引言
品类是指产品的分类,大型电商网站品类分多级,咱们的项目中品类只有一级,不同的公司可能对热门的定义不一样。我们按照每个品类的点击、下单、支付的量来统计热门品类。如
鞋 点击数 下单数 支付数
衣服 点击数 下单数 支付数
电脑 点击数 下单数 支付数
本项目需求优化为:先按照点击数排名,靠前的就排名高;如果点击数相同,再比较下单数;下单数再相同,就比较支付数
正文
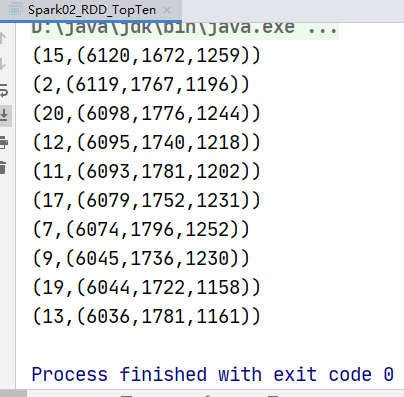
实现方案一
分别统计每个品类点击的次数,下单的次数和支付的次数:(品类,点击总数)(品类,下单总数)(品类,支付总数)
package com.xiao.spark.core.rdd.req
import org.apache.spark.rdd.RDD
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
object Spark01_Req01_TopTen {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("part")
val sc = new SparkContext(sparkConf)
val rdd: RDD[String] = sc.textFile("datas/user_visit_action.txt")
// 统计点击数量
val clickRDD: RDD[String] = rdd.filter {
line => {
val datas: Array[String] = line.split("_")
// 点击的品类 ID为-1,表示数据不是点击数据
datas(6) != "-1"
}
}
val clickCountRDD: RDD[(String, Int)] = clickRDD.map {
line => {
val datas: Array[String] = line.split("_")
// (id,1)
(datas(6), 1)
}
}.reduceByKey(_ + _)
// 统计下单数量
val orderRDD: RDD[String] = rdd.filter(
line => {
val datas: Array[String] = line.split("_")
// 本次不是下单行为,则数据采用 null 表示
datas(8) != "null"
}
)
// 扁平化映射: 因为一次下单可能有多个商品
// (id1,id2,id3) => (id1,1),(id2,1),(id3,1)
val orderCountRDD: RDD[(String, Int)] = orderRDD.flatMap(
line => {
val datas: Array[String] = line.split("_")
val cids: Array[String] = datas(8).split(",")
cids.map((_, 1))
}
).reduceByKey(_ + _)
// 统计支付数量
val payRDD: RDD[String] = rdd.filter(
line => {
val datas: Array[String] = line.split("_")
// 本次不是付行为,则数据采用 null 表示
datas(10) != "null"
}
)
// 扁平化映射: 因为一次下单可能有多个商品
// (id1,id2,id3) => (id1,1),(id2,1),(id3,1)
val payCountRDD: RDD[(String, Int)] = payRDD.flatMap(
line => {
val datas: Array[String] = line.split("_")
val cids: Array[String] = datas(10).split(",")
cids.map((_, 1))
}
).reduceByKey(_+_)
// 5. 将品类进行排序,并且取前10名
// 点击数量排序,下单数量排序,支付数量排序
// 元组排序:先比较第一个,再比较第二个,再比较第三个,依此类推
// ( 品类ID, ( 点击数量, 下单数量, 支付数量 ) )
//
val value: RDD[(String, (Iterable[Int], Iterable[Int], Iterable[Int]))] = clickCountRDD.cogroup(orderCountRDD, payCountRDD)
val analysisRDD: RDD[(String, (Int, Int, Int))] = value.mapValues {
case (clickIter, orderIter, payIter) => {
var clickCnt = 0
val cIter = clickIter.iterator
if (cIter.hasNext) {
clickCnt = cIter.next()
}
var orderCnt = 0
val oIter = orderIter.iterator
if (oIter.hasNext) {
orderCnt = oIter.next()
}
var payCnt = 0
val pIter = payIter.iterator
if (pIter.hasNext) {
payCnt = pIter.next()
}
(clickCnt, orderCnt, payCnt)
