SVM is capable of performing linear or nonlinear classification,regression,and even outlier detection. SVMs are particularly well suited for classification of complex but small- or medium-sized datasets.
Linear SVM Classification:
Soft Margin Classification
the fundamental idea behind SVMs is best explained with some pictures.
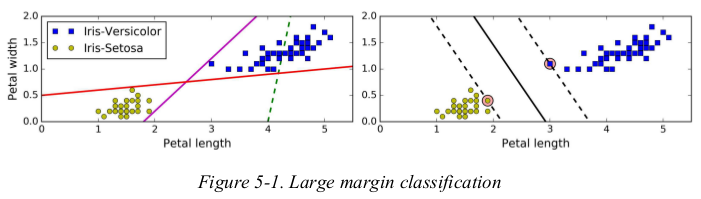
the solid line in the plot on the right represents the decision boundary of an SVM classifier;this line not only separates the two classes but also stays as far away from the closest training instances as possible. you can think of an SVM classifier as fitting the widest possible street(represented by the parallel dashed lines) between the classes. this is called large margin classification.
adding more training instances “off the street” will not affect the decision boundary at all: it is fully determined by the instances located on the edge of the street. these instances are called the support vectors. (they are circled in Figure5-1)
warning: SVMs are sensitive to the features scales,as you can see in Figure5-2: on the left plot,the vertical scale is much larger than the horizontal scale,so the widest possible street is close to horizontal. after feature scaling,the decision boundary looks much better(on the right polt).

Soft Margin Classification:
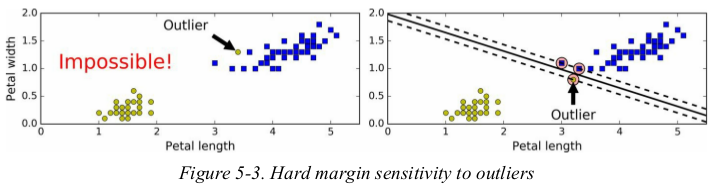
if we strictly impose that all instances be off the street and on the right side(严格要求所有实例都不在街上且都在正确的一边),this is called hard margin classification. there are two main issues with hard margin classification. first,it only works if the data is linearly separable,and second it is quite sensitive to outliers. Figure 5-3 shows the iris dataset with just one additional outlier: on the left,it is impossible to find a hard margin,and on the right the decision boundary ends up very different from the one we saw in Figure 5-1 without the outlier,and it will probably not generalize as well.
to avoid these issues it is preferable to use a more flexible model. the objective is to find a good balance between keeping the street as large as possible and limiting the margin violations(i.e., instances that end up in the middle of the street or even on the wrong side). this is called soft margin classification.
in Scikit-Learn's SVM classes,you can control this balance using the C hyperparameter: a smaller C value leads to a wider street but more margin violations.
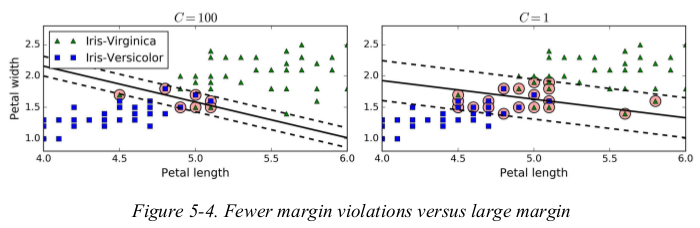
Figure 5-4 shows the decision boundaries and margins of two soft margin SVM classifiers on a nonlinearly separable dataset. on the left,using a high C value the classifier makes fewer margin violations but ends up with a smaller margin. on the right,using a low C value the margin is much larger,but many instances end up on the street. however,it seems likely that the second classifier will generalize better: in fact even on this training set it makes fewer prediction errors,since most of the margin violations are actually on the correct side of the decision boundary.
if your SVM model is overfitting,you can try regularizing it by reducing C.
1 from sklearn.svm import LinearSVC 2 3 iris = datasets.load_iris() 4 X = iris['data'][:, (2, 3)] 5 y = (iris['target'] == 2).astype(np.float64) 6 7 svm_clf = Pipeline([ 8 ('scaler', StandardScaler()), 9 ('linear_svc', LinearSVC(C=1, loss='hinge')), 10 ]) 11 svm_clf.fit(X, y) 12 13 print(svm_clf.predict([[5.5, 1.7]])) # [1.]
unlike Logistic Regression classifiers,SVM classifiers don't output probabilities for each class.
alternatively,you could use the SGDClassifier class,with SGDClassifier(loss="hinge", alpha=1/(m*C)). this applies regular Stochastic Gradient Descent to train a linear SVM classifier. it doesn't converge as fast as the LinearSVC class,but it can be useful to handle huge datasets that don't fit in memory,or to handle online classification tasks.
the LinearSVC class regularizes the bias term,so you should center the training set first by subtracting its mean. this is automatic if you scale the data using the StandardScaler.
moreover,make sure you set the loss hyperparameter to “hinge”,as it not the default value. finally,for better performance you should set the dual hyperparameter to False,unless there are more features than training instances. 不让设置dual=False??
