相关文章链接
CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令
CentOS6安装各种大数据软件 第三章:Linux基础软件的安装
CentOS6安装各种大数据软件 第四章:Hadoop分布式集群配置
CentOS6安装各种大数据软件 第五章:Kafka集群的配置
CentOS6安装各种大数据软件 第六章:HBase分布式集群的配置
CentOS6安装各种大数据软件 第七章:Flume安装与配置
CentOS6安装各种大数据软件 第八章:Hive安装和配置
CentOS6安装各种大数据软件 第九章:Hue大数据可视化工具安装和配置
CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
1. Flume安装
此flume安装以用户点击行为实时安装为例(2台flume从日志系统中获取数据,并汇总到一台flume上,并由这台flume对数据进行分发,分别分发到Kafka和HBase等其他应用上),安装步骤如下所示
步骤一:上次压缩包
步骤二:解压到安装目录下
tar -zxvf apache-flume-1.7.0-bin.tar.gz -C /export/servers/
2. Flume配置
2.1. Flume节点配置规划和系统要求


2.2. Flume节点agent2详细配置(在conf目录下配置)
2.2.1. 在flume-env.sh文件中配置JAVA_HOME
#修改文件名称
mv flume-env.sh.template flume-env.sh
#配置Java环境变量
export JAVA_HOME=/opt/modules/jdk1.8.0_144
2.2.2. 在flume-conf.properties文件中配置数据来源和下沉地
#步骤一:修改文件名称
mv flume-conf.properties.template flume-conf.properties
#步骤二:进行具体配置
#给三个线程起一个别名(数据来源,管道,下沉地)
a2.sources = r1
a2.channels = c1
a2.sinks = k1
#设置Flume源(类型,数据来源的地址,数据通过什么通道传输)
a2.sources.r1.type = exec
a2.sources.r1.command = tail -F /export/datas/access/access.log
a2.sources.r1.channels = c1
#设置Flume通道类型
a2.channels.c1.type = memory
#设置Flume通道大小
a2.channels.c1.capacity = 10000
#每次从源抓取数据的大小
a2.channels.c1.transactionCapacity = 10000
#超时事件的设定
a2.channels.c1.keep-alive = 5
#设置flume的sink(sink的类型,通道来自哪里,往哪台服务器发送数据,下沉的端口号)
a2.sinks.k1.type = avro
a2.sinks.k1.channel = c1
#下沉的服务器的ip地址
a2.sinks.k1.hostname = node01.ouyang.com
#下沉的服务器的端口号
a2.sinks.k1.port = 5555
2.3. Flume节点agent3详细配置(在conf目录下配置)
同上agent2配置即可,为区别不同服务器,将a2修改a3即可(不修改不影响实际使用,但为了区别不同服务器,建议修改)
2.4. Flume节点agent1详细配置(在conf目录下配置)
说明:agent2和agent3节点的数据下沉地为node01服务器的5555端口,所以agent1的数据来源只有一个,为本机的5555端口,agent1的flume只需要从本机的5555端口获取数据即可。但此flume的下沉地有2个,分别是HBase和Kafka,所以相应的此flume的通道也要有2个。
agent1具体配置请看下文的Flume整合HBase和Flume整合Kafka。
3. Flume和HBase集成与开发
在实际工作中,Flume收集到的数据一般下层到HBase,Kafka,HDFS等应用,此处演示将Flume下层到HBase和Kafka的开发。如下图:
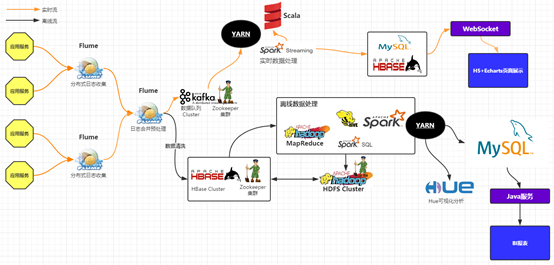
从上述可以看到我们有两个Flume服务器用来收集四台WEB应用服务器的日志信息,这两台服务器将数据汇总到另外一台总的Flume服务器上,也就是说另外两台的输出作为这台总的服务器的输入.这里的输入也就是avro.这台总的服务器可以将日志信息直接推送到 Kafka消息系统中,或者经过清洗之后,存入HBase数据库中.也就说我们会在存入HBase数据库之前进行二次开发.因为我们的Hbase数据库是非关系型数据库,它的列是不固定的.所以,我们需要对hbase sink进行自定义开发。
