8.1 循环神经网络简介
传统的机器学习算法非常依赖人工提取的特征,使得基于传统机器学习的图像识别、语音识别以及自然语言处理等问题存在特征提取的瓶颈。而基于全连接神经网络的方法存在参数太多、无法利用数据中时间序列信息等问题。循环神经网络具有挖掘数据中的时序信息以及语义信息的深度表达能力,在语音识别、语言模型、机器翻译以及时序分析等方面实现了突破。
循环神经网络的主要用途是处理和预测序列数据。在全连接神经网络和卷积神经网络中,网络结构都是从输入层到隐含层再到输出层,层与层之间是全连接或部分连接的,但每层之间的节点是无连接的。而循环神经网络隐藏层之间的节点是由连接的,隐藏层的输入不仅包括输入层的输出,还包括上一时刻隐藏层的输出。
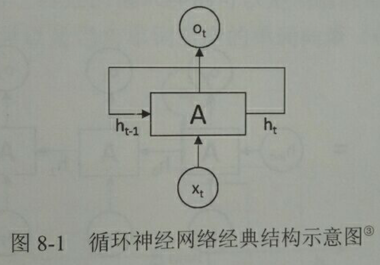
图8-1展示了一个典型的循环神经网络。
循环神经网络的主体结构A的输入除了来自输入层xt,还有一个循环的边来提供上一时刻的隐藏状态ht-1,在每一时刻,循环神经网络的模块A在读取了xt和ht-1之后会产生新的隐藏状态ht,并产生本时刻的输出ot。由于模块A中的运算和变量在不同时刻是相同的,因此可以被看作同一神经网络结构被无限复制的结果。正如卷积神经网络在不同空间位置共享参数,循环神经网络是在不同时间位置共享参数,从而能够使用有限的参数处理任意长度的序列。
将完整的输入输出展开,可以得到图8-2所展示的结构。
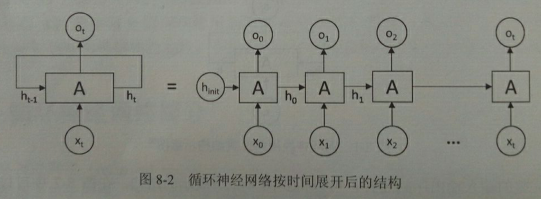
可以清楚地看到在每个时刻都有一个输入xt,然后根据循环神经网络前一时刻的状态ht-1计算新的状态ht,并输出ot。循环神经网络当前的状态ht是根据上一时刻的状态ht-1和当前的输入xt共同决定的。在时刻t,状态ht-1浓缩了前面序列x0, x1, …, xt-1的信息,用于作为输出ot的参考。由于序列的长度可以无限延长,维度有限的h状态不可能将序列的全部信息都保存下来,因为模型必须学习只保留与后面任务ot, ot+1 ,…相关的最重要信息。
循环网络的展开在模型训练中有重要意义。循环神经网络对长度为N的序列展开之后,可以视为一个有N个中间层的前馈神经网络。这个前馈神经网络没有循环连接,因此可以直接使用反向传播算法进行训练,而不需要任何特别的优化算法。这样的训练方法称为“沿时间反向传播”,是训练循环神经网络最常见的方法。
从循环神经网络的结构特征可以很容易地看出它最擅长解决与时间序列相关的问题,也是处理这类问题最自然的神经网络结构。对于一个序列数据,可以将这个序列上不同时刻的数据依次传入循环神经网络的输入层,而输出可以是对序列中下一个时刻的预测,也可以是对当前时刻信息的处理结果。循环神经网络要求每个时刻都有一个输入,但不一定每个时刻都要有输出。
图8-3展示的是实现机器翻译的示意图,
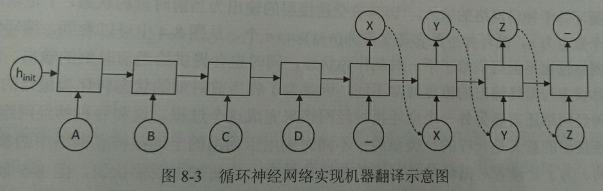
循环神经网络中每个时刻的输入为需要翻译的句子中的单词。假如需要翻译的句子为ABCD,那么第一阶段每个时刻的输入就分别为A、B、C、D,然后用'_'作为待翻译句子的结束符。在第一阶段,循环神经网络没有输出。从结束符'_'开始,循环神经网络进入翻译阶段。该阶段每个时刻的输入是上一时刻的输出,而最终得到的输出就是句子ABCD翻译的结果,当网络输出'_'时翻译结束。
循环神经网络可以看作是同一神经网络结构在时间序列上被复制多次的结果,这个被复制多次的结构被称为循环体。如何设计循环体的循环结构是循环神经网络解决实际问题的关键。
图8-4展示了一个最简单的循环体结构。这个循环体中只使用了一个类似全连接层的神经网络结构。

循环神经网络的前向传播流程,
循环神经网络中的状态是通过一个向量来表示的,这个向量的维度也称为循环神经网络隐藏层的大小,假设为n。
假设输入向量的维度为x,隐藏状态的维度为n,那么循环体的全连接神经网络的输入大小为x+n。因为该全连接层的输出为当前时刻的状态,于是输出层的节点个数也为n,所以循环体中的参数个数为(n+x)×n+n个。
循环体中的神经网络输出不但提供给了下一时刻作为状态,同时也会提供给当前时刻的输出。通常循环体状态与最终输出的维度不同,为了将当前时刻的状态转为最终的输出,还需要一个全连接层来完成这个过程。
图8-5展示了一个循环神经网络的前向传播过程,