Nonlinear SVM Classification:
Polynomial Kernel
Adding Similarity Features
Guassian RBF Kernel
Computational Complexity
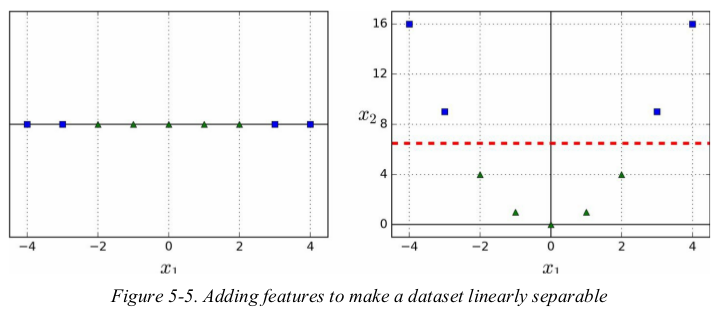
one approach to handling nonlinear datasets is to add more features,such as polynomial features;in some cases this can result in a linearly separable dataset. consider the left plot in Figure 5-5: it represents a simple dataset with just one feature x1. this dataset is not linearly separable,but if you add a second feature x2 = (x1)2,the resulting 2D dataset is perfectly linear separable.
示例:
1 from sklearn.pipeline import Pipeline 2 from sklearn.preprocessing import PolynomialFeatures, StandardScaler 3 from sklearn.svm import LinearSVC 4 5 X, y = datasets.make_moons(n_samples=100, noise=0.15, random_state=42) 6 7 polynomial_svm_clf = Pipeline([ 8 ('poly_features', PolynomialFeatures(degree=3)), 9 ('scaler', StandardScaler()), 10 ('svm_clf', LinearSVC(loss='hinge', C=10, random_state=42)) 11 ]) 12 polynomial_svm_clf.fit(X, y) 13 14 15 def plot_dataset(X, y, axes): 16 plt.plot(X[:, 0][y == 0], X[:, 1][y == 0], "bs") 17 plt.plot(X[:, 0][y == 1], X[:, 1][y == 1], "g^") 18 plt.axis(axes) 19 plt.grid(True, which='both') 20 plt.xlabel(r"$x_1$", fontsize=20) 21 plt.ylabel(r"$x_2$", fontsize=20, rotation=0) 22 23 24 def plot_predictions(clf, axes): 25 x0s = np.linspace(axes[0], axes[1], 100) 26 x1s = np.linspace(axes[2], axes[3], 100) 27 x0, x1 = np.meshgrid(x0s, x1s) 28 X = np.c_[x0.ravel(), x1.ravel()] 29 y_pred = clf.predict(X).reshape(x0.shape) 30 y_decision = clf.decision_function(X).reshape(x0.shape) 31 plt.contourf(x0, x1, y_pred, cmap=plt.cm.brg, alpha=0.2) 32 plt.contourf(x0, x1, y_decision, cmap=plt.cm.brg, alpha=0.1) 33 34 35 plot_predictions(polynomial_svm_clf, [-1.5, 2.5, -1, 1.5]) 36 plot_dataset(X, y, [-1.5, 2.5, -1, 1.5]) 37 plt.show()
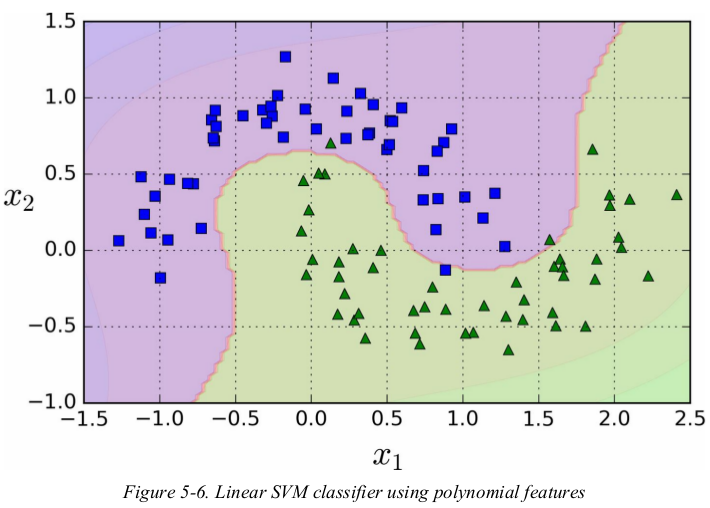
polynomial kernel:
adding polynomial features is simple to implement and can work great with all sorts of Machine Learning algorithms (not just SVMs),but at a low polynomial degree it can't deal with very complex datasets,and with a high polynomial degree it creates a huge number of features,making the model too slow.
fortunately,when using SVMs you can apply an almost miraculous mathematical technique called the kernel trick. it makes it possible to get the same result as if you added many polynomial features,even with very high-degree polynomial,without actually having to add them. so there is no combinatorial explosion of the number of features since you don't actually add any features. this trick is implemented by the SVC class.
