Deployment
Deployment负责管理部署,管理模式为:
Deployment只负责管理不同版本的ReplicaSet,由RepliaSet管理Pod副本数
每个RepliaSet对应了Deployment template的一个版本
一个RepliaSet下的Pod都是相同的版本

Deployment功能包括:
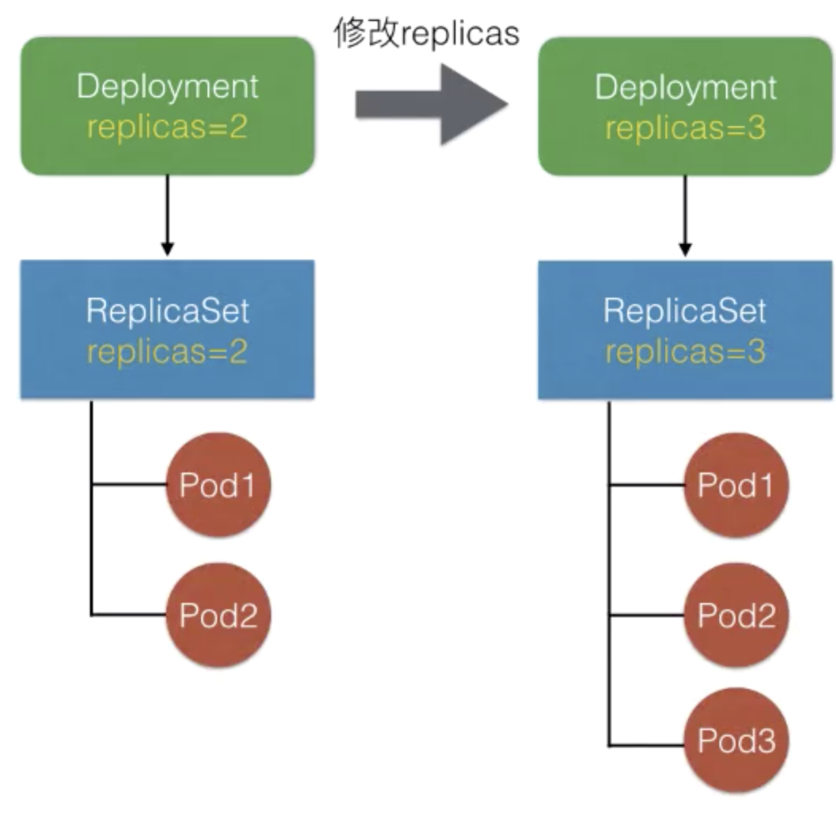
(1)定义Pod的期望数量,通过controller进行维持
例如扩缩容就是直接修改Deployment.spec.replicas,Deployment controller会把replicas同步到当前版本的RS中,由RS执行扩缩容
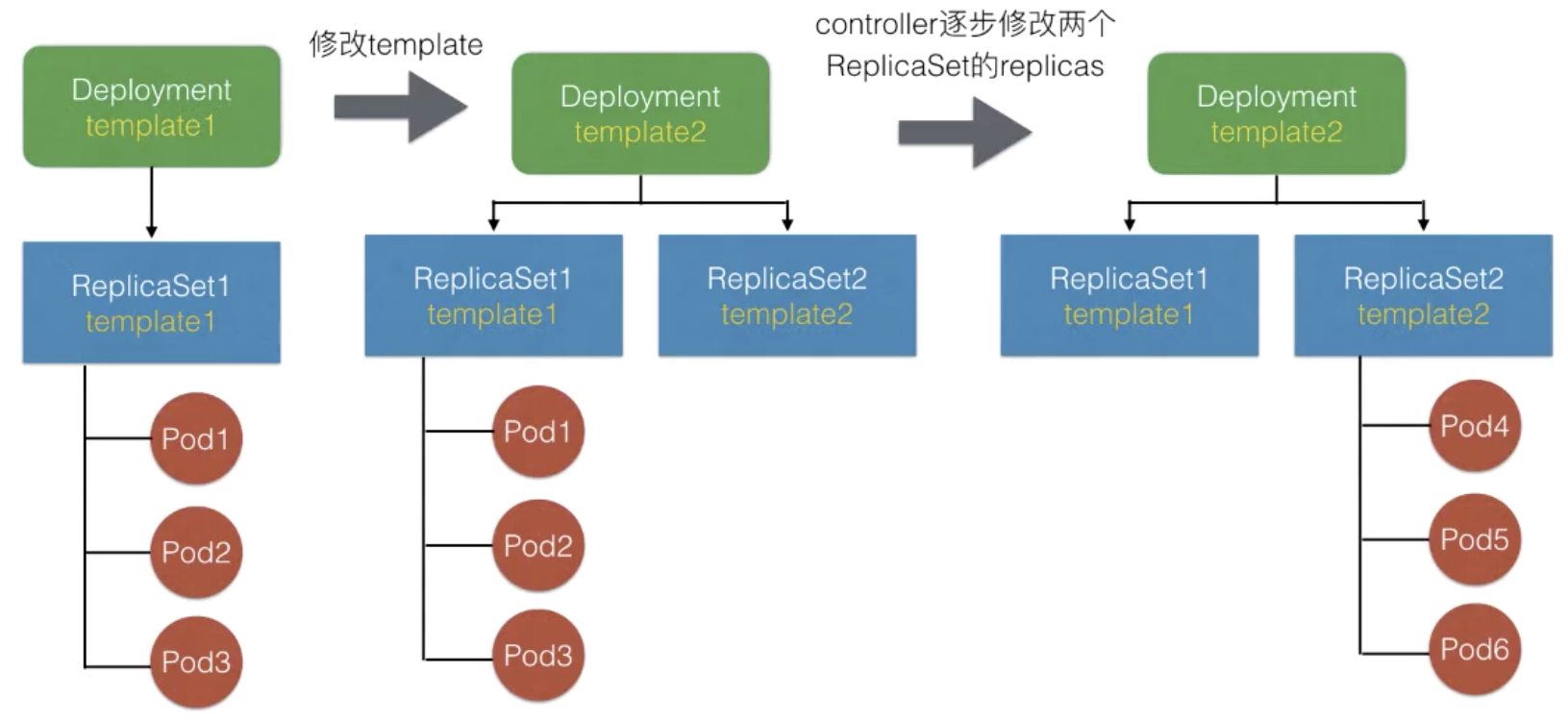
(2)配置Pod的发布方式,controller会按照用户给定的策略来更新Pod
例如修改template中一个容器的image,Deployment controller会基于新template创建一个新ReplicaSet,然后逐渐修改两个ReplicaSet中Pod的期望数量,最终完成一次发布。
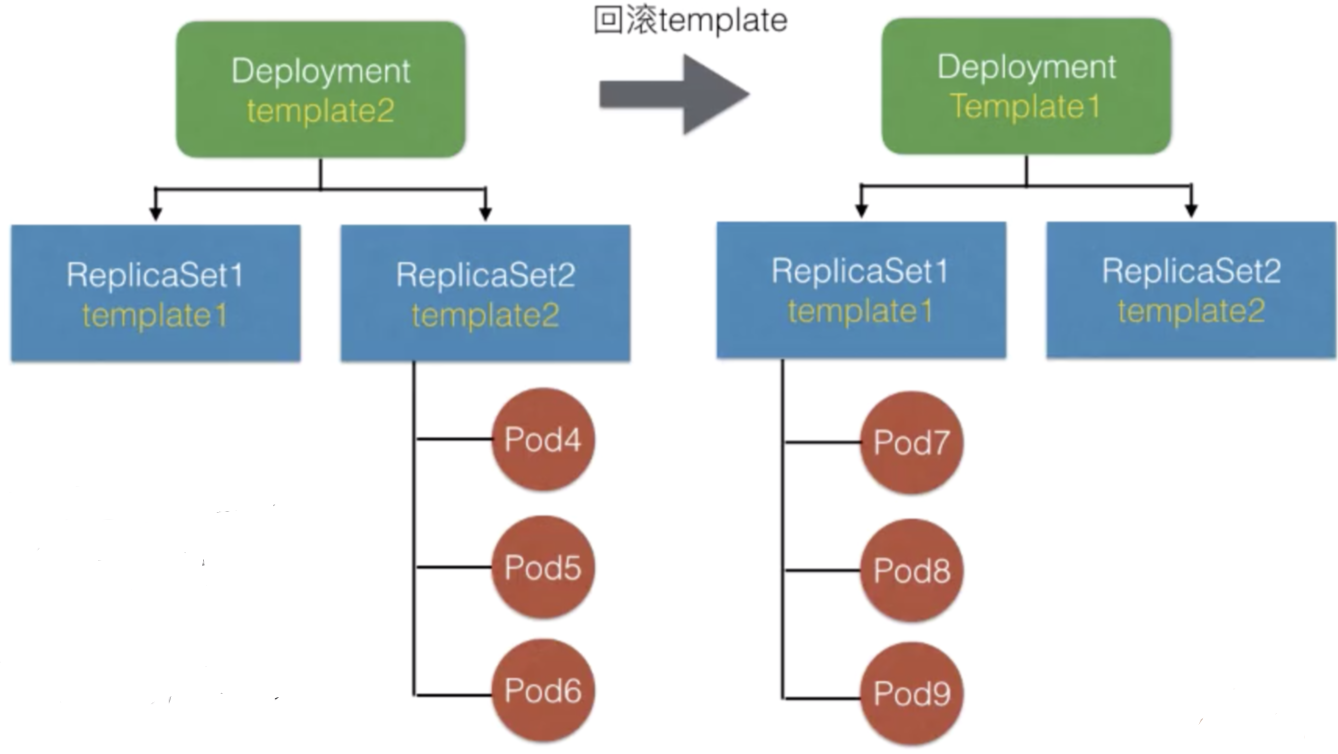
(3)更新过程中发生问题时,进行一键回滚
不管是通过kubectl rollout命令还是通过回滚修改后重新发布,其实都是把template回滚为旧版本的template。
Deployment会重新修改旧ReplicaSet中Pod的期望数量,逐渐减少新版本ReplicaSet中的replica,最终把Pod从旧版本重新创建出来。
Deployment的资源对象描述文件:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
.spec.replicas定义期望的Pod数量;