1 import numpy as np 2 3 X = [1, 2] 4 # 初始化隐藏状态 5 state = [0.0, 0.0] 6 7 # 循环体参数 8 w_cell_state = np.asarray([[0.1, 0.2], [0.3, 0.4]]) 9 w_cell_input = np.asarray([0.5, 0.6]) 10 b_cell = np.asarray([0.1, -0.1]) 11 12 # 全连接层参数 13 w_output = np.asarray([[1.0], [2.0]]) 14 b_output = 0.1 15 16 # 前向传播过程 17 for i in range(len(X)): 18 before_activation = np.dot(state, w_cell_state) + X[i] * w_cell_input + b_cell 19 20 # 当前隐藏状态 21 state = np.tanh(before_activation) 22 23 # 最终输出 24 final_output = np.dot(state, w_output) + b_output 25 26 print(before_activation, state, final_output) 27 28 # 结果: 29 # [0.6 0.5] [0.53704957 0.46211716] [1.56128388] 30 # [1.2923401 1.39225678] [0.85973818 0.88366641] [2.72707101]
在得到循环神经网络的前向传播结果之后,可以和其他神经网络类似地定义损失函数。循环神经网络唯一的区别在于因为它每个时刻都有一个输出,所以循环神经网络的总损失为所有时刻(或部分时刻,例如图8-3的机器翻译模型中,在训练时总损失就是最后4个时刻('X'、'Y'、‘Z’、'_')的损失函数之和)上的损失函数之和。
理论上循环神经网络可以支持任意长度的序列,然而在实际训练过程中,如果序列过长,一方面会导致优化时出现梯度消失和梯度爆炸问题,另一方面,展开后的前馈神经网络会占用过大内存,所以实际中一般会规定一个最大长度,当序列长度查过规定长度之后会对序列进行截断。
8.2 长短时记忆网络
循环神经网络通过保存历史信息来帮助当前的决策,例如使用之前出现的单词来加强对当前文字的理解。循环神经网络可以更好地利用传统神经网络结构所不能建模的信息,但同时,这也带来了更大的技术挑战--长期依赖问题。
在有些问题中,模型仅仅需要短期内的信息来执行当前任务。相关信息和待预测词的位置之间的间隔很小,循环神经网络可以比较容易地利用先前信息。但在一些上下文场景更加复杂的情况中,当前预测位置和相关信息之间的文本间隔就有可能变的很大,类似图8-4给出的简单循环神经网络就可能会丧失学习到距离较远的信息的能力。或者在复杂语言场景中,有用信息的间隔有大有小、长短不一,循环神经网络的性能也会受到限制。长短时记忆网络的设计就是为了解决这个问题。在很多问题上,采用LSTM结构的循环神经网络比标准的循环神经网络表现更好。
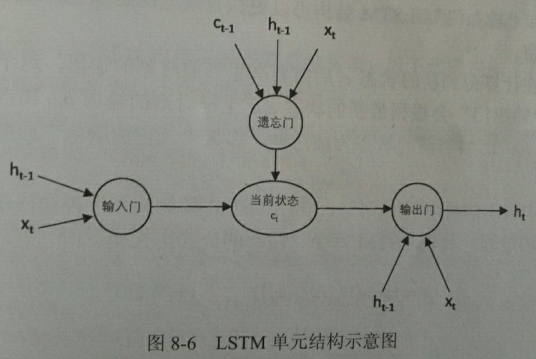
如图8-6所示,与单一的tanh循环结构不同,LSTM结构是一种拥有三个“门”结构的特殊网络结构:遗忘门、输入门、输出门。
LSTM靠一些“门”结构让信息有选择性地影响循环神经网络中每个时刻的状态。所谓“门”结构就是一个使用sigmoid神经网络和一个按位乘法的操作。该结构之所以叫做'门',是因为使用sigmoid作为激活函数的全链接神经网络层会输出一个0到1之间的数值,描述当前输入有多少信息量可以通过这个结构。当门打开时(sigmoid输出为1),全部信息可以通过;当门关闭时(sigmoid输出为0),任何信息都无法通过。
为了使循环神经网络更有效地保存长期记忆,遗忘门和输入门至关重要,它们是LSTM结构的核心。
遗忘门:遗忘门会根据当前的输入xt和上一时刻的输出ht-1来决定哪一部分记忆需要被遗忘。假设状态c的维度为n,则根据当前的输入xt和上一时刻输出ht-1计算一个维度为n的向量f=sigmoid(w1x + w2h),它在每一维度上的值都在(0, 1)范围内。再将上一时刻的状态ct-1与f向量按位相乘,那么f取值(是f取值还是相乘之后的取值??)接近0的维度上的信息就会被遗忘,而f取值接近1的维度上的信息会被保留。