1 from sklearn.pipeline import Pipeline 2 from sklearn.svm import SVC 3 4 X, y = datasets.make_moons(n_samples=100, noise=0.15, random_state=42) 5 6 poly_kernel_svm_clf = Pipeline([ 7 ('scaler', StandardScaler()), 8 ('svm_clf', SVC(kernel='poly', degree=3, coef0=1, C=5)), 9 ]) 10 poly_kernel_svm_clf.fit(X, y)
the hyperparameter coef0 controls how much the model is influenced by high-degree polynomials versus low-degree polynomials.
Adding Similarity Features:
another technique to tackle nonlinear problems is to add features computed using a similarity function that measures how much each instance resembles a particular landmark.
for example,let's take the one-dimensional dataset and add two landmarks to it at x1 = -2 and x1 = 1. next,let's define the similarity function to be the Gaussian Radial Basis Function (RBF) with γ = 0.3.(see Equation 5-1)
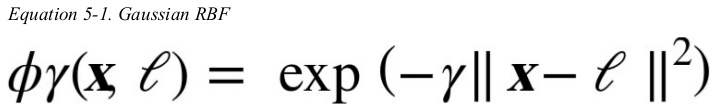
it is a bell-shaped function varying from 0 to 1. now we are ready to compute the new features. for example,let's look at the instance x1 = -1: it is located at a distance of 1 from the first landmark,and 2 from the second landmark. therefore its new features are ![]() the plot on the right of Figure 5-8 shows the transformed dataset. it is now linearly separable.
the plot on the right of Figure 5-8 shows the transformed dataset. it is now linearly separable.

you may wonder how to select the landmarks. the simplest approach is to create a landmark at the location of each and every instance in the dataset. this creates many dimensions and thus increases the chances that the transformed training set will be linearly separable.
Gaussian RBF Kernel:
just like the polynomial features method,the similarity features method can be useful with any Machine Learning algorithm,but it may be computationally expensive to compute all the additional features,especially on large training sets. however,once again the kernel trick does its SVM magic:
1 from sklearn.svm import SVC 2 3 X, y = datasets.make_moons(n_samples=100, noise=0.15, random_state=42) 4 5 rbf_kernel_svm_clf = Pipeline([ 6 ('scaler', StandardScaler()), 7 ('svm_clf', SVC(kernel='rbf', gamma=5, C=0.001)), 8 ]) 9 rbf_kernel_svm_clf.fit(X, y)
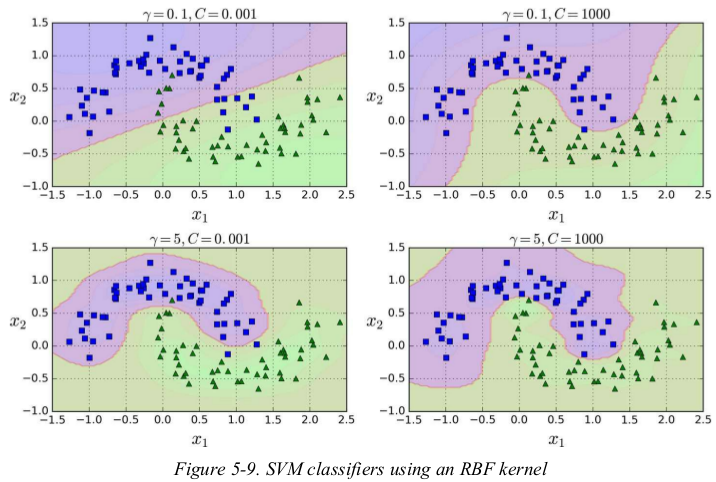
increasing gamma makes the bell-shape curve narrower,the decision boundary ends up being more irregular,wiggling around individual instances. conversely,a small gamma value makes the bell-shaped curve wider,so instances have a larger range of influence,and the decision boundary ends up smoother. so gamma acts like a regularization hyperparameter: if your model is overfitting,you should reduce it,and if it is underfitting,you should increase it (similar to the C hyperparameter).
with so many kernels to choose from,how can you decide which one to use?as a rule of thumb,you should always try the linear kernel first (remember that LinearSVC is much faster than SVC(kernel=“linear”)),especially if the training set is very large or if it has plenty of features. if the training set is not too large,you should try the Gaussian RBF kernel as well;it works well in most cases. then if you have spare time and computing power,you can also experiment with a few other kernels using cross-validation and grid search,especially if there are kernels specialized for your training set's data structure.
