ConcurrentHashMap是在JDK5种引入的线程安全的哈希式集合,再JDK8之前采用了分段锁的设计理念,相当于Hashtable与HashMap的折中
版本,这是效率与一致性权衡后的结果。
分段锁是由内部类Segment实现的,它继承于ReentrantLock,用来管理它辖区的各个HashEntry,通过加锁的方式,保证每个Segment内都不
发生冲突。
1.8版本的ConcurrentHashMap对JDK7的版本进行了三点改造:
1)、取消分段锁机制,进一步降低冲突概率
2)、引入红黑树结构。同一个哈希槽上的元素个数超过一定阀值,单向链表改为红黑树结构
3)、使用了更加优化的方式统计集合内的元素数量。
首先,Map原有的size()方法最大只能表示到2^31-1,ConcurrentHashMap额外提供了mappingCount()方法,用来返回集合内元素的数量,
最大可以表示到2^63-1。此外,在元素总数更新时,使用了CAS和多种优化以提高并发能力。
相关属性定义:
/** * 默认为null,ConcurrentHashMao存放数据的地方,扩容时大小总是2的幂次方 * 初始化发生在第一次插入操作,数组默认初始化大小为16 */ transient volatile Node<K,V>[] table; /** * 默认为null,扩容时新生成的数组,其大小为原数组的两倍 */ private transient volatile Node<K,V>[] nextTable; /** * 存储单个KV数据节点。内部有key、value、hash、next指向下一个节点 * 它有4个在ConcurrentHashMap类内部定义的子类:TreeBin、TreeNode、ForwarddingNode、ReservationNode * 前三个子类都重写了查找元素的重要方法find(). */ static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; volatile V val; volatile Node<K,V> next; } /** * 它并不存储实际数据,维护对桶内红黑树的读写锁,存储对红黑树节点的引用 */ static final class TreeBin<K,V> extends Node<K,V> { TreeNode<K,V> root; volatile TreeNode<K,V> first; volatile Thread waiter; volatile int lockState; } /** * 在红黑树中,实际存储数据的节点 */ static final class TreeNode<K,V> extends Node<K,V> { TreeNode<K,V> parent; // red-black tree links TreeNode<K,V> left; TreeNode<K,V> right; TreeNode<K,V> prev; // needed to unlink next upon deletion boolean red; } /** * 扩容转发节点,放置此节点后,外部对原有哈希槽的操作会转发到nextTable上 */ static final class ForwardingNode<K,V> extends Node<K,V> { final Node<K,V>[] nextTable; } /** * 占位加锁节点。