输入门:在循环网络遗忘了部分之前的状态后,需要从当前的输入补充最新的记忆。这个过程就是输入门完成。输入门会根据当前输入xt和上一时刻输出ht-1决定哪些信息加入到状态ct-1中来生成新的状态ct。这时输入门和需要写入的新状态都从xt和ht-1计算产生。
输出门:LSTM结构在计算得到新的状态ct后,需要产生当前时刻的输出,这个过程是通过输出门完成的。输出门会根据最新状态ct、上一时刻的输出ht-1和当前时刻的输入xt来决定当前时刻的输出ht。
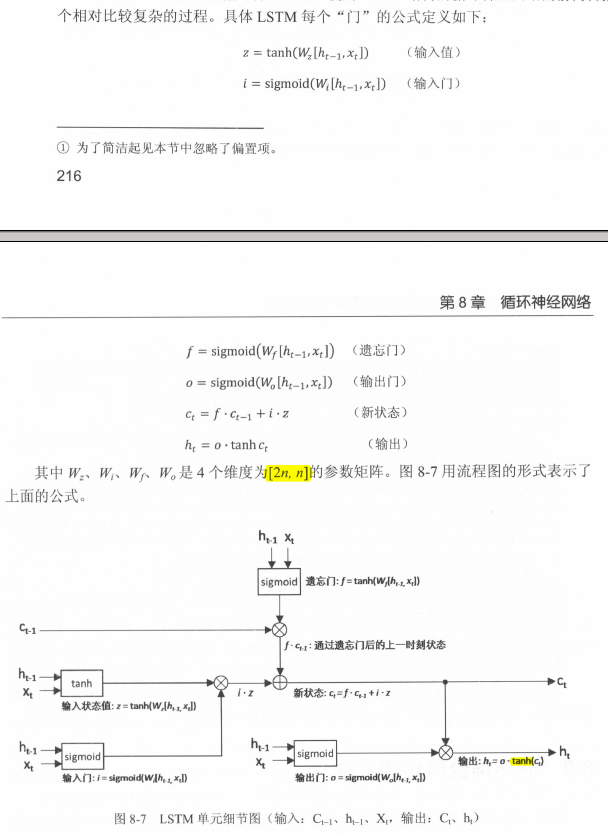
如图8-7,一个循环层的参数个数为4*2n*n。
LSTM循环神经网络的前向传播(实现思路):
该循环神经网络只有一个循环层,称为经典循环神经网络,后面会提到双向循环神经网络和深层循环神经网络。
1 #!coding:utf8 2 3 import tensorflow as tf 4 5 # 循环神经网络隐藏层大小 6 lstm_hidden_size = 2 7 # 一个batch 8 batch_size = 100 9 num_steps = 1000 10 11 # 定义一个LSMT结构,LSTM中使用的变量也会在该函数中自动被声明。 12 lstm = tf.nn.rnn_cell.LSTMCell(lstm_hidden_size) 13 # 将LSTM中的状态初始化为全0数组。
# state是一个包含了两个张量的LSTMStateTuple类,其中state.c和state.h分别为c状态和h状态。 14 # 和其他神经网络类似,在优化循环神经网络时,每次也会使用一个batch的训练样本。 15 state = lstm.zero_state(batch_size, tf.float32) 16 17 # 定义损失函数 18 loss = 0.0 19 20 # 虽然在测试时循环神经网络可以处理任意长度的序列,但是在训练中为了将循环为了展开为前馈神经网络,需要知道训练数据的序列长度。 21 # 暂时先用num_steps表示。之后会使用dynamic_rnn动态处理变长序列。 22 for i in range(num_steps): 23 # 在第一个时刻声明LSTM结构中使用的变量,在之后的时刻都需要复用之前定义好的变量。 24 if i > 0: 25 tf.get_variable_scope().reuse_variables() 26 27 # 每一步处理时间序列中的一个时刻。将当前输入和前一时刻的状态传入定义好的LSTM结构,可以得到当前LSTM的输出和更新后的状态。 28 lstm_output, state = lstm(current_input, state) 29 30 # 将当前时刻的输入传入一个全连接层得到最后的输出。 31 final_output = fully_connected(lstm_output) 32 # 计算当前时刻输出的损失 33 loss += calc_loss(final_output, expected_output)
8.3 循环神经网络的变种
8.3.1 双向循环神经网络和深层循环神经网络
在经典的循环神经网络中,状态的传输是从前往后单向的。然而,在有些问题中,当前时刻的输出不仅和之前的状态有关,也和之后的状态有关,这时就需要使用双向循环神经网络来解决这类问题。比如预测一个语句中缺失的单词不仅需要根据前文判断,也需要根据后面的内容,这时双向循环神经网络就可以发挥它的作用。
图8-8展示了一个双向循环神经网络的结构图。
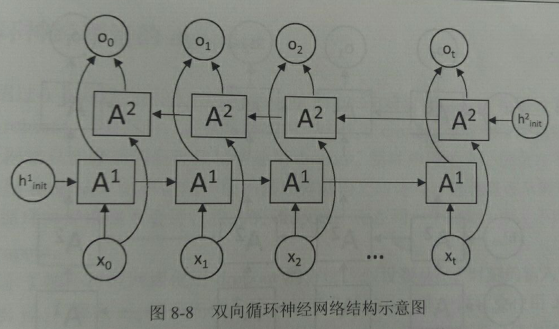
双向循环神经网络的主体结构就是两个单向循环神经网络的结合。在每个时刻t,输入会同时提供给两个方向相反的循环神经网络。这两个网络独立进行计算,各自产生该时刻的新状态和输出,而双向循环网络的最终输出是这两个单向循环神经网络的输出的简单拼接。两个循环网络除方向不同外,其他结构完全对称。每一层中的循环体可以自由选用任意结构,如前面介绍的简单RNN、LSTM。
深层循环神经网络:

为了增强模型的表达能力,可以在网络中设置多个循环层,将每层循环网络的输出传给下一层进行处理。每一层的循环体参数是一致的,不同层之间的参数可以不同。
利用MultiRNNCell类实现深层循环神经网络的前向传播过程,(与LSTM结构类似,只需在BasicLSTMCell的基础上再封装一层MultiRNNCell)
