Hive的基本理论与安装可参看作者上一篇博文《Apache Hive 基本理论与安装指南》。
一、Hive命令行
所有的hive命令都可以通过hive命令行去执行,hive命令行中仍有许多选项。使用$hive -H查看:

-e 选项后面可以直接接一个hql语句,不用进入到hive命令行用户接口再输入hql语句。
-f 选项后面接一个hql语句的文件。
-i 选项在hql语句执行之前的初始化hql文件。例如添加、导入等操作都可以写在这个hql语句文件中。
在hive使用中,大多是写很多脚本,在hive命令行中输入是属于交互式的,这就必须有工作人员在工作,不适合做批量处理。可以使用-f或-i选项,一次性执行可以将所有的hql语句放在一个hql脚本文件中。例如:
$ mkdir -p /opt/shell/sql $ vim /opt/shell/sql/test.sql
select * from table_name limit 5; select * from table_name where professional="student"; select count(*) from table_name; select count(*) from table_name group by professional; select * from table_name where professional="student" order by age;
将脚本保存退出后,再批量执行:
$ hive -f /opt/shell/sql/test.sql
二、Hive DDL(Data Definition Language)
- Hive Data Definition Language
- Overview
- Keywords, Non-reserved Keywords and Reserved Keywords
- Create/Drop/Alter/Use Database
- Create/Drop/Truncate Table
- Alter Table/Partition/Column
- Create/Drop/Alter View
- Create/Drop/Alter Index
- Create/Drop Macro
- Create/Drop/Reload Function
- Create/Drop/Grant/Revoke Roles and Privileges
- Show
- Describe
- Abort
- HCatalog and WebHCat DDL
详见官方文档。重点在于创建表和创建函数。
1. 建表语法
- 建表语句
从官方文档的Create Table中可以查看hive建表的命令,如下:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later) [(col_name data_type [COMMENT col_comment], ... [constraint_specification])] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)] ON ((col_value, col_value, ...), (col_value, col_value, ...), ...) [STORED AS DIRECTORIES] [ [ROW FORMAT row_format] [STORED AS file_format] | STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later) ] [LOCATION hdfs_path] [TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later) [AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables) CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name LIKE existing_table_or_view_name [LOCATION hdfs_path];
- 数据类型
data_type : primitive_type | array_type | map_type | struct_type | union_type -- (Note: Available in Hive 0.7.0 and later)
data_type,有两种类型:一种是复杂类型,例如array_type(ARRAY < data_type >)、map_type(MAP < primitive_type, data_type >)、struct_type(STRUCT < col_name : data_type [COMMENT col_comment], ...>)、union_type(UNIONTYPE < data_type, data_type, ... >);简单类型有SMALLINT(占2个字节的整数)、INT(占4个字节的整数)、BIGINT(占8个字节的整数)、BOOLEAN、FLOAT、DOUBLE、STRING、BINARY、TIMESTAMP、DECIMAL、DATE、VARCHAR(0.12之后)、CHAR(字符,0.13之后)。
