real signature unknown; restored from __doc__
"""
B.isdigit() -> bool
Return True if all characters in B are digits
and there is at least one character in B, False otherwise.
"""
return False
def islower(self): # real signature unknown; restored from __doc__
"""
B.islower() -> bool
Return True if all cased characters in B are lowercase and there is
at least one cased character in B, False otherwise.
"""
return False
def isspace(self): # real signature unknown; restored from __doc__
"""
B.isspace() -> bool
Return True if all characters in B are whitespace
and there is at least one character in B, False otherwise.
"""
return False
def istitle(self): # real signature unknown; restored from __doc__
"""
B.istitle() -> bool
Return True if B is a titlecased string and there is at least one
character in B, i.e. uppercase characters may only follow uncased
characters and lowercase characters only cased ones. Return False
otherwise.
"""
return False
def isupper(self): # real signature unknown; restored from __doc__
"""
B.isupper() -> bool
Return True if all cased characters in B are uppercase and there is
at least one cased character in B, False otherwise.
"""
return False
def join(self, *args, **kwargs): # real signature unknown; NOTE: unreliably restored from __doc__
"""
Concatenate any number of bytes objects.
The bytes whose method is called is inserted in between each pair.
The result is returned as a new bytes object.
Example: b'.'.join([b'ab', b'pq', b'rs']) -> b'ab.pq.rs'.
"""
pass
def ljust(self, width, fillchar=None): # real signature unknown; restored from __doc__
"""
B.ljust(width[, fillchar]) -> copy of B
Return B left justified in a string of length width. Padding is
done using the specified fill character (default is a space).
"""
pass
def lower(self): # real signature unknown; restored from __doc__
"""
B.lower() -> copy of B
Return a copy of B with all ASCII characters converted to lowercase.
"""
pass
def lstrip(self, *args, **kwargs): # real signature unknown
"""
Strip leading bytes contained in the argument.
If the argument is omitted or None, strip leading ASCII whitespace.
"""
pass
@staticmethod # known case
def maketrans(*args, **kwargs): # real signature unknown
"""
Return a translation table useable for the bytes or bytearray translate method.
The returned table will be one where each byte in frm is mapped to the byte at
the same position in to.
The bytes objects frm and to must be of the same length.
"""
pass
def partition(self, *args, **kwargs): # real signature unknown
"""
Partition the bytes into three parts using the given separator.
This will search for the separator sep in the bytes. If the separator is found,
returns a 3-tuple containing the part before the separator, the separator
itself, and the part after it.
If the separator is not found, returns a 3-tuple containing the original bytes
object and two empty bytes objects.
"""
pass
def replace(self, *args, **kwargs): # real signature unknown
"""
Return a copy with all occurrences of substring old replaced by new.
count
Maximum number of occurrences to replace.
-1 (the default value) means replace all occurrences.
If the optional argument count is given, only the first count occurrences are
replaced.
"""
pass
def rfind(self, sub, start=None, end=None): # real signature unknown; restored from __doc__
"""
B.rfind(sub[, start[, end]]) -> int
Return the highest index in B where subsection sub is found,
such that sub is contained within B[start,end]. Optional
arguments start and end are interpreted as in slice notation.
Return -1 on failure.
"""
return 0
def rindex(self, sub, start=None, end=None): # real signature unknown; restored from __doc__
"""
B.rindex(sub[, start[, end]]) -> int
Return the highest index in B where subsection sub is found,
such that sub is contained within B[start,end]. Optional
arguments start and end are interpreted as in slice notation.
Raise ValueError when the subsection is not found.
"""
return 0
def rjust(self, width, fillchar=None): # real signature unknown; restored from __doc__
"""
B.rjust(width[, fillchar]) -> copy of B
Return B right justified in a string of length width. Padding is
done using the specified fill character (default is a space)
"""
pass
def rpartition(self, *args, **kwargs): # real signature unknown
"""
Partition the bytes into three parts using the given separator.