Computational Complexity:
the LinearSVC class is based on the liblinear library,which implements an optimized algorithm for linear SVMs. it doesn't support the kernel trick,but it scales almost linearly with the number of training instances and the number of features: its training time complexity is roughly O(m × n).
the algorithm takes longer if you require a very high precision. this is controlled by the tolerance hyperparameter (called tol in Scikit-Learn). in most classification tasks,the default tolerance is fine.
the SVC class is based on the libsvm library,which implements an algorithm that supports the kernel trick. the training time complexity is usually between O(m2 × n) and O(m2 × n). unfortunately,this means that it gets dreadfully slow when the number of training instances gets large. this algorithm is perfect for complex but small or medium training set. however,it scales well with the number of features,especially with sparse features. in this case,the algorithm scales roughly with the average number of nonzero features per instance.

SVM Regression
与分类任务的目标相反: instead of trying to fit the largest possible street between two classes while limiting margin violations,SVM Regression tries to fit as many instances as possible on the street while limiting margin violations(i.e., instances off the street). the width of the street is controlled by a hyperparameter ε.
1 from sklearn.svm import LinearSVR 2 3 X, y = datasets.make_moons(n_samples=100, noise=0.15, random_state=42) 4 5 svm_reg = LinearSVR(epsilon=1.5) 6 svm_reg.fit(X, y)
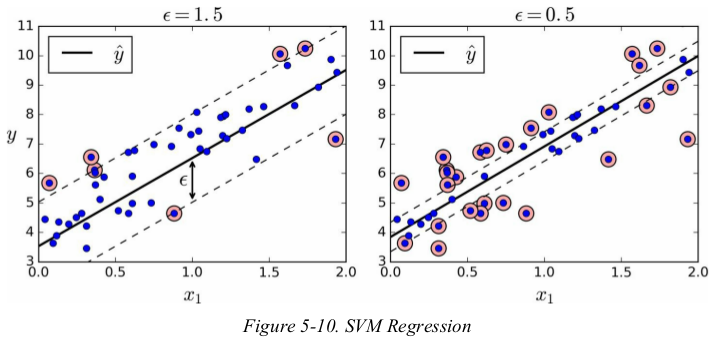
adding more training instances within the margin doesn't affect the model's predictions;thus,the model is said to be ε-insensitive.
you can use Scikit-Learn's LinearSVR class to perform linear SVM Regression.
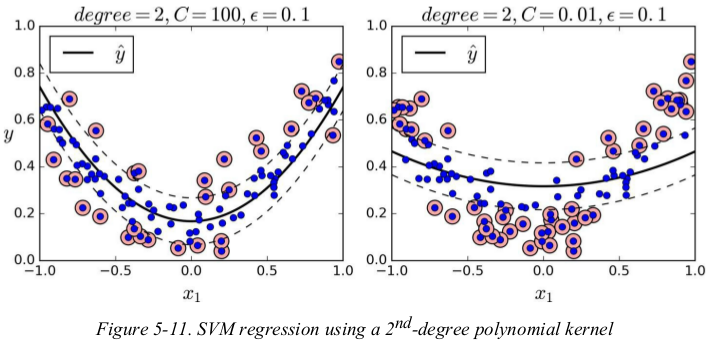
to tackle nonlinear regression tasks,you can use a kernelized SVM model. for example,Figure 5-11 shows SVM Regression on a random quadratic training set,using 2-degree polynomial kernel. there is little regularization on the left plot(i.e., a large C value),and much more regularization on the right plot(i.e., a small C value).
1 from sklearn.svm import SVR 2 3 X, y = datasets.make_moons(n_samples=100, noise=0.15, random_state=42) 4 5 svm_reg = SVR(kernel='poly', degree=2, C=100, epsilon=0.1) 6 svm_reg.fit(X, y)
Under the Hood: 还没看??
Decision Function and Predictions
Training Objective
Decision Function and Predictions:
the linear SVM classifier model predicts the class of a new instance x by simply computing the decision function:
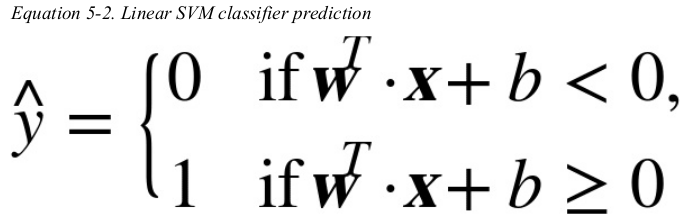
Training Objective:
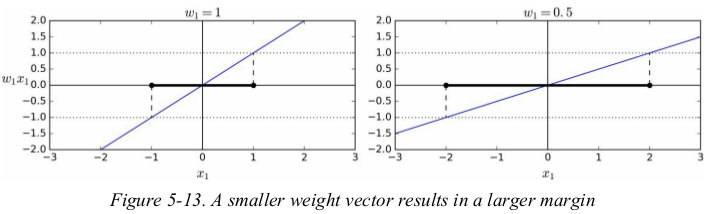
consider the slope of the decision function: it is equal to the norm of the weight vector,// w //. if we divide this slope by 2,the points where the decision function is equal to ±1 are going to be twice as far away from the decision boundary. in other words,dividing the slope by 2 will multiply the margin by 2. 还是没搞明白??
Exercises:
1. What is the fundamental idea behind Support Vector Machines?
soft margin,
use kernels when training on nonlinear datasets.
2. What is a support vector?
including any instance located on the “street”
3. Why is it important to scale the inputs when using SVMs?
SVMs try to fit the largest possible “street” between the classes,so if the training set is not scaled,the SVMs will tend to neglect small features.
4. Can an SVM classifier output a confidence score when it classifies an instance? What about a probability?
if you set probability=True when creating an SVM in Scikit-Learn,then after training it will calibrate the probabilities using Logistic Regression on the SVM's scores(trained by an additional five-fold cross-validation on the training data). this will add the predict_proba() and predict_log_proba() methods to the SVM.
5. Should you use the primal or the dual form of the SVM problem to train a model on a training set with millions of instances and hundreds of features?
7. How should you set the QP parameters (H, f, A, and b) to solve the soft margin linear SVM classifier problem using an off-the-shelf QP solver?
8. Train a LinearSVC on a linearly separable dataset. Then train an SVC and a SGDClassifier on the same dataset. See if you can get them to produce roughly the same model.
1 from sklearn.svm import LinearSVC, SVC 2 from sklearn.linear_model import SGDClassifier 3 4 iris = datasets.load_iris() 5 X = iris["data"][:, (2, 3)] # petal length, petal width 6 y = iris["target"] 7 8 setosa_or_versicolor = (y == 0) | (y == 1) 9 X = X[setosa_or_versicolor] 10 y = y[setosa_or_versicolor] 11 12 C = 5 13 alpha = 1 / (C * len(X)) 14 15 lin_clf = LinearSVC(loss='hinge', C=C, random_state=42) 16 svm_clf = SVC(kernel='linear', C=C) 17 sgd_clf = SGDClassifier(loss='hinge', learning_rate='constant', eta0=0.001, alpha=alpha, 18 max_iter=100000, tol=-np.infty, random_state=42) 19 20 scaler = StandardScaler() 21 X_scaled = scaler.fit_transform(X) 22 23 lin_clf.fit(X_scaled, y) 24 svm_clf.fit(X_scaled, y) 25 sgd_clf.fit(X_scaled, y) 26 27 print(lin_clf.intercept_, lin_clf.coef_) 28 print(svm_clf.intercept_, lin_clf.coef_) 29 print(sgd_clf.intercept_, sgd_clf.coef_) 30 # [0.28474272] [[1.05364736 1.09903308]] 31 # [0.31896852] [[1.05364736 1.09903308]] 32 # [0.319] [[1.12072936 1.02666842]]
9. Train an SVM classifier on the MNIST dataset. Since SVM classifiers are binary classifiers, you will need to use one-versus-all to classify all 10 digits. You may want to tune the hyperparameters
using small validation sets to speed up the process. What accuracy can you reach?
1 from sklearn.svm import LinearSVC, SVC 2 from sklearn.metrics import accuracy_score 3 4 mnist = datasets.fetch_openml('mnist_784', version=1, cache=True) 5 6 X = mnist["data"] 7 y = mnist["target"] 8 9 X_train = X[:60000] 10 y_train = y[:60000] 11 X_test = X[60000:] 12 y_test = y[60000:] 13 14 np.random.seed(42) 15 rnd_idx = np.random.permutation(60000) 16 X_train = X_train[rnd_idx] 17 y_train = y_train[rnd_idx] 18 19 scaler = StandardScaler() 20 X_train_scaled = scaler.fit_transform(X_train) 21 X_test_scaled = scaler.transform(X_test) 22 23 # lin_clf = LinearSVC(random_state=42) 24 # lin_clf.fit(X_train, y_train) 25 # y_pred = lin_clf.predict(X_train) 26 # print(accuracy_score(y_train, y_pred)) #0.8946 27 28 # 仅标准化就能提高准确率 29 # lin_clf = LinearSVC(random_state=42) # from scratch 30 # y_pred = lin_clf.fit(X_train_scaled, y_train) 31 # y_pred = lin_clf.predict(X_train_scaled) 32 # print(accuracy_score(y_train, y_pred)) # 0.9215166666666667 33 34 # 即使数据少了,准确率仍然提高了 35 # svm_clf = SVC(decision_function_shape='ovr', gamma='auto') # OvR 或 OvO,创建多个二分类分类器 36 # svm_clf.fit(X_train_scaled[:10000], y_train[:10000]) 37 # y_pred = svm_clf.predict(X_train_scaled) 38 # print(accuracy_score(y_train, y_pred)) # 0.9476 39 40 # 调参,使用很少的数据进行,之后再从头开始训练 41 from sklearn.model_selection import RandomizedSearchCV 42 from scipy.stats import reciprocal, uniform 43 44 svm_clf = SVC(decision_function_shape='ovr', gamma='auto') 45 param_distributions = {'gamma': reciprocal(0.001, 0.1), 'C': uniform(1, 10)} 46 rnd_search_cv = RandomizedSearchCV(svm_clf, param_distributions, n_iter=10, verbose=2, cv=3) 47 rnd_search_cv.fit(X_train_scaled[:1000], y_train[:1000]) 48 print(rnd_search_cv.best_score_) # 0.864 49 print(rnd_search_cv.best_params_) 50 rnd_search_cv.best_estimator_.fit(X_train_scaled, y_train) 51 y_pred = rnd_search_cv.best_estimator_.predict(X_train_scaled) 52 print(accuracy_score(y_train, y_pred)) # 0.99965 53 y_pred = rnd_search_cv.best_estimator_.predict(X_test_scaled) 54 print(accuracy_score(y_test, y_pred)) # 0.9728
10. Train an SVM regressor on the California housing dataset.
1 import numpy as np 2 from sklearn.datasets import fetch_california_housing 3 from sklearn.model_selection import train_test_split 4 from sklearn.preprocessing import StandardScaler 5 from sklearn.svm import LinearSVR 6 from sklearn.metrics import mean_squared_error 7 from sklearn.model_selection import RandomizedSearchCV 8 9 from sklearn.svm import SVR 10 from scipy.stats import reciprocal, uniform 11 12 housing = fetch_california_housing() 13 X = housing['data'] 14 y = housing['target'] 15 16 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) 17 18 scaler = StandardScaler() 19 X_train_scaled = scaler.fit_transform(X_train) 20 X_test_scaled = scaler.transform(X_test) 21 22 lin_svr = LinearSVR(random_state=42) 23 lin_svr.fit(X_train_scaled, y_train) 24 25 y_pred = lin_svr.predict(X_train_scaled) 26 mse = mean_squared_error(y_train, y_pred) 27 print(mse) # 0.949968822217229 28 print(np.sqrt(mse)) # 0.9746634404845752 29 30 31 param_distributions = {'gamma': reciprocal(0.001, 0.1), 'C': uniform(1, 10)} 32 rnd_search_cv = RandomizedSearchCV(SVR(), param_distributions, n_iter=10, verbose=2, cv=3, random_state=42) 33 rnd_search_cv.fit(X_train_scaled, y_train) 34 y_pred = rnd_search_cv.best_estimator_.predict(X_train_scaled) 35 mse = mean_squared_error(y_train, y_pred) 36 print(np.sqrt(mse)) # 0.5727524770785356 37 38 y_pred = rnd_search_cv.best_estimator_.predict(X_test_scaled) 39 mse = mean_squared_error(y_test, y_pred) 40 print(np.sqrt(mse)) # 0.592916838552874
1 # capable of performing linear or nonlinear classification, regression, and even outlier detection. 2 # particularly well suited for classification of complex but small- or medium-sized datasets. 3 4 # Linear SVM Classification 5 # not only separates the these classes but also stays as far away from the closest training instances as possible. large margin classification. 6 # 7 # Notice that adding more training instances “off the street” will not affect the decision boundary at all: 8 # it is fully determined (or “supported”) by the instances located on the edge of the street. These instances are called the support vectors. 9 # 10 # SVMs are sensitive to the feature scales. 11 12 ## Soft Margin Classification, 软间隔 13 # hard margin classification, strictly impose(严格规定) that all instances be off the street and on the right(正确的) side. 14 # There are two main issues with hard margin classification. First, it only works if the data is linearly separable, and second it is quite sensitive to outliers. 15 # 16 # soft margin classification, find a good balance between keeping the street as large as possible and limiting the margin violations (i.e., 17 # instances that end up in the middle of the street or even on the wrong side). 18 # control this balance using the C hyperparameter: a smaller C value leads to a wider street but more margin violations. 