primitive_type : TINYINT | SMALLINT | INT | BIGINT | BOOLEAN | FLOAT | DOUBLE | DOUBLE PRECISION -- (Note: Available in Hive 2.2.0 and later) | STRING | BINARY -- (Note: Available in Hive 0.8.0 and later) | TIMESTAMP -- (Note: Available in Hive 0.8.0 and later) | DECIMAL -- (Note: Available in Hive 0.11.0 and later) | DECIMAL(precision, scale) -- (Note: Available in Hive 0.13.0 and later) | DATE -- (Note: Available in Hive 0.12.0 and later) | VARCHAR -- (Note: Available in Hive 0.12.0 and later) | CHAR -- (Note: Available in Hive 0.13.0 and later)
- row_format
row_format : DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] [NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later) | SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
row_format:需要指出每一行是由什么隔开,并且要指出每一行中的每一个字段是用什么隔开的。
对于字段的隔开,复杂数据类型和简单数据类型不一样。例如数组类型是复杂类型,其隔开符[COLLECTION ITEMS TERMINATED BY char],Map类型的要使用[MAP KEYS TERMINATED BY char]。[LINES TERMINATED BY char]可以设置行隔开符,如果不写,默认为回车换行。
- file_format
file_format: : SEQUENCEFILE | TEXTFILE -- (Default, depending on hive.default.fileformat configuration) | RCFILE -- (Note: Available in Hive 0.6.0 and later) | ORC -- (Note: Available in Hive 0.11.0 and later) | PARQUET -- (Note: Available in Hive 0.13.0 and later) | AVRO -- (Note: Available in Hive 0.14.0 and later) | INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
SEQUENCEFILE表示序列压缩格式,以及RCFILE、ORC、PARQUET、AVRO都是压缩格式。TEXTFILE是默认的格式,文本格式。
2. 创建表案例一
- 查看数据
为举例说明,这里先生成数据文件:
vim /root/person.txt
1,zhangsan,31,books-sports-math,city:shanghai-street:lujiazui-zipcode:313100 2,lisi,35,books-music,city:hangzhou-street:xihu-zipcode:222100 3,wangwu,25,computer-games,city:guangzhou-street:baiyun-zipcode:212300
- 创建表
根据数据创建一个人类表,包含人的编号、姓名、年龄、爱好、地址五个字段。
vim /opt/shell/sql/t_person.sql
create table t_person ( id int, name string, age int, likes array<string>, address map<string,string> ) row format delimited fields terminated by ',' collection items terminated by '-' map keys terminated by ':' lines terminated by ' ' stored as textfile;
根据表结构,字段之间按,隔开;likes的类型是array,所以可以有多个爱好,元素之间按-隔开,以,作为数组的结束;地址是map类型,也是collection类型, key和value按:隔开,每对key和value之间用-隔开(和collection一致);回车代表换行符。
执行创建表脚本:
$ hive -f /opt/shell/sql/t_person.sql
- 将数据从本地导入到hive
hive> load data local inpath '/root/person.txt' into table t_person;
- 查看数据

3. 创建表案例二(分区表)
当我们要在关系型数据库中查找某一数据时,一般需要匹配数据库中的所有数据,所以可以通过分区来提高查询效率。把常用的查询条件作为一种分区,例如要查某一天的数据,事实上就是可以只匹配当天的数据,其他数据不匹配。下面以建一个日志管理表为例:
- 数据文件
文件经常按照天、小时等进行分割。故在此创建多个文件如下:
vim /root/log_2016-03-11.txt
111,1,200,2016-03-11 135,4,100,2016-03-11 211,3,300,2016-03-11 141,1,200,2016-03-11 131,2,400,2016-03-11