This will search for the separator sep in the bytes, starting and the end. If
the separator is found, returns a 3-tuple containing the part before the
separator, the separator itself, and the part after it.
If the separator is not found, returns a 3-tuple containing two empty bytes
objects and the original bytes object.
"""
pass
def rsplit(self, *args, **kwargs): # real signature unknown
"""
Return a list of the sections in the bytes, using sep as the delimiter.
sep
The delimiter according which to split the bytes.
None (the default value) means split on ASCII whitespace characters
(space, tab, return, newline, formfeed, vertical tab).
maxsplit
Maximum number of splits to do.
-1 (the default value) means no limit.
Splitting is done starting at the end of the bytes and working to the front.
"""
pass
def rstrip(self, *args, **kwargs): # real signature unknown
"""
Strip trailing bytes contained in the argument.
If the argument is omitted or None, strip trailing ASCII whitespace.
"""
pass
def split(self, *args, **kwargs): # real signature unknown
"""
Return a list of the sections in the bytes, using sep as the delimiter.
sep
The delimiter according which to split the bytes.
None (the default value) means split on ASCII whitespace characters
(space, tab, return, newline, formfeed, vertical tab).
maxsplit
Maximum number of splits to do.
-1 (the default value) means no limit.
"""
pass
def splitlines(self, *args, **kwargs): # real signature unknown
"""
Return a list of the lines in the bytes, breaking at line boundaries.
Line breaks are not included in the resulting list unless keepends is given and
true.
"""
pass
def startswith(self, prefix, start=None, end=None): # real signature unknown; restored from __doc__
"""
B.startswith(prefix[, start[, end]]) -> bool
Return True if B starts with the specified prefix, False otherwise.
With optional start, test B beginning at that position.
With optional end, stop comparing B at that position.
prefix can also be a tuple of bytes to try.
"""
return False
def strip(self, *args, **kwargs): # real signature unknown
"""
Strip leading and trailing bytes contained in the argument.
If the argument is omitted or None, strip leading and trailing ASCII whitespace.
"""
pass
def swapcase(self): # real signature unknown; restored from __doc__
"""
B.swapcase() -> copy of B
Return a copy of B with uppercase ASCII characters converted
to lowercase ASCII and vice versa.
"""
pass
def title(self): # real signature unknown; restored from __doc__
"""
B.title() -> copy of B
Return a titlecased version of B, i.e. ASCII words start with uppercase
characters, all remaining cased characters have lowercase.
"""
pass
def translate(self, *args, **kwargs): # real signature unknown
"""
Return a copy with each character mapped by the given translation table.
table
Translation table, which must be a bytes object of length 256.
All characters occurring in the optional argument delete are removed.
The remaining characters are mapped through the given translation table.
"""
pass
def upper(self): # real signature unknown; restored from __doc__
"""
B.upper() -> copy of B
Return a copy of B with all ASCII characters converted to uppercase.
"""
pass
def zfill(self, width): # real signature unknown; restored from __doc__
"""
B.zfill(width) -> copy of B
Pad a numeric string B with zeros on the left, to fill a field
of the specified width. B is never truncated.
"""
pass
def __add__(self, *args, **kwargs): # real signature unknown
""" Return self+value. """
pass
def __contains__(self, *args, **kwargs): # real signature unknown
""" Return key in self. """
pass
def __eq__(self, *args, **kwargs): # real signature unknown
""" Return self==value. """
pass
def __getattribute__(self, *args, **kwargs): # real signature unknown
""" Return getattr(self, name). """
pass
def __getitem__(self, *args, **kwargs): # real signature unknown
""" Return self[key]. """
pass
def __getnewargs__(self, *args, **kwargs): # real signature unknown
pass
def __ge__(self, *args, **kwargs): # real signature unknown
""" Return self>=value. """
pass
def __gt__(self, *args, **kwargs): # real signature unknown
""" Return self>value. """
pass
def __hash__(self, *args, **kwargs): # real signature unknown
""" Return hash(self). """
pass
def __init__(self, value=b'', encoding=None, errors='strict'): # known special case of bytes.__init__
"""
bytes(iterable_of_ints) -> bytes
bytes(string, encoding[, errors]) -> bytes
bytes(bytes_or_buffer) -> immutable copy of bytes_or_buffer
bytes(int) -> bytes object of size given by the parameter initialized with null bytes
bytes() -> empty bytes object
Construct an immutable array of bytes from:
- an iterable yielding integers in range(256)
- a text string encoded using the specified encoding
- any object implementing the buffer API.
