一、上传flume并解压
cd /opt/install
rz
tar -zxvf apache-flume-1.6.0-bin.tar.gz -C /opt/software
mv apache-flume-1.6.0-bin.tar.gz flume-1.6.0

二、添加环境变量
vim vim /etc/profile export FLUME_HOME=/opt/software/flume-1.6.0 export PATH=$PATH:$FLUME_HOME/bin
保存
source /etc/profile
三、修改配置文件
cd /opt/software/flume-1.6.0/conf scp flume-env.sh.template flume.env.sh vim flume.env.sh export JAVA_HOME=/opt/software/jdk1.8

四、开始集成操作的配置文件
cd /opt/software/flume-1.6.0/conf vim flume_kafka.conf a1.sources = r1 a1.channels = c1 a1.sinks = k1 a1.sources.r1.type = exec #tail -F 根据文件名进行追踪 a1.sources.r1.command = tail -F /tmp/logs/update.log #把source和channel关联在一起 a1.sources.r1.channels = c1 a1.channels.c1.type=memory a1.channels.c1.capacity=10000 a1.channels.c1.transactionCapacity=100 a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink #指定kafka类型 a1.sinks.k1.topic = update_log #kafka集群地址 a1.sinks.k1.brokerList = hdp01:9092,hdp02:9092,hdp03:9092 a1.sinks.k1.requiredAcks = 1 a1.sinks.k1.batchSize = 20 a1.sinks.k1.channel = c1
五、准备数据
1、创建/tmp/logs/update.log文件
cd /tmp/logs
vim update.log

2、创建往update.log日志文件添加数据脚本 create_log.sh 文件
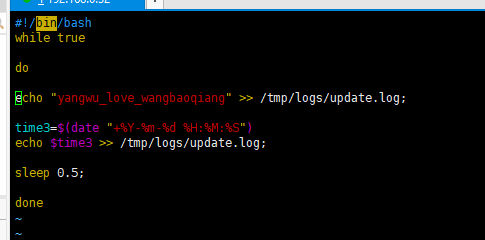
cd /tmp vim create_log.sh #!/bin/bash while true do echo "yangwu_love_wangbaoqiang" >> /tmp/logs/update.log; time3=$(date "+%Y-%m-%d %H:%M:%S") echo $time3 >> /tmp/logs/update.log; sleep 0.5; done
3、创建update_log的topic
kafka-topics.sh --create --zookeeper hdp01:2181 --partitions 3 --replication-factor 2 --topic update_log
六、启动
1、进入flume安装目录下启动flume。(kafka.conf是flume集成kafka的配置内容)
flume-ng agent -c conf -f conf/flume_kafka.conf -n a1 -Dflume.root.logger=INFO,console
2、启动模拟生产日志数据脚本
[root@Master tmp]# sh create_log.sh

3、在kafka安装的bin目录下启动kafka消费者查看数据
kafka-console-consumer.sh --from-beginning --zookeeper hdp01:2181 --topic update_log