.spec.selector是Pod选择器,圈定Deployment管理的Pod范围。所有扩容出来的Pod的Labels必须匹配该标签。
.spec.template是Pod相关的模板(k8s包含了podtemplates这种资源对象,但不能创建,只能包含在workload资源对象中),包含了:
期望Pod的metadata,其中包含了labels(和selector.matchLabels相匹配的标签)
最终创建出的Pod的spec
.spec.MinReadySeconds:默认情况下Deployment会根据Pod是否ready判断其是否可用。设置了MinReadySeconds后,Deployment会等若干秒之后才认为Pod是available的;
.spec.revisionHistoryLimit:除了当前版本外,还保留的历史版本数量,默认值为10个。
.spec.paused:标识Deployment只做数量维持,不做新的发布。所有对spec.template.spec的修改都不会触发新的rollout,只会把replicas同步到对应的ReplicaSet中,更新一下Deployment的status。在Debug场景下才会设置为true。
.spec.progressDeadlineSeconds:设置Deployment处于Processing状态的超时时间。超时后Deployment认为这个Pod进入failed状态。
.spec.strategy:spec.strategy.type为Recreate时,会先停掉所有旧的再起新的;为RollingUpdate(默认)时,会滚动更新,此时有两个可配置项:
MaxUnavailable:滚动过程中最多有多少个Pod不可用;
MaxSurge:滚动过程中最多存在多少个Pod超过预期replicas数量。