3.1. 下载Flume源码并导入IDEA
3.1.1. 下载Flume源码
官网:http://flume.apache.org/download.html

请注意:源码版本请和安装的flume版本匹配,如下图:

3.1.2. 将Flume源码导入IDEA工具
步骤一:解压源码压缩包
步骤二:打开IDEA,点击Open
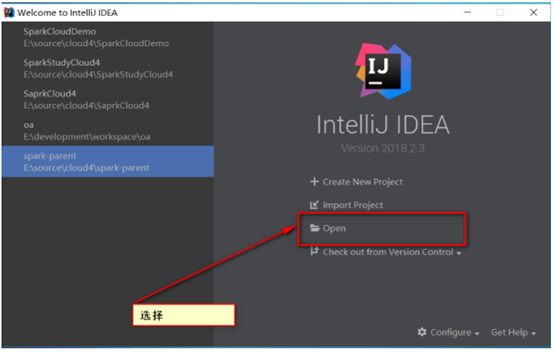
步骤三:选择导入flume-ng-sinks这个模块
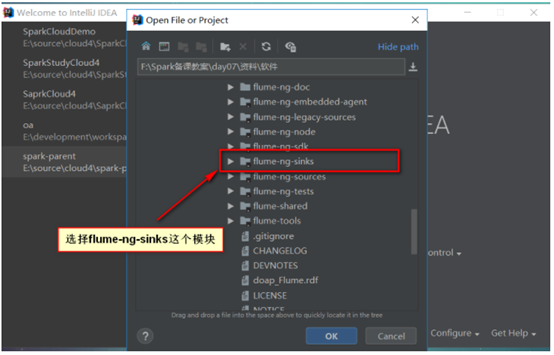
步骤四:选择flume-ng-sinks模块下的flume-ng-hbase-sink这个子模块

步骤五:进入源码
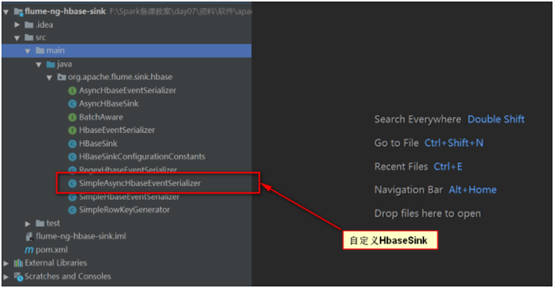
上述我们首先将源码导入IDEA中,待会我们会针对Flume和Hbase的整合进行sink的自定义。
3.2. 在flume-env.sh配置文件中配置JAVA_HOME
#修改文件名称
mv flume-env.sh.template flume-env.sh
#配置Java环境变量
export JAVA_HOME=/opt/modules/jdk1.8.0_144
3.3. 在flume-conf.properties文件中进行具体配置
#步骤一:修改文件名称
mv flume-conf.properties.template flume-conf.properties
#步骤二:进行具体配置
#定义三个线程的别称(因为下沉地有2个,所以设置2个管道和2个下沉地的别称)
a1.sources = r1
a1.channels = hbaseChannel kafkaChannel
a1.sinks = hbaseSink kfkSink
#设置源
#设置源的格式
a1.sources.r1.type = avro
#设置源接收的数据需要前往哪些管道
a1.sources.r1.channels = hbaseChannel kafkaChannel
#设置数据来源的ip地址
a1.sources.r1.bind = node01.ouyang.com
#设置数据来源的端口号
a1.sources.r1.port = 5555
#超时设置
a1.sources.r1.threads = 5
#设置hbaseChannel(配置hbase的管道信息)
a1.channels.hbaseChannel.type = memory
a1.channels.hbaseChannel.capacity = 100000
a1.channels.hbaseChannel.transactionCapacity = 100000
a1.channels.hbaseChannel.keep-alive = 20
#设置hbaseSink(配置hbase的下沉地信息)
a1.sinks.hbaseSink.type = asynchbase
a1.sinks.hbaseSink.table = access
a1.sinks.hbaseSink.columnFamily = info
a1.sinks.hbaseSink.serializer = [待定]
#根据数据定义列的名称
a1.sinks.hbaseSink.serializer.payloadColumn = datatime,userid,searchname,retorder,cliorder,cliurl
#设置sink来源的管道
a1.sinks.hbaseSink.channel = hbaseChannel
3.4. Flume自定义hbaseSink开发
Flume官方提供的HbaseSink的实现是SimpleAsyncHbaseEventSerializer,这个实现不符合我们本次项目中的要求,所以,我们需要自定义HbaseSink.自定义仿照SimpleAsyncHbaseEventSerializer即可。
3.4.1. 自定义hbaseSink开发示例