}
}
// 排序
val resultRDD: Array[(String, (Int, Int, Int))] = analysisRDD.sortBy(_._2, false).take(10)
resultRDD.foreach(println)
sc.stop()
}
}
运行结果:
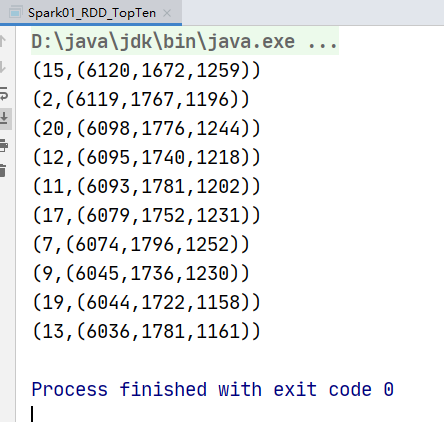
实现方案二
一次性统计每个品类点击的次数,下单的次数和支付的次数:(品类,(点击总数,下单总数,支付总数))
package com.xiao.spark.core.rdd.req
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark02_Req01_TopTen {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("part")
val sc = new SparkContext(sparkConf)
val rdd: RDD[String] = sc.textFile("datas/user_visit_action.txt")
rdd.cache()
// 统计点击数量
val clickRDD: RDD[String] = rdd.filter {
line => {
val datas: Array[String] = line.split("_")
// 点击的品类 ID为-1,表示数据不是点击数据
datas(6) != "-1"
}
}
val clickCountRDD: RDD[(String, (Int, Int, Int))] = clickRDD.map {
line => {
val datas: Array[String] = line.split("_")
// (id,1)
(datas(6), 1)
}
}.reduceByKey(_ + _).map {
case (id, count) => (id, (count, 0, 0))
}
// 统计下单数量
val orderRDD: RDD[String] = rdd.filter(
line => {
val datas: Array[String] = line.split("_")
// 本次不是下单行为,则数据采用 null 表示
datas(8) != "null"
}
)
// 扁平化映射: 因为一次下单可能有多个商品
// (id1,id2,id3) => (id1,1),(id2,1),(id3,1)
val orderCountRDD: RDD[(String, (Int,Int,Int))] = orderRDD.flatMap(
line => {
val datas: Array[String] = line.split("_")
val cids: Array[String] = datas(8).split(",")
cids.map((_, 1))
}
).reduceByKey(_ + _).map {
case (id, count) => (id, (0, count, 0))
}
// 统计支付数量
val payRDD: RDD[String] = rdd.filter(
line => {
val datas: Array[String] = line.split("_")
// 本次不是付行为,则数据采用 null 表示
datas(10) != "null"
}
)
// 扁平化映射: 因为一次下单可能有多个商品
// (id1,id2,id3) => (id1,1),(id2,1),(id3,1)
val payCountRDD: RDD[(String, (Int,Int,Int))] = payRDD.flatMap(
line => {
val datas: Array[String] = line.split("_")
val cids: Array[String] = datas(10).split(",")
cids.map((_, 1))
}
).reduceByKey(_+_).map {
case (id, count) => (id, (0, 0,count))
}
// 5. 聚合
// (品类ID, 点击数量) ==>( 品类ID, ( 点击数量, 0, 0 ) )
// (品类ID, 下单数量) ==>( 品类ID, ( 0, 下单数量, 0 ) )
// (品类ID, 支付数量) ==>( 品类ID, ( 0, 0, 支付数量 ) )
val value: RDD[(String, (Int, Int, Int))] = clickCountRDD.union(orderCountRDD).union(payCountRDD)
val resultRDD: RDD[(String, (Int, Int, Int))] = value.reduceByKey(
(t1, t2) => (t1._1 + t2._1, t1._2 + t2._2, t1._3 + t2._3)
)
resultRDD.sortBy(_._2,false).take(10).foreach(println)
sc.stop()
}
}
运行结果:
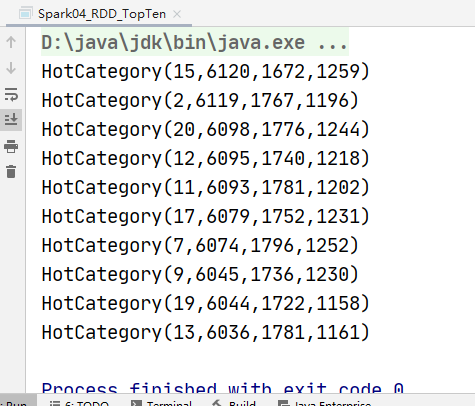
实现方案三:
使用累加器的方式聚合数据
package com.xiao.spark.core.rdd.req