1 batch_size = 100 2 num_steps = 1000 3 loss = 0.0 4 5 # 从输入Xt到输出Ot需要多少个LSTM结构 6 number_of_layers = 5 7 # 隐藏层大小 8 lstm_size = 2 9 10 # 定义一个基本的LSTM结构作为循环体的基础结构 11 lstm_cell = tf.nn.rnn_cell.LSTMCell 12 13 # 实现深层神经网络中每一时刻的前向传播过程 14 stacked_lstm = tf.nn.rnn_cell.MultiRNNCell( 15 [lstm_cell(lstm_size) for _ in range(number_of_layers)] 16 ) 17 18 state = stacked_lstm.zero_state(batch_size, tf.float32) 19 # print(state) # 有number_of_layers个元素的元组,每个元素为一层的初始状态 20 21 for i in range(num_steps): 22 if i > 0: 23 tf.get_variable_scope().reuse_variables() 24 25 stacked_lstm_output, state = stacked_lstm(current_input, state) 26 final_output = fully_connected(stacked_lstm_output) 27 loss += calc_loss(final_output, expected_output)
8.3.2 循环神经网络的dropout
通过dropout,可以让卷积神经网络更加健壮,类似地,在循环神经网络中使用dropout也有同样的功能。而且,类似卷积神经网络只在最后的全连接层使用dropout,循环神经网络一般只在不同层循环体结构之间使用dropout,而不在同一层的循环体结构之间使用,即从时刻t-1传递到时刻t时,循环神经网络不会进行状态的dropout;而在同一时刻t中,不同层循环体之间会使用dropout。
tensorflow中实现带dropout的循环神经网络,
# 使用类DropoutWrapper类来实现dropout功能。
该类通过两个参数来控制dropout的概率,一个参数为input_keep_prob,用来控制输入的dropout概率;另一个参数为output_keep_prob,用来控制输出的dropout概率。
1 stacked_lstm = tf.nn.rnn_cell.MultiRNNCell( 2 # 不同层之间实现dropout 3 [tf.nn.rnn_cell.DropoutWrapper(lstm_cell(lstm_size)) for _ in range(number_of_layers)] 4 )
8.4 循环神经网络样例应用
以时序预测为例,利用循环神经网络对函数sin(x)取值进行预测。
循环神经网络预测的是离散时刻的取值,所以事前要进行离散化。离散化就是在一个给定的区间[0, MAX]内,通过有限个采样点模拟一个连续的曲线。
预测sin实例:
1). 使用了dataset组织数据
2). 使用了几个高层api:
tf.nn.dynamic_rnn
tf.contrib.layers.fully_connected
tf.losses.mean_squared_error
tf.contrib.layers.optimize_loss
1 #!coding:utf8 2 3 import tensorflow as tf 4 import numpy as np 5 6 # import matplotlib as mpl # 加上这两行反而不能可视化 7 # mpl.use('Agg') 8 from matplotlib import pyplot as plt # sudo apt-get install python3-tk 9 10 HIDDEN_SIZE = 30 # 隐藏层大小 11 NUM_LAYERS = 2 # LSTM的层数 12 13 TRAINING_EXAMPLES = 10000 # 训练数据个数 14 TESTING_EXAMPLES = 1000 # 测试数据个数 15 SAMPLE_GAP = 0.01 # 采样间隔 