引言
由于本节代码比较简单,就不上代码了,一切以截图为准
学习目标
- 了解Numpy运算速度上的优势
- 应用numpy的基本操作
开发工具
- python3.8
- jupyter notebook
1、numpy的介绍
Numpy(Numerical Python)是一个开源的Python科学计算库,用于快速处理任意维度的数组。
Numpy支持常见的数组和矩阵操作。对于同样的数值计算任务,使用Numpy比直接使用Python要简洁的多。
Numpy使用ndarray对象来处理多维数组,该对象是一个快速而灵活的大数据容器。
2、ndarray介绍
NumPy提供了一个N维数组类型ndarray,它描述了相同类型的“items”的集合。
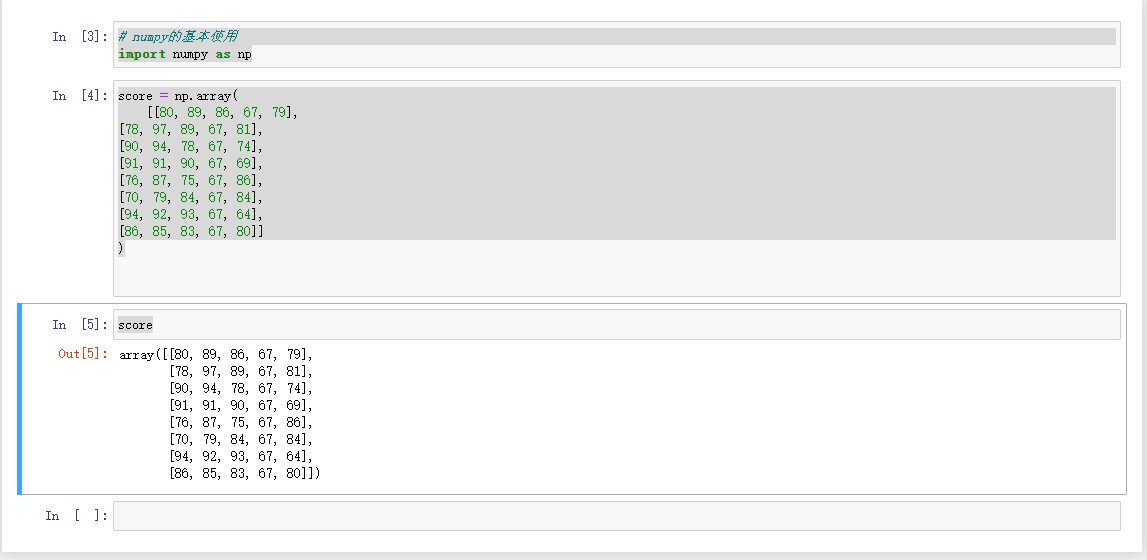
案例:用ndarray进行存储下列数据

# numpy的基本使用
import numpy as np
score = np.array(
[[80, 89, 86, 67, 79],
[78, 97, 89, 67, 81],