执行某些方法时,对其加锁,如computeIfAbsent等 */ static final class ReservationNode<K,V> extends Node<K,V> { } /** * 默认为0,重要属性,用来控制table的初始化和扩容操作 * sizeCtl=-1,表示正在初始化中 * sizeCtl=-n,表示n-1个线程正在进行扩容中 * sizeCtl>0,初始化或扩容中需要使用的容量 * sizeCtl=0,默认值,使用默认容量进行初始化 */ private transient volatile int sizeCtl; /** * 集合size小于64,无论如何,都不会受用红黑树结构 * 转化为红黑树还有一个条件是TREEIFY_THRESHOLD */ static final int MIN_TREEIFY_CAPACITY = 64;/** * 同一个哈希桶内存储的元素个数超过此阀值时,则存储结构由链表转为红黑树 */ static final int TREEIFY_THRESHOLD = 8; /** * 同一个哈希桶内存储的元素个数小于等于此阀值时,从红黑树回退至链表结构,因为元素个数较少时,链表更快 */ static final int UNTREEIFY_THRESHOLD = 6;
当某个槽内的元素个数增加到超过8个且table的容量大于或等于64时,由链表转为红黑树;当某个槽内的元素个数减少到6个时,由红黑树重新转回
链表。链表转红黑树的过程,就是把给定顺序的元素构成一棵红黑树的过程。需要注意的是,当table的容量小于64时,只会扩容,并不会把链表转为红黑树。
在转化过程中,使用同步块锁synchronized住当前槽的首元素,防止其他进行对当前槽进行增删改操作,转化完成后利用CAS替换原有链表。
因为TreeNode节点也存储了next引用,所以红黑树转链表的操作就变得非常简单,只需从TreeBin的first元素开始遍历所有的节点,并把节点从TreeNode类型转化为Node类型即可,当构造好新的链表之后,会同样利用CAS替换原有红黑树。相对来说,链表转红黑树更为复杂。
ConcurrentHashMap元素插入流程图:
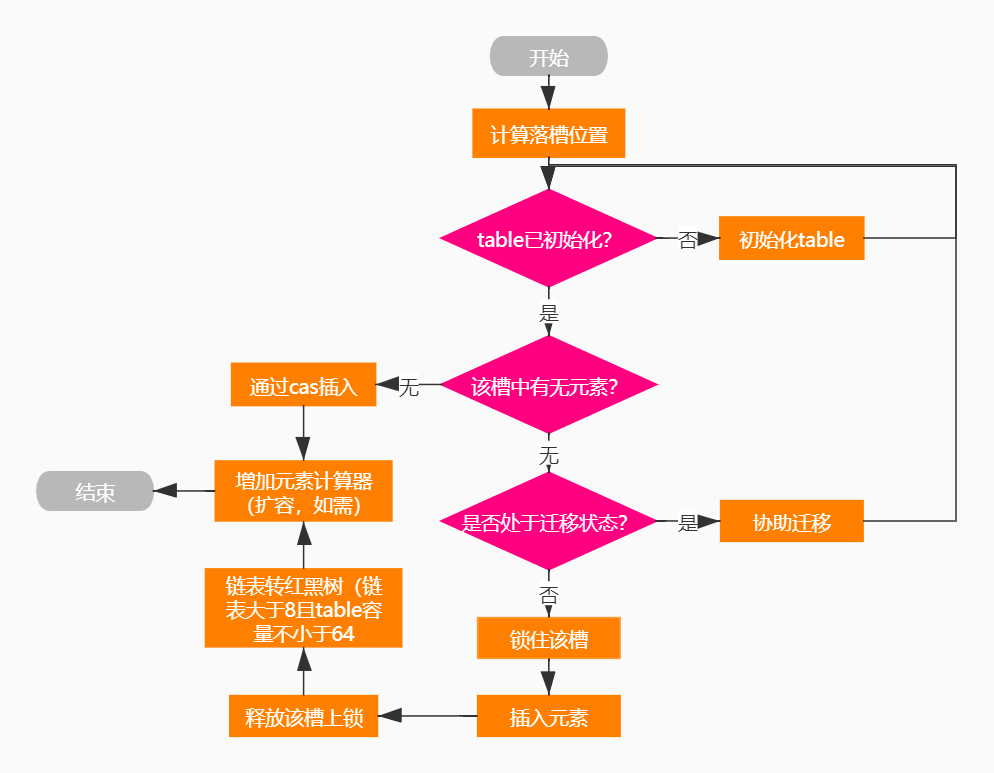
ForwardingNode在table扩容时使用,内部记录了扩容后的table,即nextTable。当table需要进行扩容时,依次遍历当前table中的每一个槽,如果
不为null,则需要把其中所有的元素根据hash值放入扩容后的nextTable中,而原table的槽内会放置一个ForwardingNode节点。正如其名,此节点会
把find()请求转发到扩容后的nextTable上。而执行put()方法的线程如果碰到此节点,也会协助进行迁移。
ReservationNode在ComputeIfAbsent()及其相关方法中作为一个预留节点使用。computeIfAbsent()方法会先判断相应的Key值是否已经存在,如
果不存在,则调用由用户实现的自定义方法来生成Value值,组成KV键值对,随后插入此哈希集合中。在并发场景下,在从得知Key不存在到插入哈希
集合。在并发场景下,在得知Key不存在到插入哈希集合的时间间隔内,为了防止哈希槽被其他线程抢占,当前线程会使用一个ReservationNode节点
放到槽中并加锁,从而保证了线程的安全性。
对于size(),JDK7或者8中的size方法都只能返回一个大概数量,无法做到100%的精确,因为已经统计过的槽在size()返回最终结果前有可能又发生