- an integer
# (copied from class doc)
"""
pass
def __iter__(self, *args, **kwargs): # real signature unknown
""" Implement iter(self). """
pass
def __len__(self, *args, **kwargs): # real signature unknown
""" Return len(self). """
pass
def __le__(self, *args, **kwargs): # real signature unknown
""" Return self<=value. """
pass
def __lt__(self, *args, **kwargs): # real signature unknown
""" Return self<value. """
pass
def __mod__(self, *args, **kwargs): # real signature unknown
""" Return self%value. """
pass
def __mul__(self, *args, **kwargs): # real signature unknown
""" Return self*value.n """
pass
@staticmethod # known case of __new__
def __new__(*args, **kwargs): # real signature unknown
""" Create and return a new object. See help(type) for accurate signature. """
pass
def __ne__(self, *args, **kwargs): # real signature unknown
""" Return self!=value. """
pass
def __repr__(self, *args, **kwargs): # real signature unknown
""" Return repr(self). """
pass
def __rmod__(self, *args, **kwargs): # real signature unknown
""" Return value%self. """
pass
def __rmul__(self, *args, **kwargs): # real signature unknown
""" Return self*value. """
pass
def __str__(self, *args, **kwargs): # real signature unknown
""" Return str(self). """
pass
bytes类型的源码
那么str与bytes类型到底有什么区别和联系呢,接下来咱们以表格的形式给你做对比。
| 类名 | str类型 | bytes类型 | 标注 |
| 名称 | str,字符串,文本文字 | bytes,字节文字 | 不同,可以通过文本文字或者字节文字加以区分 |
| 组成单位 | 字符 | 字节 | 不同 |
| 组成形式 | '' 或者 "" 或者 ''' ''' 或者 """ """ | b'' 或者 b"" 或者 b''' ''' 或者 b""" """ | 不同,bytes类型就是在引号前面+b(B)大小写都可以 |
| 表现形式 |
英文: 'alex' 中文: '中国' |
英文:b'alex' 中文:b'xe4xb8xadxe5x9bxbd' |
字节文字对于ascii中的元素是可以直接显示的, 但是非ascii码中的元素是以十六进制的形式表示的,不易看出。 |
| 编码方式 | Unicode | 可指定编码(除Unicode之外)比如UTF-8,GBK 等 | 不同 |
| 相应功能 | upper lower spllit 等等 | upper lower spllit 等等 | 几乎相同 |
| 转译 | 可在最前面加r进行转译 | 可在最前面加r进行转译 | 相同 |
| 重要用途 | python基础数据类型,用于存储少量的常用的数据 |
负责以二进制字节序列的形式记录所需记录的对象, 至于该对象到底表示什么(比如到底是什么字符) 则由相应的编码格式解码所决定。 Python3中,bytes通常用于网络数据传输、 二进制图片和文件的保存等等 |
bytes就是用于数据存储和网络传输数据 |
| 更多 | ...... | ...... |
那么上面写了这么多,咱们不用全部记住,对于某些知识点了解一下即可,但是对于有些知识点是需要大家理解的:
bytes类型也称作字节文本,他的主要用途就是网络的数据传输,与数据存储。那么有些同学肯定问,bytes类型既然与str差不多,而且操作方法也很相似,就是在字符串前面加个b不就行了,python为什么还要这两个数据类型呢?我只用bytes不行么?