[90, 94, 78, 67, 74],
[91, 91, 90, 67, 69],
[76, 87, 75, 67, 86],
[70, 79, 84, 67, 84],
[94, 92, 93, 67, 64],
[86, 85, 83, 67, 80]]
)
score
3、ndarray的的优势
-
内存块风格
- ndarray在存储数据的时候,数据与数据的地址都是连续的,这样就给使得批量操作数组元素时速度更快。
- python原生list就只能通过寻址方式找到下一个元素
-
ndarray支持并行化运算(向量化运算):numpy内置了并行运算功能,当系统有多个核心时,做某种计算时,numpy会自动做并行计算
-
效率远高于纯Python代码:Numpy底层使用C语言编写,内部解除了GIL(全局解释器锁),其对数组的操作速度不受Python解释器的限制,所以,其效率远高于纯Python代码。
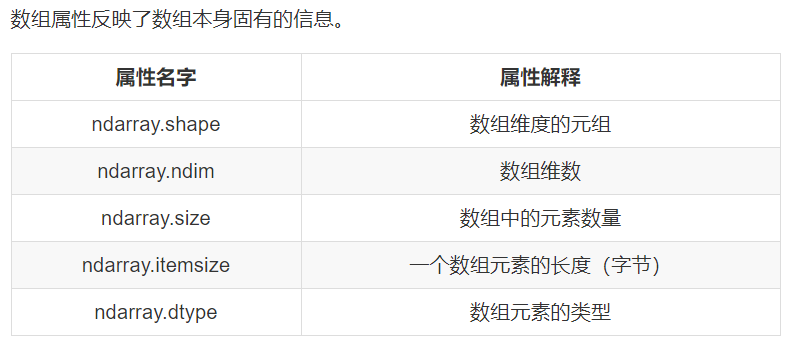
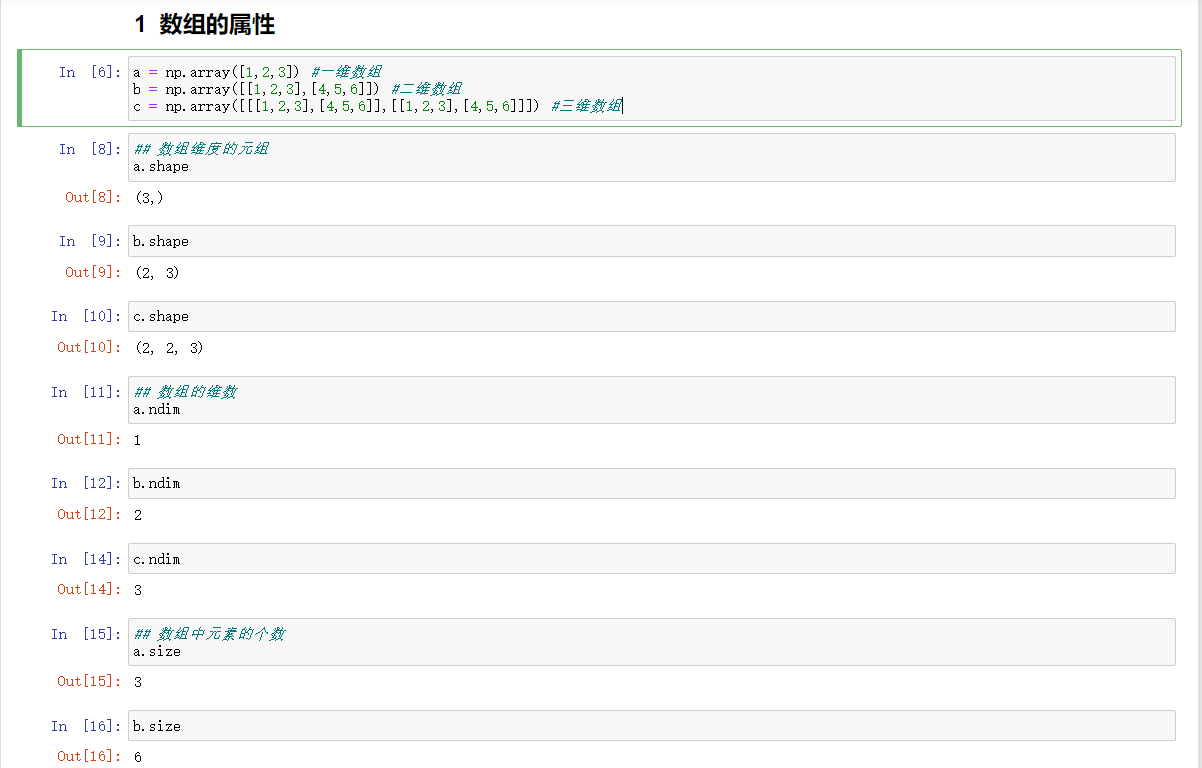