import org.apache.spark.rdd.RDD
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
object Spark04_Req01_TopTen {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("part")
val sc = new SparkContext(sparkConf)
val rdd: RDD[String] = sc.textFile("datas/user_visit_action.txt")
val accumulator = new myAccumulator()
sc.register(accumulator)
rdd.foreach(
line => {
val datas: Array[String] = line.split("_")
if (datas(6) != "-1"){
accumulator.add((datas(6),"click"))
}else if(datas(8) != "null"){
val ids: Array[String] = datas(8).split(",")
ids.foreach(
id => {
accumulator.add((id,"order"))
}
)
}else if(datas(10) != "null"){
val ids: Array[String] = datas(10).split(",")
ids.foreach(
id => {
accumulator.add((id,"pay"))
}
)
}
}
)
// 只取hotCategor
val categories: mutable.Iterable[HotCategory] = accumulator.value.map(_._2)
// 自定义排序规则
categories.toList.sortWith(
(left,right) => {
if (left.clickCnt > right.clickCnt){
true
} else if(left.clickCnt == right.clickCnt){
if (left.orderCnt > right.orderCnt){
true
}else if(left.orderCnt == right.orderCnt){
left.payCnt > right.payCnt
}else{
false
}
}else{
false
}
}
).take(10).foreach(println)
sc.stop()
}
case class HotCategory(cid : String, var clickCnt : Int, var orderCnt : Int ,var payCnt : Int)
// 自定义累加器
class myAccumulator extends AccumulatorV2[(String,String),mutable.Map[String,HotCategory]] {
var hcMap = mutable.Map[String, HotCategory]()
override def isZero: Boolean = {
hcMap.isEmpty
}
override def copy(): AccumulatorV2[(String, String), mutable.Map[String, HotCategory]] = {
new myAccumulator()
}
override def reset(): Unit = {
hcMap.clear()
}
override def add(v: (String, String)): Unit = {
val category: HotCategory = hcMap.getOrElse(v._1, new HotCategory(v._1, 0, 0, 0))
if (v._2 == "click"){
category.clickCnt += 1
}else if (v._2 == "order"){
category.orderCnt += 1
}else if (v._2 == "pay"){
category.payCnt += 1
}
hcMap.update(v._1,category)
}
override def merge(other: AccumulatorV2[(String, String), mutable.Map[String, HotCategory]]): Unit = {
var map1 = this.hcMap
var map2 = other.value
map2.foreach{
case (cid,hc) =>{
val category: HotCategory = map1.getOrElse(cid, new HotCategory(cid, 0, 0, 0))
category.clickCnt += hc.clickCnt
category.orderCnt += hc.orderCnt
category.payCnt += hc.payCnt
map1.update(cid,category)
}
}
}
override def value: mutable.Map[String, HotCategory] = {
hcMap
}
}
}
运行结果: