一、注意点
- Azkaban内置的任务类型支持command、java
- 目前,Azkaban上传的工作流文件只支持xxx.zip文件。zip应包含xxx.job运行作业所需的文件和任何文件(文件名后缀必须以.job结尾,否则无法识别)。作业名称在项目中必须是唯一的。
- 如果命令过于复杂,特别时带 >>追加操作的,需要用 bash -c 来执行
接下来从几个案例来介绍Azkaban该如何使用
二、多个简单job串联
1、需求
第一个job:创建一个文件夹
第二,三个job并行:在文件夹中创建分别创建一个空文件
第四个job:追加内容到这俩个空文件中
2、创建job文件
#start.job type=command command= mkdir /home/guigu/MyTest
#step1.job type=command dependencies=start command= touch /home/guigu/MyTest/a.txt
#step2.job type=command dependencies=start command= touch /home/guigu/MyTest/b.txt
#end.job type=command dependencies=step1,step2 command= bash -c 'echo 111 >> /home/guigu/MyTest/a.txt && echo 222 >> /home/guigu/MyTest/b.txt'
这里因为都是些简单的shell命令,所以type为command,依赖关系需要添加正确!另外所有文件后缀必须为job
3、web端上传job
1.先将所有job文件打包为***.zip压缩包
2.在web端新建一个project

3.上传zip压缩包

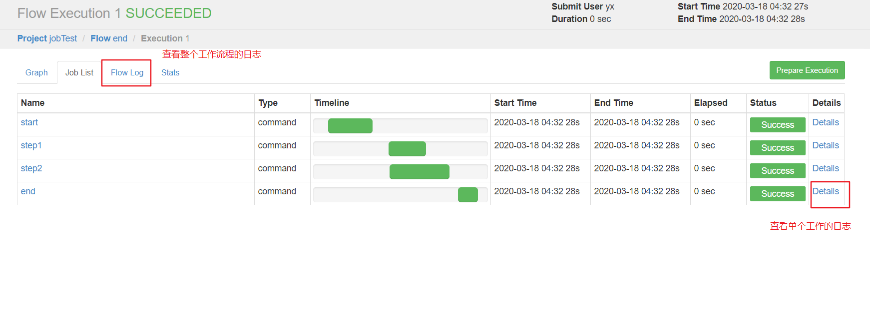
4、执行工作流程


5、查看相关信息
三、执行Java程序
1、编写Java程序并打包上传到Linux上
代码示例
public class FOSTest { public static void main(String[] args) { FileOutputStream fos = null; try { fos = new FileOutputStream("/home/guigu/data.txt"); fos.write("i am code".getBytes()); } catch (IOException e) { e.printStackTrace(); }finally { try { fos.close(); } catch (IOException e) { e.printStackTrace(); } } } }
2、编写job文件
type=javaprocess #main方法所在类 java.class=Consumer.FOSTest #jar包路径 classpath=/home/guigu/custom-1.0-SNAPSHOT.jar
如果将jar包与job文件一起上传,那么写相对路径也可
3、将job文件压缩上传到web端并运行
四、运行Map Reduce任务
1、确保hdfs 及 yarn 已经开启
2、编写job文件
#mapreduce job type=command command=/opt/module/hadoop-2.7.2/bin/hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /wordcount/input /wordcount/output
3、打包上传
五、运行hive任务
1、先创建sql文件
use default; drop table if exists student; create table student(id int, name string) row format delimited fields terminated by ' '; load data local inpath '/home/guigu/dept.txt' into table student; insert overwrite local directory '/home/guigu/hive_result' row format delimited fields terminated by ' ' select * from student;
2、再编写job文件
type=command command=hive -f myhql.sql
3、将sql文件和job文件打包上传并运行
六、定时调度任务
1、编写job文件
如果命令过于复杂,特别时带 >>追加操作的,需要用 bash -c 来执行
type=command
command=bash -c 'date >> /home/guigu/mydate.txt'
2、打包上传运行时选择调度

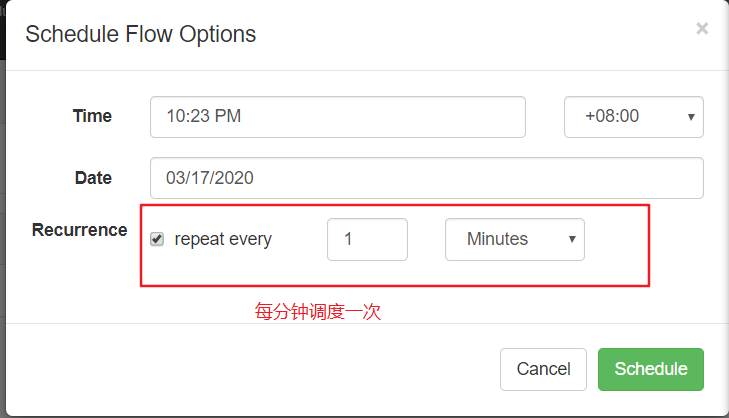
3、设置调度周期
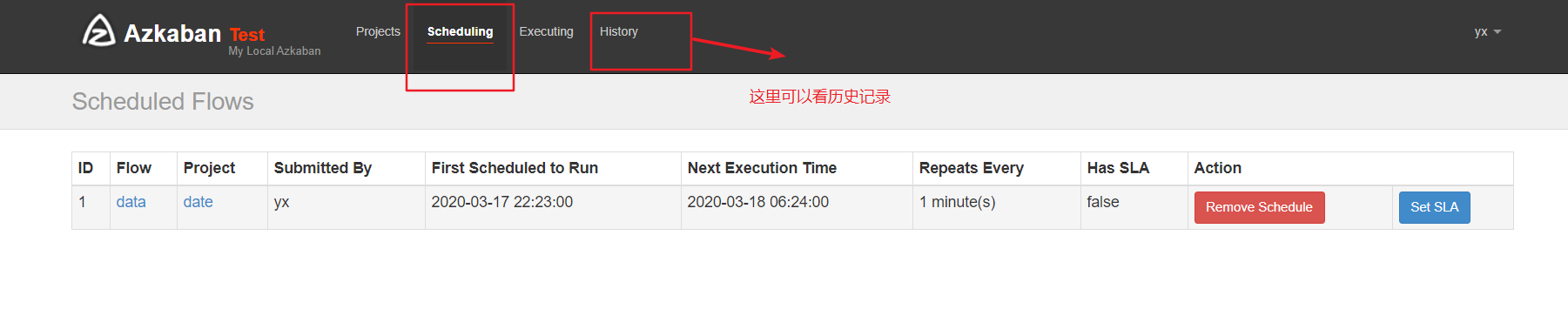
4、查看
七、给job任务传参数
1、job文件如下

2、运行时传入参数
注意 调用参数需要使用 $ { }