4、ndarray的属性
案例:代码简单,就不放了

5、基本操作
5.1生成0和1的数组(参数看上方属性)
- np.ones(shape, dtype)
- np.ones_like(a, dtype)
- np.zeros(shape, dtype)
- np.zeros_like(a, dtype)
生成0和1的数组 操作相同,只演示0的操作

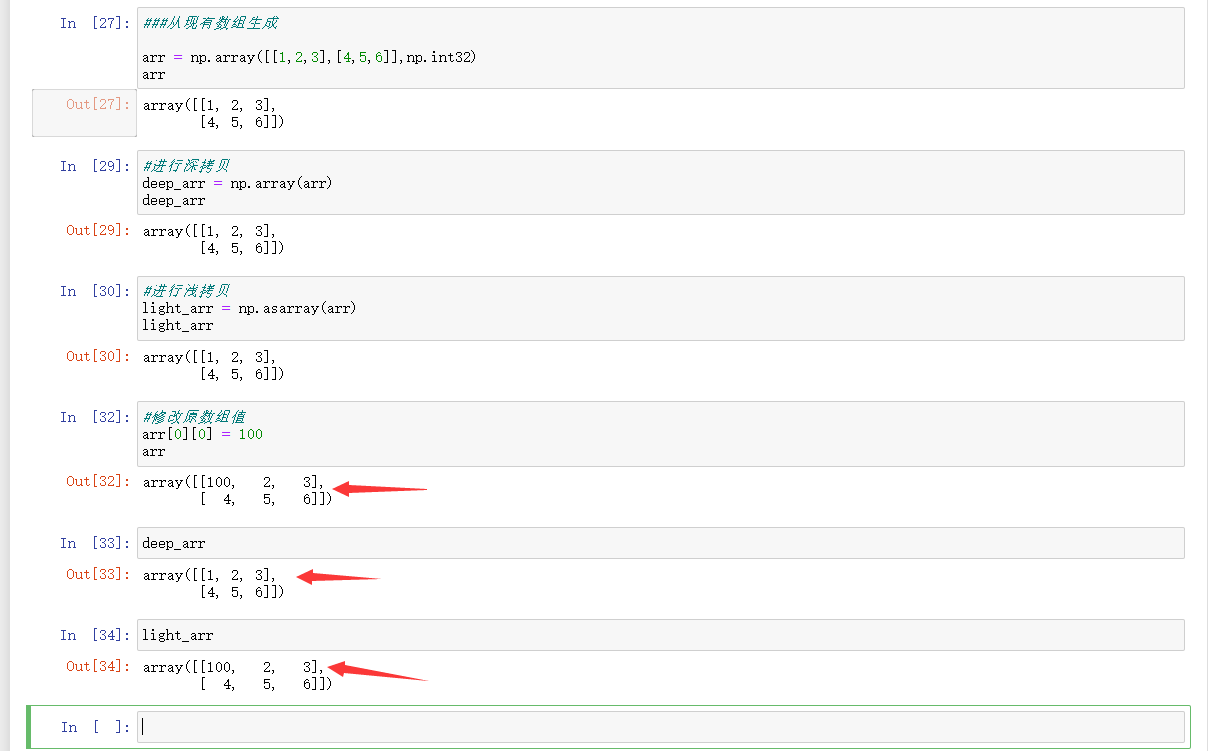
5.2从现有数组生成
- np.array(array, dtype) 深拷贝
- np.asarray(array, dtype) 浅拷贝
案例
5.3生成固定范围的数组
- np.linspace (start, stop, num, endpoint) 创建等差数组 — 指定数量
- start:序列的起始值
- stop:序列的终止值
- num:要生成的等间隔样例数量,默认为50
- endpoint:序列中是否包含stop值,默认为ture