了变化,从而导致返回大小与实际大小存在些许差异。在多个槽的设计下,如果仅仅是为了统计数量而停下所有的增删操作,又会显得因噎废食。因此,ConcurrentHashMap在涉及元素总数的相关更新和计算时,会最大限度地减少锁的使用,以减少线程间的竞争与互相等待。在这个设计思路下,JDK8的ConcurrentHashMap对元素总数的计算又做了进一步的优化,具体表现在:在put()、remove()和size()方法中,涉及到元素总数的更新和计算,都彻底避免了锁的使用,取而代之的众多的CAS操作。
JDK7的put和remove方法,对于segment内部元素和计数器的更新,全部处于锁的保护下,如Segment.put()方法的第一行:
HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
这行代码能保证当前线程取得该Segment上的锁,随后可以大胆地更新元素和内部的计数器。
JDK7的ConcurrentHashMap获取集合大小流程图:
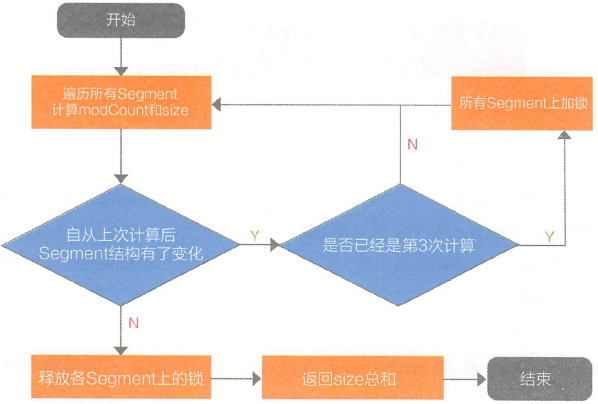
可以看到在JDK7版本中,ConcurrentHashMap在统计元素总数时已经开始避免使用锁了,毕竟加锁操作会极大地影响到其他线程对哈希元素的修改。
当经过了3次计算(2次对比)后,发现每次统计时哈希都有结构性的变化,这是它就会把所有的Segment都加上锁;而当自己统计完成后,才会把锁
释放掉,再允许其他线程修改哈希中的元素。
在JDK8中,对获取集合元素个数又进一步的优化,在put中,对于哈希元素总数的更新,是置于某个槽的锁之外的,主要会用到的属性如下:
/** * 记录了元素总数值,主要用在无竞争状态下,在总数更新后,通过CAS方式直接更新这个值 */ private transient volatile long baseCount; /** * 一个计数器单元,维护了一个value值 */ @sun.misc.Contended static final class CounterCell { volatile long value; CounterCell(long x) { value = x; } /** * Table of counter cells. When non-null, size is a power of 2.
* 在竞争激烈的状态下启用,线程会把总数更新情况存放到该结构内,当竞争进一步加剧时,会通过扩容减少竞争 */ private transient volatile CounterCell[] counterCells;
正是借助baseCount和counterCells两个属性,并配合多次使用CAS方法,JDK8种的ConcurrentHashMap避免了锁的使用。
1):当并发量较小时,优先使用CAS的方式直接更新baseCount
2):当更新baseCount冲突,则会认为进入到比较激烈的竞争状态,通过启用counterCells减少竞争,通过CAS的方式把总数更新情况记录在
counterCells对应的位置上。
3):如果更新counterCells上的某个位置时出现了多次失败,则会通过扩容counterCells的方式减少冲突
4):当counterCells处在扩容期间时,会尝试更新baseCount值
对于元素总数的统计,逻辑就非常简单了,只需要让baseCount加上各counterCells内的数据,就可以得出哈希内的元素总数,整个过程完全不需要借助锁。
正因为ConcurrentHashMap提供了高效的锁机制实现,在各种多线程应用场景中,推荐使用此集合进行KV键值对的存储与使用。