16 17 TIMESTEPS = 10 # 序列长度 18 TRAINING_STEPS = 10000 # 训练轮数 19 BATCH_SIZE = 32 20 21 22 def generate_data(seq): 23 X = [] 24 y = [] 25 for i in range(len(seq) - TIMESTEPS): 26 X.append([seq[i: i+TIMESTEPS]]) # 秩至少为3, 曾卡在这里过 27 y.append([seq[i+TIMESTEPS]]) 28 return np.array(X, np.float32), np.array(y, np.float32) 29 30 31 def lstm_model(X, y, is_training): 32 cell = tf.nn.rnn_cell.MultiRNNCell( 33 [tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE) for _ in range(NUM_LAYERS)] # HIDDEN_SIZE是生成隐藏状态的,与输入数据的维度无关。 34 ) 35 # print('X.shape:', X) # (32, 1, 10) 36 # 将多层LSTM结构连接成RNN网络并计算前向传播结果。 37 # outputs是顶层LSTM在每一步的输出(即最后的状态,输入全连接层,得到最后的输出),维度为[BATCH_SIZE, time, HIDDEN_SIZE], 在本问题中只关注最后一个时刻的输出 38 outputs, _ = tf.nn.dynamic_rnn(cell, X, dtype=tf.float32) # 输入X的秩至少为3 39 # print('outputs.shape:', outputs) # (32, 1, 30) 40 output = outputs[:, -1, :] 41 # print('output.shape', output) # (32, 30) 42 43 # 全连接层, 44 predictions = tf.contrib.layers.fully_connected(output, 1, activation_fn=None) # (32, 1) 45 46 # 只在训练时计算损失函数和优化步骤,测试时直接返回预测结构 47 if not is_training: 48 return predictions, None, None 49 50 # 损失函数 51 loss = tf.losses.mean_squared_error(labels=y, predictions=predictions) 52 53 # 创建模型优化器 54 train_op = tf.contrib.layers.optimize_loss( 55 loss, tf.train.get_global_step(), 56 optimizer='Adagrad', learning_rate=0.1 57 ) 58 return predictions, loss, train_op 59 60 61 def train(sess, train_X, train_y): 62 ds = tf.data.Dataset.from_tensor_slices((train_X, train_y)) 63 ds = ds.repeat().shuffle(1000).batch(BATCH_SIZE) 64 X, y = ds.make_one_shot_iterator().get_next() 65 66 with tf.variable_scope('model'): 67 predictions, loss, train_op = lstm_model(X, y, True) 68 69 tf.global_variables_initializer().run() 70 71 for i in range(TRAINING_STEPS): 72 # _, loss = sess.run([train_op, loss]) # TypeError: Fetch argument 0.51441383 has invalid type <class 'numpy.float32'>, must be a string or Tensor. (Can not convert a float32 into a Tensor or Operation.) 