- np.arange(start,stop, step, dtype) 创建等差数组 — 指定步长
- step:步长,默认值为1
- np.logspace(start,stop, num) 创建等比数列
- num:要生成的等比数列数量,默认为50
案例

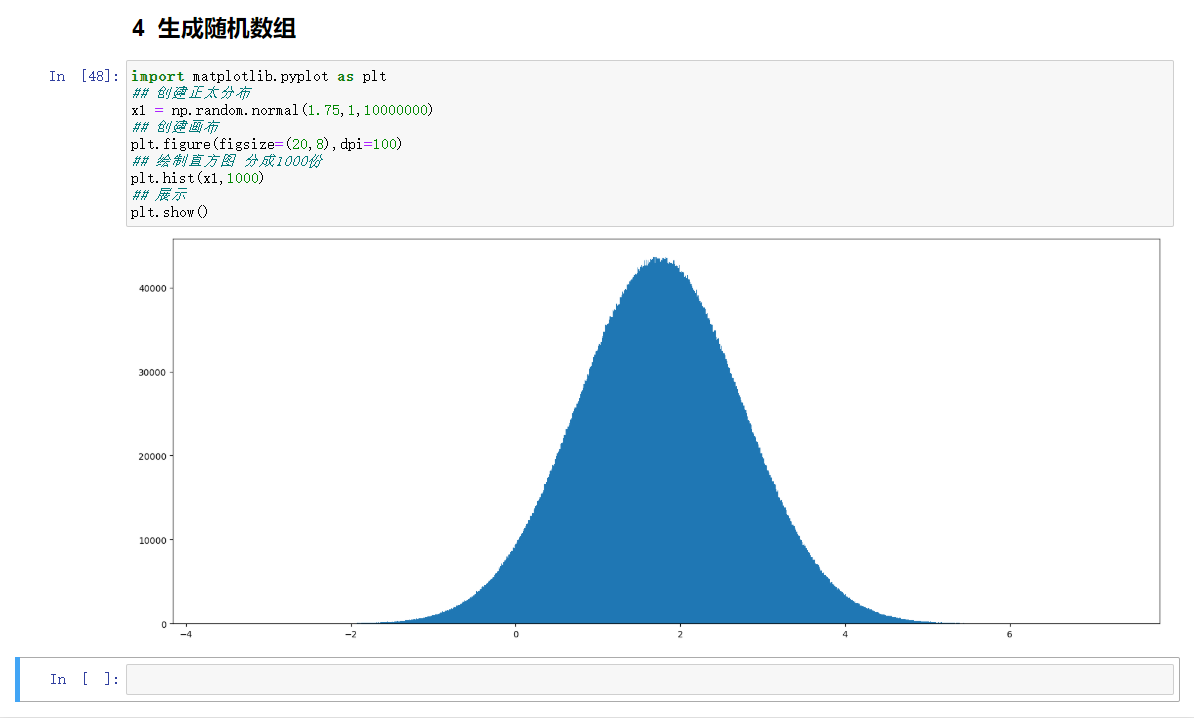
5.4生成随机数组
- np.random模块
- 创建正态分布 np.random.normal(loc=0.0, scale=1.0, size=None)
- loc:此概率分布的均值
- scale:此概率分布的标准差
- size:输出的shape,默认为None,只输出一个值
- 创建标准正态分布 np.random.standard_normal(size=None)
- 均匀分布np.random.uniform(low=0.0, high=1.0, size=None)
- low:采样下界,float类型,默认值为0
- high:采样上界,float类型,默认值为1