package org.apache.flume.sink.hbase; import com.google.common.base.Charsets; import org.apache.flume.Context; import org.apache.flume.Event; import org.apache.flume.FlumeException; import org.apache.flume.conf.ComponentConfiguration; import org.apache.flume.sink.hbase.SimpleHbaseEventSerializer.KeyType; import org.hbase.async.AtomicIncrementRequest; import org.hbase.async.PutRequest; import java.util.ArrayList; import java.util.List; @SuppressWarnings("all") public class HeimaAsyncHbaseEventSerializer implements AsyncHbaseEventSerializer { //表的名称 private byte[] table; //列簇名 private byte[] cf; //列的数据 private byte[] payload; //列的Column private byte[] payloadColumn; private byte[] incrementColumn; //rowKey的前缀 private String rowPrefix; private byte[] incrementRow; //告诉我们的keyType是哪一个 private KeyType keyType; @Override public void initialize(byte[] table, byte[] cf) { this.table = table; this.cf = cf; } @Override public List<PutRequest> getActions() { List<PutRequest> actions = new ArrayList<PutRequest>(); if (payloadColumn != null) { byte[] rowKey; try { //获取每一列 String[] columns = String.valueOf(payloadColumn).split(","); //获取每一列的值 String[] values = String.valueOf(payload).split(","); for (int i = 0; i < columns.length; i++) { //获取列的字节数组 byte[] colColumns = columns[i].getBytes(); //获取每一类的值的字节数组 byte[] colValues = values[i].getBytes(Charsets.UTF_8); //对列和值的长度进行判断,如果二者不一致,直接可以跳过,也就是不会进行数据落地 if(columns.length!=values.length){ continue; } //获取userid和datatime String datatime = values[0].toString(); String userid = values[1].toString(); rowKey = SimpleRowKeyGenerator.getHeimaRowKey(userid,datatime); PutRequest putRequest = new PutRequest(table, rowKey, cf, colColumns, colValues); actions.add(putRequest); } } catch (Exception e) { throw new FlumeException("Could not get row key!", e); } } return actions; } @Override public List<AtomicIncrementRequest> getIncrements() { List<AtomicIncrementRequest> actions = new ArrayList<AtomicIncrementRequest>(); if (incrementColumn != null) { AtomicIncrementRequest inc = new AtomicIncrementRequest(table, incrementRow, cf, incrementColumn); actions.add(inc); } return actions; } @Override public void cleanUp() { // TODO Auto-generated method stub } @Override public void configure(Context context) { String pCol = context.getString("payloadColumn", "pCol"); String iCol = context.getString("incrementColumn", "iCol"); rowPrefix = context.getString("rowPrefix", "default"); String