环境准备
- MySQL(开启binlog)
- Kafka(使用内嵌式debezium则不需要)
- debezium连接器
官网参考 https://debezium.io/documentation/reference/1.3/tutorial.html
在 Kafka 环境下安装 debezium 连接器
把 从官网下载的mysql 连接器 上传到Kafka 服务器上并解压,我的解压路径为 /opt/kafka/plugins/debezium-connector-mysql
然后在 /opt/kafka/config/connect-distribute.properties 中编辑
note: 因为是分布式环境,所以配置connect-distribute.properties
## # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. ## # This file contains some of the configurations for the Kafka Connect distributed worker. This file is intended # to be used with the examples, and some settings may differ from those used in a production system, especially # the `bootstrap.servers` and those specifying replication factors. # A list of host/port pairs to use for establishing the initial connection to the Kafka cluster. bootstrap.servers=kafka1:9092,kafka2:9093,kafka3:9094 # unique name for the cluster, used in forming the Connect cluster group. Note that this must not conflict with consumer group IDs group.id=connect-cluster # The converters specify the format of data in Kafka and how to translate it into Connect data. Every Connect user will # need to configure these based on the format they want their data in when loaded from or stored into Kafka key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter # Converter-specific settings can be passed in by prefixing the Converter's setting with the converter we want to apply # it to key.converter.schemas.enable=true # 这个配置开启之后会附带schema 信息 value.converter.schemas.enable=true # Topic to use for storing offsets. This topic should have many partitions and be replicated and compacted. # Kafka Connect will attempt to create the topic automatically when needed, but you can always manually create # the topic before starting Kafka Connect if a specific topic configuration is needed. # Most users will want to use the built-in default replication factor of 3 or in some cases even specify a larger value. # Since this means there must be at least as many brokers as the maximum replication factor used, we'd like to be able # to run this example on a single-broker cluster and so here we instead set the replication factor to 1. offset.storage.topic=connect-offsets offset.storage.replication.factor=1 #offset.storage.partitions=25 # Topic to use for storing connector and task configurations; note that this should be a single partition, highly replicated, # and compacted topic. Kafka Connect will attempt to create the topic automatically when needed, but you can always manually create # the topic before starting Kafka Connect if a specific topic configuration is needed. # Most users will want to use the built-in default replication factor of 3 or in some cases even specify a larger value. # Since this means there must be at least as many brokers as the maximum replication factor used, we'd like to be able # to run this example on a single-broker cluster and so here we instead set the replication factor to 1. config.storage.topic=connect-configs config.storage.replication.factor=1 # Topic to use for storing statuses. This topic can have multiple partitions and should be replicated and compacted. # Kafka Connect will attempt to create the topic automatically when needed, but you can always manually create # the topic before starting Kafka Connect if a specific topic configuration is needed. # Most users will want to use