1.var reg=/./ var reg=/./
前者代表任意一个字符而后者代表这个字符串中得有一个.
2.?的使用
如果单独的一个字符后面带? var reg=/d?/ /n?/
代表一个或0个这个字符的出现
如果是量词+和*,{2,}后面带? 取消正则的贪婪性 在捕获阶段
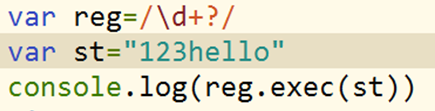
3.捕获
1.普通捕获 exec() match()
普通捕获有懒惰性,给正则添加一个修饰符g可以解决,match是将所有捕获的内容放在一个数组中并返回。Match就是对exec的一个简单封装。
2.分组捕获 捕获的方法还是exec 和match
正则在结构上发生了变化,加()
Var reg=/(a)(b)/
Exec()和match()在非全局下分组捕获是相同的,在捕获的过程中即捕获大正则里的内容也捕获分组中的内容并都返回。

Exec()和match()在全局下的分组捕获是不一样的,exec()不变。但是match()只捕获大正则里的内容

3. 分组捕获的优势
A.可以提升优先级
B.可以捕获引用
1代表分组1里面的内容 2代表分组2里面的内容
前提是分组必须在引用之前,如果2在分组的前面代表普通的表达式???
分组的结果存在正则类RegExp的$number属性下。
1 和RegExp.$1 二者都是分组引用
1只能使用在正则表达式里面,RegExp.$1 可以外面使用。都是在捕获完成的条件下。
4. 在捕获的过程中怎样取消捕获分组中的内
在分组的前面加上?:就ok了
?:和?=的区别
?:取消捕获分组中的内容的
?= a(?=s)

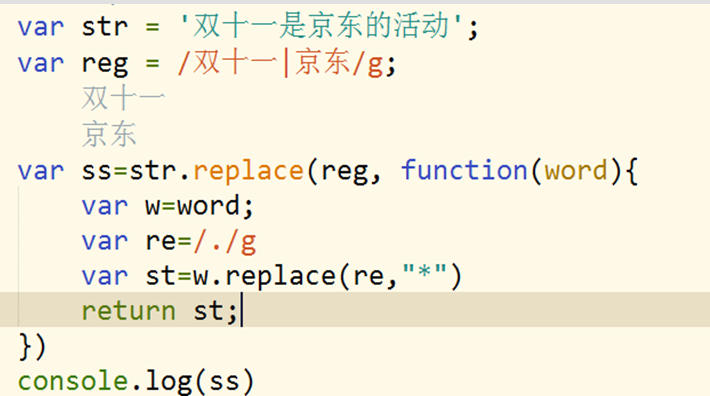
4.replace细说
Replace是字符串的一个方法,他有两个参数,用后者将前者替换掉,并返回一个新的字符串,但是没有改变原来的字符串.
- 如果第一个参数是字符串,只改变一次
- 如果第一个参数是正则,捕获一次改变一次
- 如果第二个参数是匿名函数,每捕获一次这个匿名函数会执行一次,return的是什么,那就替换成什么。这个匿名函数的arguments有三个元素。
正则详细讲解
(1)每一个正则都是由元字符和修饰符组成
(2)元字符 在//之间有特殊意义的字符
(3)具有特殊意义的元字符
- 转义字符,转义后面后面字符所代表的含义
- ^以某一个元字符开始 读kangchuo
- $以某一个元字符结尾
- 匹配一个换行符
- .除了
以外的任意一个字符

-
()分组,把一个大正则划分为几个小正则
-
X|y x或者y中的一个
- [xyz],x或者y或者z三者中的一个
-
[^xyz] ^读作v
Var reg=/^d$/ 只能是一个0-9之间的数字

是因为^和$不占用位置只有d占位置

4.代表出现次数的量词的元字符
1.*代表出现0-多次
2,+出现1到多次
3,?出现0都1词
4,{n}出现n词
5,{n,}出现n到多次
6.{n,m}出现n到m次
规律
[]
- 在[]中出现的所有的字符都是代表本身意思的字符
- [.]就是本身的.[+]代表的就是+本身
- []里面不识别双位数[12] 不是12是1或者2
[12-68] 代表的是1或者2-6中的一个或者8

案例1 有效数字的正则
0.4 12.0 12 +12 -12 09
var reg=/^[+-]?(d|([1-9]d+))(.d+)$/
|的混乱
Reg=/^18|19$/ 和/^(18|19)$/
前者表达的优先级特别多
- 可以是以1开头以9结尾的字符串 189 119 119等
- 也可理解为以18开头或以19结尾 181 119 等
而后者只有一种就是18或者19
分组提升了优先级
分组的第一个作用就是改变优先级
案例2