suffix = context.getString("suffix", "uuid"); if (pCol != null && !pCol.isEmpty()) { if (suffix.equals("timestamp")) { keyType = KeyType.TS; } else if (suffix.equals("random")) { keyType = KeyType.RANDOM; } else if (suffix.equals("nano")) { keyType = KeyType.TSNANO; } else { keyType = KeyType.UUID; } payloadColumn = pCol.getBytes(Charsets.UTF_8); } if (iCol != null && !iCol.isEmpty()) { incrementColumn = iCol.getBytes(Charsets.UTF_8); } incrementRow = context.getString("incrementRow", "incRow").getBytes(Charsets.UTF_8); } @Override public void setEvent(Event event) { this.payload = event.getBody(); } @Override public void configure(ComponentConfiguration conf) { // TODO Auto-generated method stub } }
3.4.2. 自定义SimpleRowKeyGenerator的rowKey生成方法
public static byte[] getHeimaRowKey(String userid,String datatime) throws UnsupportedEncodingException { return (userid +"-"+ datatime +"-"+ String.valueOf(System.currentTimeMillis())).getBytes("UTF8"); }
3.5. 自定义HbaseSink编译打包
3.5.1. Hbase编译打包
将自定义的类放置到导入的flume-sink工程中,跟示例类SimpleAsyncHbaseEventSerializer同一个目录下,然后打包该工程即可。
步骤一:首先打开Project Structure
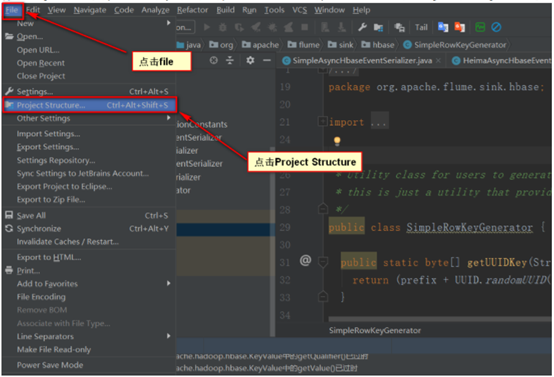
步骤二:点击Artifacts这一项,增加一个jar
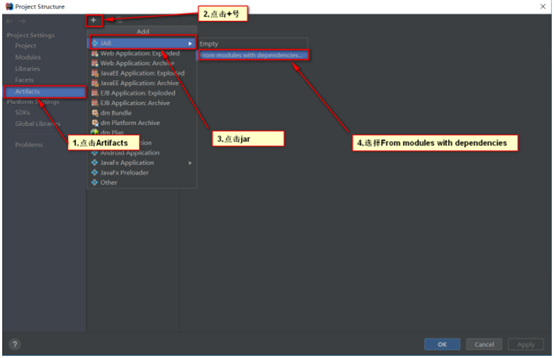
步骤三:选择需要打包的模块
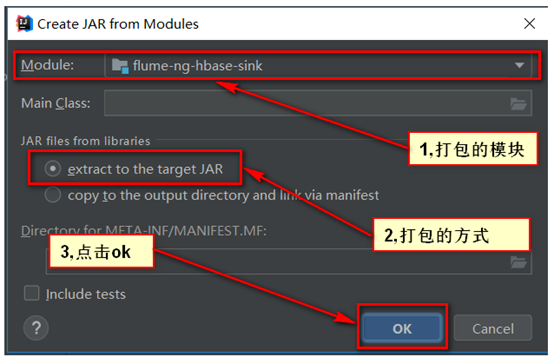
步骤四:对需要打包的模块进行配置
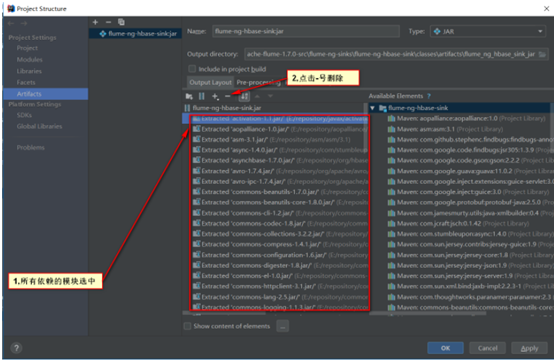
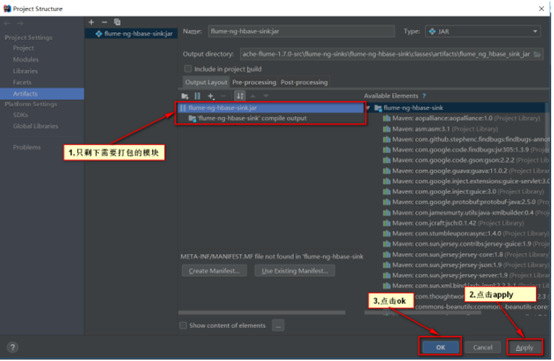
步骤五:确认配置
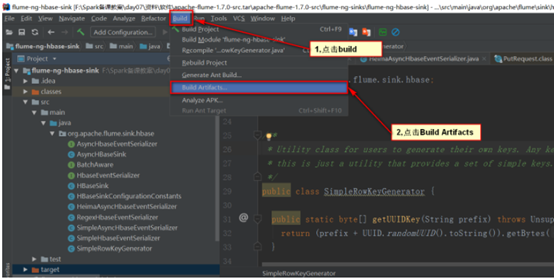
步骤六:进行打包,选择build这个菜单项
步骤七:得到打包的结果

3.5.2. 将编译好的jar包替换之前的jar包
步骤一:删除flume目录的lib目录下的flume-ng-hbase-sink-1.7.0.jar包
rm -rf flume-ng-hbase-sink-1.7.0.jar
步骤二:将打包好的jar包重命名为flume-ng-hbase-sink-1.7.0.jar,并上传到lib下
步骤三:修改flume-conf.properties,将自定义sink类的全限定名添加上去
a1.sinks.hbaseSink.serializer = org.apache.flume.sink.hbase.HeimaAsyncHbaseEventSerializer
flume-conf.properties

4. Flume和Kafka集成与开发
Flume和Kafka集成只要配置flume-conf.properties配置文件即可,该配置文件的数据来源可以参考上述flume和HBase的集合,下述为Flume和Kafka集成的管道和下沉地的配置。
#设置kafkaChannel(配置Kafka的管道信息)
a1.channels.kafkaChannel.type = memory
a1.channels.kafkaChannel.capacity = 100000
a1.channels.kafkaChannel.transactionCapacity = 100000
a1.channels.kafkaChannel.keep-alive = 20