vim /root/log_2016-03-12.txt
121,2,300,2016-03-12 125,3,400,2016-03-12 211,1,400,2016-03-12 161,3,100,2016-03-12 171,5,200,2016-03-12
- 创建表结构
create table t_log (id string,type int,pid string,logtime string) partitioned by (day string) row format delimited fields terminated by ',' stored as textfile;
这里指定了按照天做分区。
- 装载数据
hive> load data local inpath '/root/log_2016-03-11.txt' into table t_log partition (day='2016-03-11'); hive> load data local inpath '/root/log_2016-03-12.txt' into table t_log partition (day='2016-03-12');
- 查看数据
hive> select * from t_log;
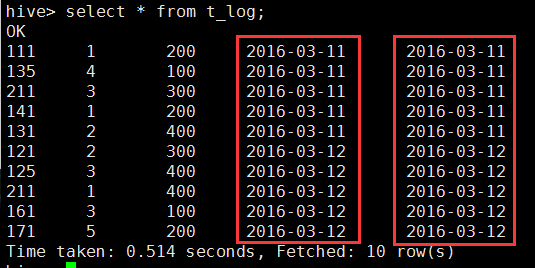
从上图可以看出,数据增加了一个字段,左边是logtime,右边是分区day。所以,添加一个分区可以理解为添加一个字段;但是又不同于添加一个字段,因为查询按照分区做限定(查询分区day='2016-03-11')时其他分区的数据不读取,而如果是字段的话,需要每一条数据进行匹配过滤。也可以从浏览器看出创建分区表的目录结构如下:
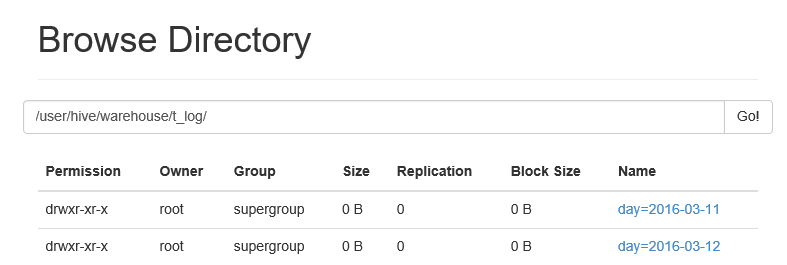
创建分区,就会为每一个分区建一个目录,所以在查询时,只在限定的分区目录里查询。
查看某一天的数据量
hive> select count(*) from t_log where day='2016-03-11';
查看某一个月的数据量
hive>select count(*) from t_log where day between 'xxx' and 'xxx';
当然,这里需要先转换格式,略。
三、Hive DML(Data Manipulation Language)
- Hive Data Manipulation Language
详见官方文档。DML是对数据进行增删改的脚本。但是数据在hdfs中,实际上不提供修改,只提供追加(insert),支持删除。
1. Loading files into tables
- 语法
load file将数据导入到表中。其语法为:
hive> LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
local:如果导入的数据在Linux主机本地,就要添加[local],如果数据已经在hdfs上就不能加local;overwrite:覆盖;partition:如果表有分区就要加partition。
- 实例
- 将hdfs中的数据装载到hive
首先,上传Linux文件到hdfs
$ hdfs dfs -put /root/log_2016-03-1* /usr/input
其次,在hive中执行导入
hive>load data inpath '/usr/input/log_2016-03-12.txt' into table t_log partition (day='2016-03-12');
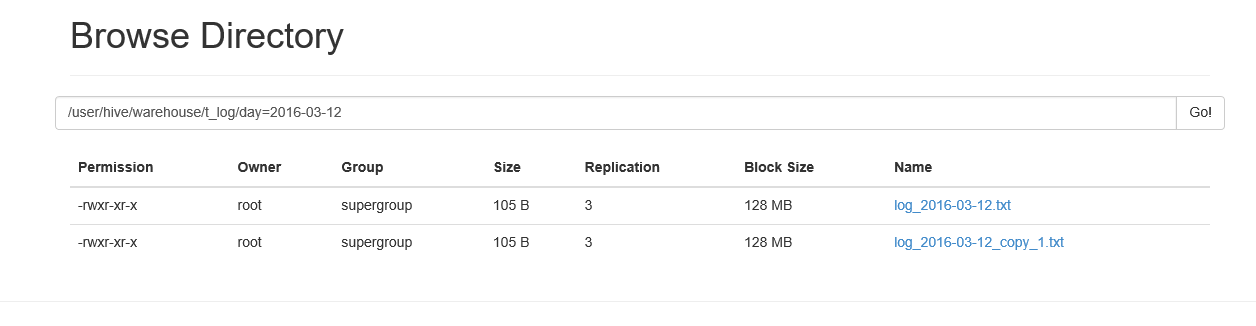
hive>load data inpath '/usr/input/log_2016-03-12.txt' overwrite into table t_log partition (day='2016-03-12');
注意:导入的分区要存在,导入到hive表后原来hdfs路径下的文件就不复存在了,即存在hdfs的目录变了,实际就是元数据变了,block的位置没有变。如果使用overwrite,则原来该表中指定分区的数据将全部清空,然后上传该文件。如果load相同文件名名到表中时,会默认生成副本filename_copy_1。文件中的数据格式要和表的结构相吻合。
-
- 将Linux本地的数据装载到hive
hive>load data local inpath '/root/log_2016-03-11.txt' into table t_log partition (day='2016-03-11');
2. Inserting data into hive tables from queries
- 语法
hive> INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;
hive> INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;
其中的select_statement1 FROM from_statement;是一个sql语句。这是用于查询hive中已经存在的数据,将查询结果给到一张新表中。
hive> INSERT INTO TABLE tablename [PARTITION (partcol1[=val1], partcol2[=val2] ...)] VALUES values_row [, values_row ...]