如果你只用bytes开发,不方便。因为对于非ascii码里面的文字来说,bytes只是显示的是16进制。很不方便。
s1 = '中国' b1 = b'xe4xb8xadxe5x9bxbd' # utf-8 的编码
好,上面咱们对于bytes类型应该有了一个大致的了解,对str 与 bytes的对比也是有了对比的了解,那么咱们最终要解决的问题,现在可以解决了,那就是str与bytes类型的转换的问题。
如果你的str数据想要存储到文件或者传输出去,那么直接是不可以的,上面我们已经图示了,我们要将str数据转化成bytes数据就可以了。
str ----> bytes

# encode称作编码:将 str 转化成 bytes类型
s1 = '中国'
b1 = s1.encode('utf-8') # 转化成utf-8的bytes类型
print(s1) # 中国
print(b1) # b'xe4xb8xadxe5x9bxbd'
s1 = '中国'
b1 = s1.encode('gbk') # 转化成gbk的bytes类型
print(s1) # 中国
print(b1) # b'xd6xd0xb9xfa'
bytes ---> str
# decode称作解码, 将 bytes 转化成 str类型
b1 = b'xe4xb8xadxe5x9bxbd'
s1 = b1.decode('utf-8')
print(s1) # 中国
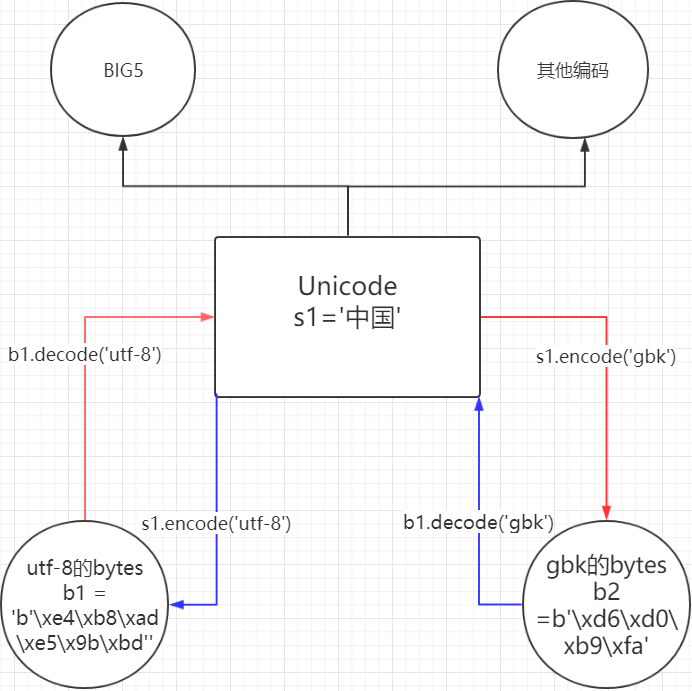
那么这里还有一个最重要的,也是你们以后工作中经常遇到的让人头疼的问题,就是gbk编码的数据,转化成utf-8编码的数据。有人说老师,我怎么有点蒙呢?这是什么? 来,捋一下,bytes类型他叫字节文本,他的编码方式是非Unicode的编码,非Unicode即可以是gbk,可以是UTF-8,可以是GB2312.....
b1 = b'xe4xb8xadxe5x9bxbd' # 这是utf-8编码bytes类型的中国 b2 = b'xd6xd0xb9xfa' # 这是gbk编码bytes类型的中国
那么gbk编码的bytes如何转化成utf-8编码的bytes呢?
不同编码之间,不能直接互相识别。
上面我说了,不同编码之间是不能直接互相是别的,这里说了不能直接,那就可以间接,如何间接呢? 现存世上的所有的编码都和谁有关系呢? 都和万国码Unicode有关系,所以需要借助Unicode进行转换。
看下面的图就行了!