the built-in default replication factor of 3 or in some cases even specify a larger value. # Since this means there must be at least as many brokers as the maximum replication factor used, we'd like to be able # to run this example on a single-broker cluster and so here we instead set the replication factor to 1. status.storage.topic=connect-status status.storage.replication.factor=1 #status.storage.partitions=5 # Flush much faster than normal, which is useful for testing/debugging offset.flush.interval.ms=10000 # These are provided to inform the user about the presence of the REST host and port configs # Hostname & Port for the REST API to listen on. If this is set, it will bind to the interface used to listen to requests. #rest.host.name= #rest.port=8083 # The Hostname & Port that will be given out to other workers to connect to i.e. URLs that are routable from other servers. #rest.advertised.host.name= #rest.advertised.port= # Set to a list of filesystem paths separated by commas (,) to enable class loading isolation for plugins # (connectors, converters, transformations). The list should consist of top level directories that include # any combination of: # a) directories immediately containing jars with plugins and their dependencies # b) uber-jars with plugins and their dependencies # c) directories immediately containing the package directory structure of classes of plugins and their dependencies # Examples: # plugin.path=/usr/local/share/java,/usr/local/share/kafka/plugins,/opt/connectors, plugin.path=/opt/kafka/plugins
重点配置 plugin.path ,同时也要注意,路径为连接器解压路径的父级目录
开启Kafka connect
just a shell
bin/connect-distributed.sh config/connect-distributed.properties
Kafka connect 的具体使用方式得去官网看,但总体来说就是通过 发送post 请求来搞的,启动后先测试下是否启动成功
curl -H "Accept:application/json" kafka1:8083/
注册Mysql 监听器
这里直接从官网抄个demo下来,改改参数
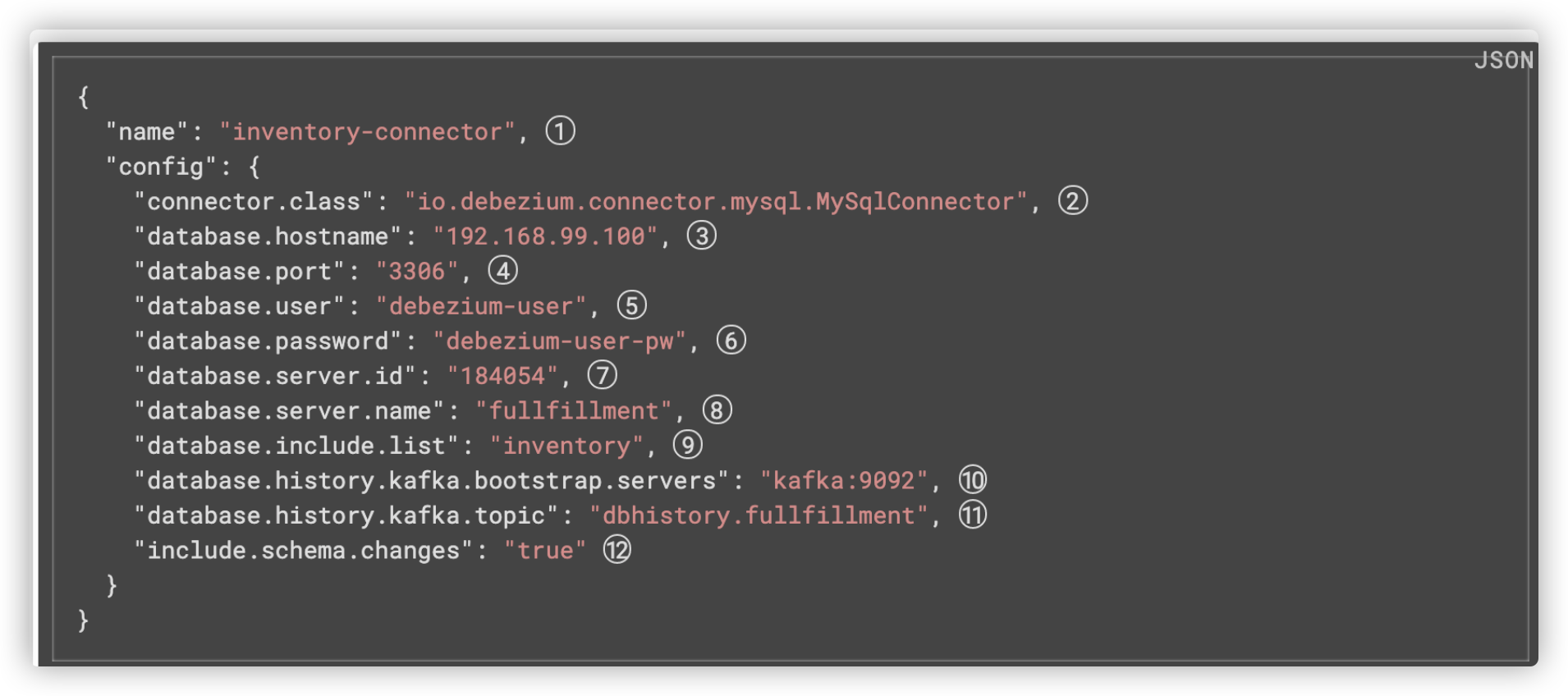
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" kafka1:8083/connectors/ -d '{ "name": "connector_demo", "config": { "connector.class": "io.debezium.connector.mysql.MySqlConnector", "tasks.max": "1", "database.hostname": "host.docker.internal", "database.port": "3306", "database.user": "root", "database.password": "123", "database.server.id": "184054", "database.server.name": "dbserver1", "database.include.list": "sensor_offset", "database.history.kafka.bootstrap.servers": "kafka1:9092", "database.history.kafka.topic": "dbhistory.sensor_offset" } }'
具体配置参考官网: https://debezium.io/documentation/reference/1.3/connectors/mysql.html#configure-the-mysql-connector_debezium
然后 你就可以看到你的Kafka里多了几个topic

配置flink-connecter
老规矩,抄官网: https://ci.apache.org/projects/flink/flink-docs-release-1.11/zh/dev/table/connectors/formats/debezium.html
利用table api 直接来操作
@Test public void testDebezium() throws Exception { tableEnvironment.getConfig().setSqlDialect(SqlDialect.DEFAULT); tableEnvironment.executeSql("CREATE TABLE offset_manager ( " + " groupid STRING, " + " topic STRING, " + " `partition` int, " + " untiloffset int " + ") WITH ( " + " 'connector' = 'kafka', " + " 'topic' = 'dbserver1.sensor_offset.offset_manager', " + " 'properties.bootstrap.servers' = 'kafka1:9092', " + " 'properties.group.id' = 'testGroup', " + " 'format' = 'debezium-json' " + ")"); Table offset_manager = tableEnvironment.from("offset_manager"); tableEnvironment.toRetractStream(offset_manager, Row.class).print(); env.execute(); }