如下:

Id: 每个select语句就会有一个对应的Id,值越大,其执行顺序越优先,由上面所示,总共有3个select语句
select_type:
primary: 复杂查询最外层的的查询
DERIVED: 衍生类型,如果from的语句是子查询,则这里就是衍生类型,衍生产生的表 <derived3> 其中的3就代表是顺序为3的语句产生的
SUBQUERY: select语句中的子查询,不是from后面的
table: 表名称,衍生表命名<derived n> 其中的3就代表是顺序为n的语句产生的
Type: 最重要的标识之一,简单可以认为他是标识本次查询的性能体现,sytem>const>eq_ref>ref>range>index>all 越往后,性能越低,sql至少要在range级别
const 和System:当使用主键或者唯一索引作为查询条件时,因为值是唯一的,就相当于常量

eq_ref: 唯一索引或者主键用于关联查询,其中索引部分所有的数据都能被关联,如下图:o表中的所有数据cod_order_id在i表中都有一条对应的记录

ref: 使用非唯一索引

range: 用到索引范围查询

index: 查询的字段从索引树中直接可以获取到,不用再回表查询

ALL: 全表扫描
possible_keys: sql经过查询优化器优化后,可能使用的索引
key: 执行sql最终使用的索引
key_len: 索引的长度,在联合索引中,可以判断哪些索引字段被使用了,长度公式:

ref: 索引作为条件查询时,用到的是常量值还是字段

rows: mysql预估要读取或者检测的行数
Extra: 拥有的值比较多,这里展示几个
Using index: 用到覆盖索引时,参考 type=index

Using where : 没有用到索引,到有where 条件语句

Using index condition:查询的列不完全被索引覆盖,where条件中是一个前导列的范围;

Using temporary:mysql需要创建一张临时表来处理查询。出现这种情况一般是要进行优化的,首先是想到用索
引来优化。

Using filesort:将用外部排序而不是索引排序,数据较小时从内存排序,否则需要在磁盘完成排序。这种情况下一
般也是要考虑使用索引来优化的。

尤其是后面这2种一定要优化
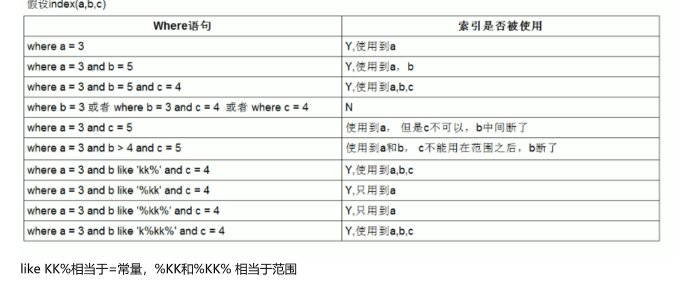
优化原则如上所示:
1. 不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
如: select * from employees where date(hire_time) ='2018‐09‐30'; 不走索引
2. 尽量使用覆盖索引(只访问索引的查询(索引列包含查询列)),减少 select * 语句
3. mysql在使用不等于(!=或者<>),not in ,not exists 的时候无法使用索引会导致全表扫描 < 小于、 > 大于、 <=、>= 这些,mysql内部优化器会根据检索比例、表大小等多个因素整体评估是否使用索引
4. is null,is not null 一般情况下也无法使用索引, is null在某些场景是可以使用索引的

5. 字符串不加单引号索引失效
6. 少用or或in,用它查询时,mysql不一定使用索引,mysql内部优化器会根据检索比例、表大小等多个因素整体评
估是否使用索引,详见范围查询优化

7. 范围查询优化,如果范围太大,也不会走索引(拆分来优化)