#设置kfkSink(下沉地设置)
#设置下沉的数据来源(来自kafkaChannel管道)
a1.sinks.kfkSink.channel = kafkaChannel
#设置下沉的类型
a1.sinks.kfkSink.type = org.apache.flume.sink.kafka.KafkaSink
#设置下沉到kafka中的主题名
a1.sinks.kfkSink.topic = access
#设置kafka服务的ip和端口号
a1.sinks.kfkSink.brokerList = node01.ouyang.com:9092,node02.ouyang.com:9092,node03.ouyang.com:9092
#设置zookeeper的ip和端口号(因为要使用kafka需基于zookeeper)
a1.sinks.kfkSink.zookeeperConnect = node01.ouyang.com:2181,node02.ouyang.com:2181,node03.ouyang.com:2181
#设置kafka的生产者消息防丢失机制(默认为1)
a1.sinks.kfkSink.requiredAcks = 1
#设置一次传输数据的大小
a1.sinks.kfkSink.batchSize = 1
#设置序列化类,让数据可以进行网络传输
a1.sinks.kfkSink.serializer.class = kafka.serializer.StringEncoder
5. Flume启动
Flume启动前请先启动Flume所依赖的应用服务,如上述配置,需先启动HBase和Kafka,而HBase和Kafka又依赖Hadoop和Zookeeper,所以请先将这些依赖服务启动;Flume启动时请先启动分节点,再启动聚会节点,如果上述配置,请先启动agent2和agent3,再启动agent1。
5.1. Flume启动命令
bin/flume-ng agent -c conf -f conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console
-c conf 指定 flume 自身的配置文件所在目录
-f conf/netcat-logger.con 指定我们所描述的采集方案
-n a1 指定我们这个 agent 的名字
5.2. Flume一键启动脚本
以agent2和agent3收集数据,agent1汇总数据,并将数据分别分发到HBase和Kafka中为例:
#步骤一:给每台服务器的flume配置好环境变量 export FLUME_HOME=/export/servers/flume export PATH=${FLUME_HOME}/bin:$PATH #步骤二:在agent2和agent3服务器的flume的bin目录下编写启动脚本: #/bin/bash echo "................flume-2 starting......................" /export/servers/flume/bin/flume-ng agent --conf /export/servers/flume/conf/ -f /export/servers/flume/conf/flume-conf.properties -n a2 -Dflume.root.logger=INFO,console agent2和agent3启动脚本基本一致,就名字不同,该名字为在配置文件中配置的别名 编写完启动脚本后可以进行启动测试 #步骤三:在agent1服务器的flume的bin目录下编写启动脚本: #/bin/bash echo "................flume-1 starting......................" /export/servers/flume/bin/flume-ng agent --conf /export/servers/flume/conf/ -f /export/servers/flume/conf/flume-conf.properties -n a1 -Dflume.root.logger=INFO,console 因为Flume节点1是聚合节点,所以,需要依赖其他很多服务,所以在这里我们先不做任何测试验证,待会再进行统一的测试验证。 #步骤四:在onekye目录下编写一键启动脚本: cat /export/onekey/slave | while read line do { echo "Flume开始启动 --> "$line ssh $line "source /etc/profile;nohup sh ${FLUME_HOME}/bin/flume-access-start.sh >/dev/null 2>&1 &" }& wait done echo "★★★Flume启动完成★★★" #保存退出