如果用户的资源足够,且更注重发布过程中的可用性,可设置MaxUnavailable较小、MaxSurge较大。
如果用户的资源比较紧张,可以设置MaxSurge较小,甚至设置为0
注意:MaxSurge和MaxUnavailable不能同时为0!
创建出一个Deployment的时候,可以通过kubectl get deployment,看到Deployment总体的状态:
$ kubectl create -f nginx-deployment.yaml $ kubectl get deployment NAME DESRED CURRENT UP-TO-DATE AVAILABLE AGE nginx-deploynment 3 3 3 3 80m
DESIRED:期望的Pod数量;
CURRENT:当前实际 Pod 数量;
UP-TO-DATE:到达最新的期望版本的Pod数量;
AVAILABLE:运行过程中可用的Pod数量。
AGE:创建的时长。
Deployment的status中描述的状态包括:Processing(扩容/发布中)、Complete(运行中)以及Failed。

Deployment相关命令:
如果在发布过程中遇到了问题,通过kubectl rollout undo命令快速回滚Deployment版本:
$ kubectl rollout undo deployment/nginx-deployment $ kubectl rollout undo deployment.v1.apps/nginx-deployment —to-revision=2
--to-revision指定可以回滚到某一个具体的版本,必须先查一下版本号:
$ kubectl rollout history deployment.v1.apps/nginx-deployment
查看rollout的状态
$ kubectl rollout status deployment/nginx-deployment