73 _, l = sess.run([train_op, loss]) # 在循环中,运算结果需要另有变量名接收,否则报错 74 if i % 100 == 0: 75 print('train step: ' + str(i) + ', loss: ', str(l)) 76 77 78 def run_eval(sess, test_X, test_y): 79 ds = tf.data.Dataset.from_tensor_slices((test_X, test_y)) 80 ds = ds.batch(1) # X.shape = (1, 1, 10) 81 X, y = ds.make_one_shot_iterator().get_next() 82 83 with tf.variable_scope('model', reuse=True): 84 prediction, _, _ = lstm_model(X, y, False) 85 86 # 将预测结构存入一个数组 87 predictions = [] 88 labels = [] 89 for i in range(TESTING_EXAMPLES): 90 # _, loss = sess.run([train_op, loss]) # TypeError: Fetch argument 0.51441383 has invalid type <class 'numpy.float32'>, must be a string or Tensor. (Can not convert a float32 into a Tensor or Operation.) 91 p, l = sess.run([prediction, y]) # 在循环中,运算结果需要另有变量名接收,否则报错 92 predictions.append(p) 93 labels.append(l) 94 95 predictions = np.array(predictions).squeeze() # 把维度为1的维度去掉 96 labels = np.array(labels).squeeze() 97 rmse1 = np.sqrt(((predictions - labels)**2).mean(axis=0)) # 均方根误差 98 # rmse2 = tf.losses.mean_squared_error(labels=labels, predictions=predictions) # 均方误差 99 print(rmse1) 100 # print(rmse2.eval()) 101 # print(rmse1**2) 102 103 plt.figure() 104 plt.plot(predictions, label='predictions') 105 plt.plot(labels, label='label') 106 plt.legend() 107 plt.show() 108 109 test_start = (TRAINING_EXAMPLES + TIMESTEPS) * SAMPLE_GAP # 100.1 110 test_end = test_start + (TESTING_EXAMPLES + TIMESTEPS) * SAMPLE_GAP # 110.2 111 112 train_X, train_y = generate_data(np.sin(np.linspace( 113 0, test_start, TRAINING_EXAMPLES + TIMESTEPS, dtype=np.float32))) 114 test_X, test_y = generate_data(np.sin(np.linspace( 115 test_start, test_end, TESTING_EXAMPLES + TIMESTEPS, dtype=np.float32))) 116 117 with tf.Session() as sess: 118 train(sess, train_X, train_y) 119 run_eval(sess, test_X, test_y)