有许多场景下,我们需要进行跨服务器的数据整合,比如两个表之间,通过Id进行join操作,你必须确保所有具有相同id的数据整合到相同的块文件中。那么我们先说一下mapreduce的shuffle过程。
Mapreduce的shuffle的计算过程是在executor中划分mapper与reducer。Spark的Shuffling中有两个重要的压缩参数。spark.shuffle.compress true---是否将会将shuffle中outputs的过程进行压缩。将spark.io.compression.codec编码器设置为压缩数据,默认是true.同时,通过spark.shuffle.manager 来设置shuffle时的排序算法,有hash,sort,tungsten-sort。(用hash会快一点,我不需要排序啊~)
Hash Shuffle
使用hash散列有很多缺点,主要是因为每个Map task都会为每个reduce生成一份文件,所以最后就会有M * R个文件数量。那么如果在比较多的Map和Reduce的情况下就会出问题,输出缓冲区的大小,系统中打开文件的数量,创建和删除所有这些文件的速度都会受到影响。如下图:
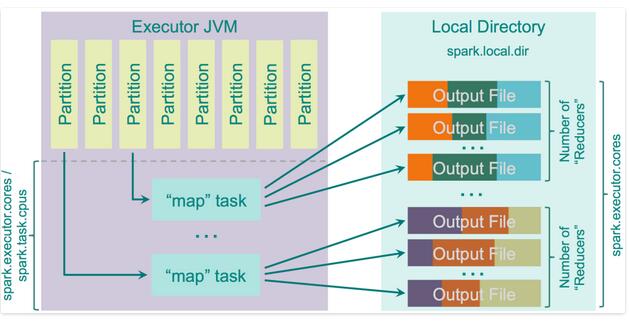
这里有一个优化的参数spark.shuffle.consolidateFiles,默认为false,当设置成true时,会对mapper output时的文件进行合并。如果你集群有E个executors(“-num-excutors”)以及C个cores("-executor-cores”),以及每个task又T个CPUs(“spark.task.cpus”),那么总共的execution的slot在集群上的个数就是E * C / T(也就是executor个数×CORE的数量/CPU个数)个,那么shuffle过程中所创建的文件就为E * C / T * R(也就是executor个数 × core的个数/CPU个数×reduce个数)个。外文文献写的太公式化,那么我用通俗易懂的形式阐述下。就好比总共的并行度是20(5个executor,4个task) Map阶段会将数据写入磁盘,当它完成时,他将会以reduce的个数来生成文件数。那么每个executor就只会计算core的数量/cpu个数的tasks.如果task数量大于总共集群并行度,那么将开启下一轮,轮询执行。
速度较快,因为没有再对中间结果进行排序,减少了reduce打开文件时的性能消耗。
当然,当数据是经过序列化以及压缩的。当重新读取文件,数据将进行解压缩与反序列化,这里reduce端数据的拉取有个参数spark.reducer.maxSizeInFlight(默认为48MB),它将决定每次数据从远程的executors中拉取大小。这个拉取过程是由5个并行的request,从不同的executor中拉取过来,从而提升了fetch的效率。 如果你加大了这个参数,那么reducers将会请求更多的文数据进来,它将提高性能,但是也会增加reduce时的内存开销。
Sort Shuffle
Sort Shuffle如同hash shuffle map写入磁盘,reduce拉取数据的一个性质,当在进行sort shuffle时,总共的reducers要小于spark.shuffle.sort.bypassMergeThrshold(默认为200),将会执行回退计划,使用hash将数据写入单独的文件中,然后将这些小文件聚集到一个文件中,从而加快了效率。(实现自BypassMergeSortShuffleWriter中)
那么它的实现逻辑是在reducer端合并mappers的输出结果。Spark在reduce端的排序是用了TimSort,它就是在reduce前,提前用算法进行了排序。 那么用算法的思想来说,合并的M N个元素进行排序,那么其复杂度为O(MNlogM) 具体算法不讲了~要慢慢看~
随之,当你没有足够的内存保存map的输出结果时,在溢出前,会将它们disk到磁盘,那么缓存到内存的大小便是 spark.shuffle.memoryFraction * spark.shuffle.safyFraction.默认的情况下是”JVM Heap Size * 0.2 * 0.8 = JVM Heap Size * 0.16”。需要注意的是,当你多个线程同时在一个executor中运行时(spark.executor.cores/spark.task.cpus 大于1的情况下),那么map output的每个task将会拥有 “JVM Heap Size * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction / spark.executor.cores * spark.task.cpus。运行原理如下图:
使用此种模式,会比使用hashing要慢一点,可通过bypassMergeThreshold找到集群的最快平衡点。
Tungsten Sort
使用此种排序方法的优点在于,操作的二进制数据不需要进行反序列化。它使用 sun.misc.Unsafe模式进行直接数据的复制,因为没有反序列化,所以直接是个字节数组。同时,它使用特殊的高效缓存器ShuffleExtemalSorter压记录与指针以及排序的分区id.只用了8 Bytes的空间的排序数组。这将会比使用CPU缓存要效率。
每个spill的数据、指针进行排序,输出到一个索引文件中。随后将这些partitions再次合并到一个输出文件中。
本文翻译自一位国外大神的博客:https://0x0fff.com/spark-memory-management/