19 # Figure5-4 shows the decision boundaries(决策边界) and margins of two soft margin SVM classifiers on a nonlinearly separable dataset. 20 # 右图 makes fewer prediction errors, since most of the margin violations are actually on the correct side of the decision boundary. 21 22 import numpy as np 23 from sklearn import datasets 24 from sklearn.pipeline import Pipeline 25 from sklearn.preprocessing import StandardScaler, PolynomialFeatures 26 from sklearn.svm import LinearSVC, SVC, LinearSVR, SVR 27 28 iris = datasets.load_iris() 29 X = iris['data'][:, (2, 3)] 30 y = (iris['target'] == 2).astype(np.float64) 31 # svm_clf = Pipeline([ 32 # ('std_scale', StandardScaler()), 33 # ('linear_svc', LinearSVC(C=1, loss='hinge')) 34 # ]) 35 # svm_clf.fit(X, y) 36 # print(svm_clf.predict([[5.5, 1.7]])) # [1.] 37 # Unlike Logistic Regression classifiers, SVM classifiers do not output probabilities for each class. 38 39 # 也可以使用: SGDClassifier(loss="hinge", alpha=1/(m*C)) 40 # It does not converge as fast as the LinearSVC class, but it can be useful to handle huge datasets that do not fit in memory (out-of-core training), or to handle online classification tasks. 41 42 # The LinearSVC class regularizes the bias term, so you should center the training set first by subtracting its mean. This is automatic if you scale the data using the StandardScaler. 43 # Moreover, make sure you set the loss hyperparameter to "hinge", as it is not the default value. 44 # Finally, for better performance you should set the `dual` hyperparameter to False, unless there are more features than training instances. 45 46 47 # Nonlinear SVM Classification 48 # 线性不可分变为线性可分: One approach to handling nonlinear datasets is to add more features, such as polynomial features; in some cases this can result in a linearly separable dataset. # `this`指添加更多特征、 49 # polynomial_svm_clf = Pipeline([ 50 # ('poly_features', PolynomialFeatures(degree=3)), 51 # ('std_scale', StandardScaler()), 52 # ('linear_svc', LinearSVC(C=10, loss='hinge')) 53 # ]) 54 # polynomial_svm_clf.fit(X, y) 55 # print(polynomial_svm_clf.predict([[5.5, 1.7]])) # [1.] 56 57 58 ## Polynomial Kernel 59 # at a low polynomial degree it cannot deal with very complex datasets, and with a high polynomial degree it creates a huge number of features, making the model too slow. 60 # kernel trick, It makes it possible to get the same result as if you added many polynomial features, even with very high-degree polynomials, without actually having to add them. 61 # The `coef0` controls how much the model is influenced by high-degree polynomials versus lowdegree polynomials. 62 # poly_kernel_svm_clf = Pipeline([ 63 # ('scaler', StandardScaler()), 64 # ('svm_clf', SVC(kernel='poly', degree=3, coef0=1, C=5)) 65 # ]) 66 # poly_kernel_svm_clf.fit(X, y) 67 68 69 ## Adding Similarity Features 70 # Another technique to tackle nonlinear problems is to add features computed using a similarity function that measures how much each instance resembles a particular landmark. 71 # 步骤, 1. take a dataset and add some landmarks to it 72 # 2. define the similarity function 73 # 3. compute the new features,有公式。之后数据线性可分。 74 75 # how to select the landmarks? The simplest approach is to create a landmark at the location of each and every instance in the dataset. 76 # This creates many dimensions and thus increases the chances that the transformed training set will be linearly separable. 77 # The downside is that a training set with m instances and n features gets transformed into a training set with m instances and m features (assuming you drop the original features). 78 # If your training set is very large, you end up with an equally large number of features. 79 # the kernel trick又用到了, it may be computationally expensive to compute all the additional features, especially on large training sets. 80 81 82 ## Gaussian RBF Kernel 83 # rbf_kernel_svm_clf = Pipeline([ 84 # ('scaler', StandardScaler()), 85 # ('svm_clf', SVC(kernel='rbf', gamma=5, C=0.001)) 86 # ]) 87 # rbf_kernel_svm_clf.fit(X, y) 88 # Increasing gamma makes the bell-shape curve narrower and as a result each instance’s range of influence is smaller: 89 # the decision boundary ends up being more irregular, wiggling around individual instances. So γ acts like a regularization hyperparameter: 90 # if your model is overfitting, you should reduce it, and if it is underfitting, you should increase it (similar to the C hyperparameter). # 这里的C就是正则化参数。 91 92 # kernel的选择, 93 # 1. you should always try the linear kernel first. 94 # 2. If the training set is not too large, you should try the Gaussian RBF kernel as well; it works well in most cases. 95 # 3. Then if you have spare time and computing power, you can also experiment with a few other kernels using cross-validation and grid search, especially if there are kernels specialized for your training set’s data structure. 96 97 ## Computational Complexity 98 # The LinearSVC class is based on the liblinear library, which implements an optimized algorithm for linear SVMs. 99 # It does not support the kernel trick, but it scales almost linearly with the number of training instances and the number of features: its training time complexity is roughly O(m × n). 