- size:输出样本数目,为int或元组(tuple)类型,例如,size=(m,n,k), 则输出mnk个样本,缺省时输出1个值。
- 创建正态分布 np.random.normal(loc=0.0, scale=1.0, size=None)
案例:成均值为1.75,标准差为1的正态分布数据,10000000个
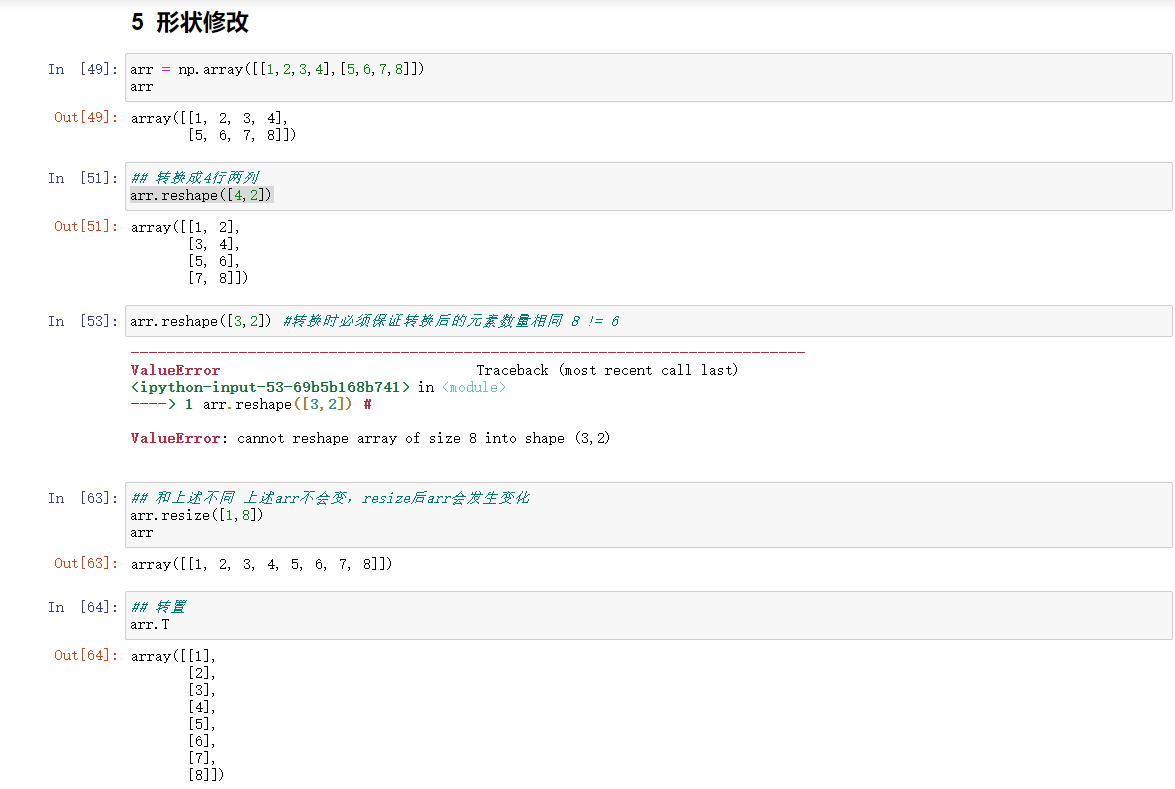
6、形状修改
- ndarray.reshape(shape, order)
- 返回一个具有相同数据域,但shape不一样的视图
- 行、列不进行互换
- ndarray.resize(new_shape)
- 修改数组本身的形状(需要保持元素个数前后相同)
- 行、列不进行互换
- ndarray.T
- 数组的转置
- 将数组的行、列进行互换
案例
7、类型修改
- ndarray.astype(type) 返回修改了类型之后的数组
- ndarray.tostring([order])或者ndarray.tobytes([order]) 构建一个包含ndarray的原始字节数据的字节字符串