这个语句是和关系型数据库的insert语句用法是一样的。区别有三:一是,有partition;二是,可以一次插入多条数据;三是,这种语句是转成MapReduce去执行的。
因为hive是一个工具,其作用是查询和统计hdfs上的数据的,对于查询结果一般就在控制台上显示,所以这个insert语句作用就是将查询的结果保存下来,用于后期的展示。
- 实例
hive> insert into table t_log partition (day='2016-03-13’) values ('888',2,'100','2016-03-13’);
这个会启动MapReduce,因为数据在文件中不存在,要插到文件中相当于上传,会生成一个新的文件。这个不常用。所以实际上inset into语句的实际意义在于将查询结果放到新的表中。
3. Delete
删除数据一般可以不在hive中删除,直接在hdfs上删除文件。因为删数据实际上就是删除文件。例如要删除之前插入到hive的t_log表day=2016-03-11分区下的log_2016-03-11.txt,可以执行如下命令:
#hdfs dfs -rm /user/hive/warehouse/t_log/day=2016-03-11/t_log-2016-03-11.txt
四、Hive UDF(Operators and User-Defined functions)
- Hive Operators and User-Defined Functions (UDFs)
详见官方文档。
1. 内置运算符
- 关系运算符
见文档
- 算术运算符
见文档
- 逻辑运算符
见文档
- 复杂类型构造函数(Complex Type Constructors)
- 复杂类型函数或对象的构建
【1】map(构造map对象)
Creates a map with the given key/value pairs. (key1,value1,key2,value2,…)
【2】struct(创建架构数组)
Creates a struct with the given field values. (val1,val2,val3,…)。Struct的属性名和列名相对应。struct可以认为是面向对象的对象类型,是一个构造体,里面可以定义属性的值,field的名称是预先定义的,就像Java类的属性预先定义好了。
【3】named_struct
Creates a struct with the given field names and values. (name1,val1,name2,val2, …)。根据给定的Struct的属性名来创建构建数组
【4】array(创建数组对象)
Creates an array with the given elements. (val1,val2,val3,…)。把各(若干)个字段的值变成一个array。
【5】create_union
Creates a union type with value that is being pointes to by the tag parameter.
-
- 复杂类型函数的运算符
【1】A[n]
A是array类型,n是int类型。A[n]表示数组A的第n+1个元素。
【2】M[key]
M是map类型,key是map集合中键的类型。M[key]是取map集合中键为key的值。注意使用是key需要使用单引号。
【3】S.x
S是struct类型,x表示struct中的某个属性。S.x,将会返回S这个struct中定义的x属性型中存储的值。
2. 内置函数
- 数学函数

- 集合操作函数

- 类型转换函数

- 日期函数

- 条件/逻辑函数
略。
- 字符串函数

3. UDAF
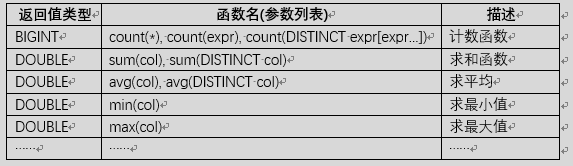
UDAF和UDF的区别在于传给函数的参数不一样。UDF表示传给函数的参数只有一个值或一行值;UDAF是给函数传多个值或者多行值的函数,例如count(*),sum(col)等都是多行的值。
UDAF(User- Defined Aggregation Funcation) 聚集函数,多进一出,例如count/max/min等。
4. UDTF
详见文档。
5. UDF
HivePlugins,Creating Custom UDFs。自定义函数需要以下几个步骤:首先要自定义一个类,继承UDF;其次,打成jar包;第三,将jar包加载到hive的classpath;第四,创建自定义函数;第五,使用函数。
例如,要创建一个将字符串转成日期的函数。
- 自定义类
package com.huidoo.hive; import java.text.SimpleDateFormat; import java.util.Date; import org.apache.hadoop.hive.ql.exec.UDF; import org.apache.hadoop.hive.serde2.io.TimestampWritable; import org.apache.hadoop.io.Text; public class StringToDate extends UDF { /** * 定义evaluate方法。返回值类型定义为TimestampWritable * @param str * @param datefmt * @return * @throws Exception */ public TimestampWritable evaluate(final Text str,final Text datefmt) throws Exception{ SimpleDateFormat sdf= new SimpleDateFormat(datefmt.toString()); //datefmt是传入的格式化字符串,需要创建SimpleDateFormat对象,Text类型要转成Java中的String类型。 Date date= sdf.parse(str.toString()); //将字符串str,按照格式sdf转成java.util的Date类型 TimestampWritable time=new TimestampWritable();//创建Hadoop的时间戳对象 time.setTime(date.getTime());//将date转成Timestamp类型,然后使用Hadoop时间戳对象设置成相应的时间。 return time; } }