100 101 # The SVC class is based on the libsvm library, which implements an algorithm that supports the kernel trick. 102 # The training time complexity is usually between O(m2 × n) and O(m3 × n). Unfortunately, this means that it gets dreadfully slow when the number of training instances gets large. 103 # This algorithm is perfect for complex but small or medium training sets. 104 # However, it scales well with the number of features, especially with sparse features (i.e., when each instance has few nonzero features). In this case, the algorithm scales roughly with the average number of nonzero features per instance. 105 106 # Table5-1. Comparison of Scikit-Learn classes for SVM classification 107 108 109 # SVM Regression 110 # instead of trying to fit the largest possible street between two classes while limiting margin violations, 111 # SVM Regression tries to fit as many instances as possible on the street while limiting margin violations. 112 113 # The width of the street is controlled by a hyperparameter ϵ. Figure5-10, ϵ是间隔线与决策边界在y轴方向上的长度。 114 # Adding more training instances within the margin does not affect the model’s predictions; thus, the model is said to be ϵ-insensitive. 115 116 # the training data should be scaled and centered first. 117 svm_reg = LinearSVR(epsilon=1.5) 118 svm_reg.fit(X, y) 119 # To tackle nonlinear regression tasks, you can use a kernelized SVM model. 120 # 正则化参数,大小变化与分类时一致 121 122 # The LinearSVR class scales linearly with the size of the training set (just like the LinearSVC class), 123 # while the SVR class gets much too slow when the training set grows large (just like the SVC class). 124 # supports the kernel trick. 125 svm_poly_reg = SVR(kernel='poly', degree=2, C=100, epsilon=0.1) 126 svm_poly_reg.fit(X, y) 127 128 # 支持核方法的是: SVC、SVR. 129 130 # 处理异常值, 131 # SVMs can also be used for outlier detection; see Scikit-Learn’s documentation for more details. 132 133 134 # Under the Hood 135 ## Decision Function and Predictions 136 # Training a linear SVM classifier means finding the value of w and b that make this margin as wide as possible 137 # while avoiding margin violations (hard margin) or limiting them (soft margin). 138 139 ## Training Objective 140 # the slope of the decision function is equal to the norm of the weight vector, ∥ w ∥. If we divide this slope by 2, 141 # the points where the decision function is equal to ±1 are going to be twice as far away from the decision boundary. 142 # So we want to minimize ∥ w ∥ to get a large margin. 143 # 144 # hard margin, 145 # Equation5-3, We are minimizing 1/2·wT · w, which is equal to 1/2·∥ w ∥2, rather than minimizing ∥ w ∥. 146 # This is because it will give the same result (since the values of w and b that minimize a value also minimize half of its square), 147 # but 1/2·∥ w ∥2 has a nice and simple derivative (it is just w) while ∥ w ∥ is not differentiable at w = 0. 148 # Optimization algorithms work much better on differentiable functions. 149 # 150 # soft margin, 151 # Equation5-4, ζ(i) measures how much the i^th instance is allowed to violate the margin. 152 # We now have two conflicting objectives: making the slack variables as small as possible to reduce the margin violations, and making 1/2·wT · w as small as possible to increase the margin. 153 # the tradeoff between these two objectives: C hyperparameter. 154 155 ## Quadratic Programming, 二次规划 156 # The hard margin and soft margin problems are both convex quadratic optimization problems with linear constraints. 157 # Many off-the-shelf solvers are available to solve QP problems. 158 159 ## The Dual Problem, 对偶问题 160 # Given a constrained optimization problem, known as the `primal problem`, it is possible to express a different but closely related problem, called its `dual problem`. 161 # The solution to the dual problem typically gives a lower bound to the solution of the primal problem, but under some conditions it can even have the same solutions as the primal problem. 162 # Luckily, the SVM problem happens to meet these conditions, so you can choose to solve the primal problem or the dual problem; both will have the same solution. 163 164 # The dual problem is faster to solve than the primal when the number of training instances is smaller than the number of features. More importantly, 165 # it makes the kernel trick possible, while the primal does not. 166 167 ## Kernelized SVM, 核化支持向量机 168 169 ## Online SVMs 170 # online learning means learning incrementally, typically as new instances arrive. 171 172 ## hinge loss 173 # max(0, 1 – t). It is equal to 0 when t ≥ 1. 174 # Its derivative (slope) is equal to –1 if t < 1 and 0 if t > 1. 175 # It is not differentiable at t = 1, but just like for Lasso Regression you can still use Gradient Descent using any subderivative at t = 0 (i.e., any value between –1 and 0).