8、去重
- np.unique(ndarray) 去掉重复数据,返回一个集合
案例

9、ndarray运算
逻辑运算:
案例:查询成绩大于60的
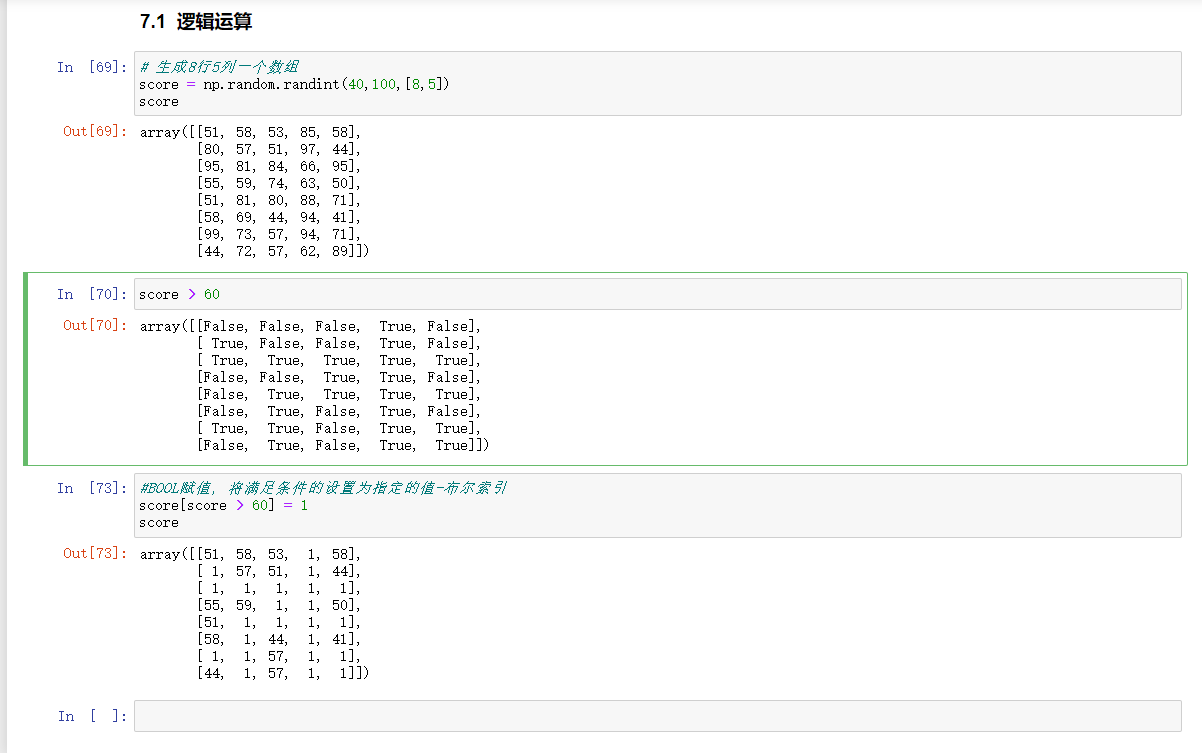
通用判断函数
- np.all() 判断所有
- np.any() 只要其中一个符合即可
案例:

三元运算符
- np.where(三元运算符)
- 复合逻辑需要结合np.logical_and和np.logical_or使用
案例
10、统计运算(具体看案例)
- min(a, axis) 最小数
- max(a, axis]) 最大数
- median(a, axis) 中位数
- mean(a, axis, dtype) 平均值
- std(a, axis, dtype)
- var(a, axis, dtype)
案例

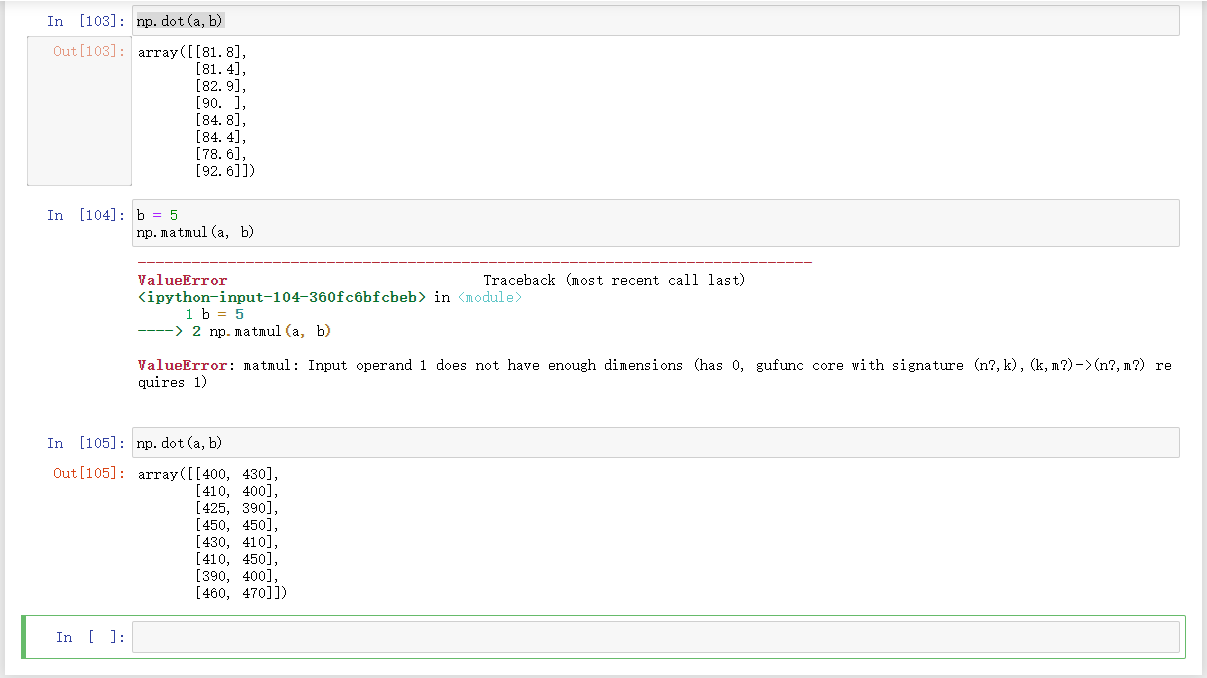
11、矩阵乘法
- np.matmul
- np.dot(可以实现矩阵和标量相乘)
案例