- 打成jar包并上传到服务器
略。std.jar
- 将jar包加载到hive的classpath
hive> add jar /path/to/std.jar;
- 创建函数
语法:create 函数名(不能与内置的一样) as ‘自定义类的全限定名’;
hive> create function std as 'com.huidoo.hive.StringToDate';
这就创建了一个函数,名为std。
- 使用函数
hive> select std('2016-02-06 01:19:30','yyyy-MM-dd HH:mm:ss') from t_log limit 3;
五、Hive Select
1. 简单查询和使用/切换数据库
hive> select * from table_name;
查看当前数据库:
hive> SELECT current_database();
"db_name.table_name" allows a query to access tables in different databases.可以查询不同数据库中的表。
使用某数据库:
hive> USE database_name;
2. where从句
hive>SELECT * FROM sales WHERE amount > 10 AND region = "US"
3. ALL and DISTINCT从句
使用distinct关键字去重查询,如下列出两个查询的区别:
hive> SELECT col1, col2 FROM t1
1 3
1 3
1 4
2 5
hive> SELECT DISTINCT col1, col2 FROM t1
1 3
1 4
2 5
4. Join从句
join用于表连接。两个表即两个文件能连接起来就一定有相同点,这就是说其中一个文件中某域的值和另一个文件的某域的值相同,就可以连接。
hive> select col1,col2,col3 from t1 join t2 on+条件;
5. 基于Partition的查询
这种查询语法就只要把partition当成一个字段即可。如果查询时要引入外键关联表也可以使用JION…ON语句。
- 非关联查询
语法:
hive> select table_name.* from table_name where table_name.partition_name +条件;
案例:
SELECT page_views.* FROM page_views WHERE page_views.date >= '2016-03-01' AND page_views.date <= '2016-03-31';
- 关联查询
语法:
hive> select table_name1.* from table_name1 join table_name2 on (table_name1.外键 = table_name2.主键 And table_name1.partiton_name +条件);
案例:
SELECT page_views.* FROM page_views JOIN dim_users ON (page_views.user_id = dim_users.id AND page_views.date >= '2016-03-01' AND page_views.date <= '2016-03-31');
6. Group by从句
hive> select col[list] from table_name group by col;
7. Order/Sort by从句
sort by和order by的用法基本一致,都是做排序的,一般用order by。例如:
hive> select * from t_log order by id;
8. Having从句
having从句必须依附于group by从句,在group从句后面接having从句,相当于增加一个条件。having后面可以接聚合函数,例如sum、avg等。
- 单纯的group by语句
hive> select day from t_log group by day;
其查询结果为:
2016-03-11
2016-03-12
- 添加having从句
hive>select day from t_log group by day having avg(id)>150;
其查询结果为:
2016-03-12
- hiving同效于子查询
hive> select day from (select day, avg(id) as avgid from t_log group by day) table2 where table2.avgid>150;
这里将t_log表通过select day, avg(id) as avgid from t_log group by day查询得到的结果作为表再查询的。和上述的hiving从句得到的结果一样。
9. Limit从句
限定查询返回的行数。
hive> select * from t_log limit 5;