扩容:
$ kubectl scale deployment nginx-deployment --replicas 10
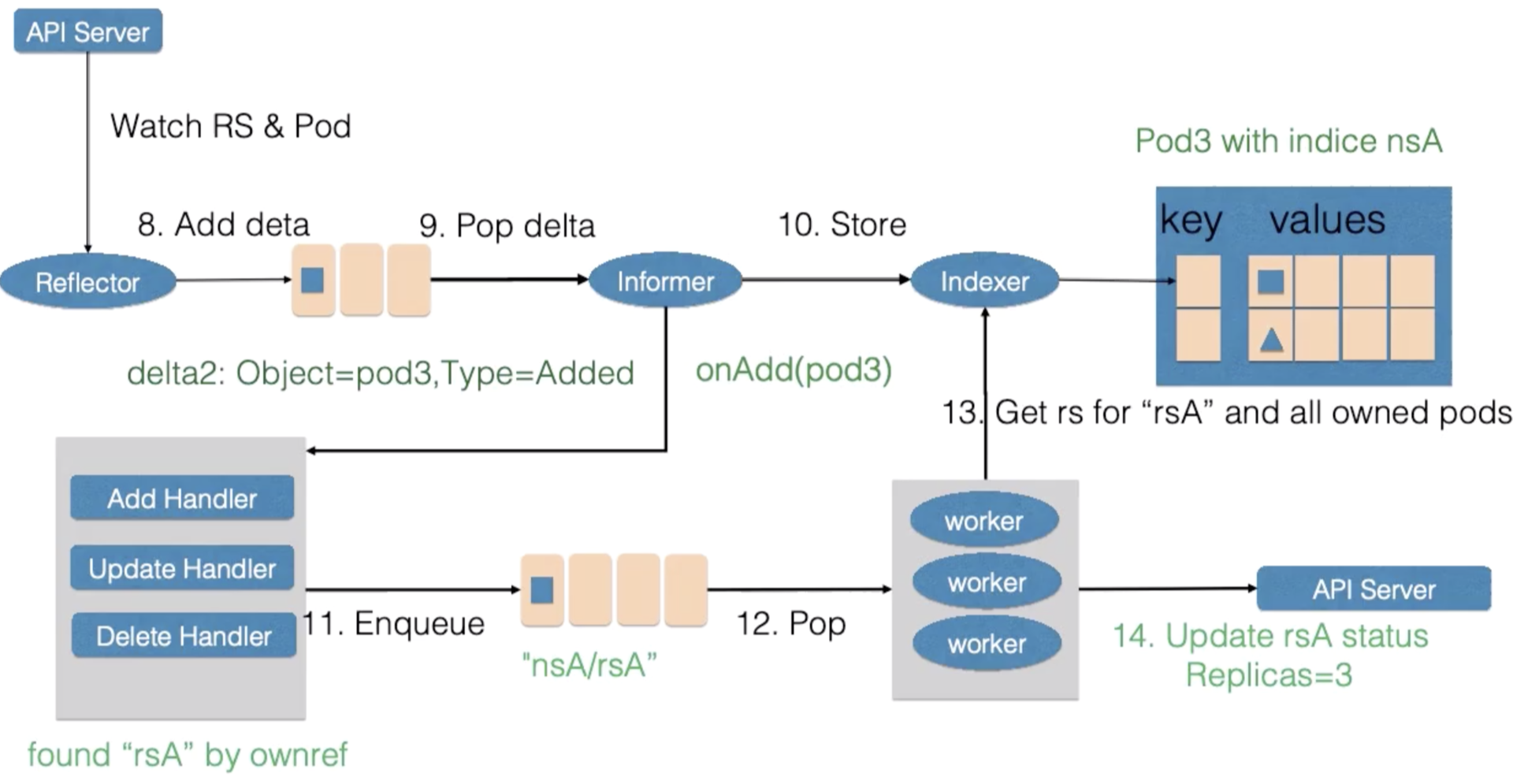
Deployment Controller实现原理:
Deployment Controller关注Deployment和ReplicaSet相关的event,收到事件后会加入到队列中。
从队列中把事件取出来后,会检查paused(Deployment是否需要新的发布)
ReplicaSet Controller也通过Informer机制监听ReplicaSet资源来维持应用希望的状态数量,但是只管理副本数。如果发现replicas比Pod数量大的话扩容,比实际数量小就缩容。
假如rsA的replicas从2被改到3。
首先,Reflector会watch到ReplicaSet和Pod两种资源的变化,在DeltaFIFO中塞入了对象是rsA、类型是Updated的记录。
Informer把新的ReplicaSet更新到Index中并调用Update的回调函数。
ReplicaSet Controller的Update回调函数发现ReplicaSet变化后会把nsA/rsA作为key值加入到工作队列中,
ReplicaSet Controller会并发启动多个worker,以处理不同的对象实例。
worker池中一个worker从工作队列中取到了key(nsA/rsA),并从Index中取到了ReplicaSet rsA的最新数据。
worker通过比较rsA的spec和status里的数值,发现需要对它进行扩容,因此创建了一个Pod。这个Pod的Ownereference指向向了ReplicaSet rsA。
worker如果处理失败,一般会把key重新加入到工作队列中,从而方便之后进行重试。
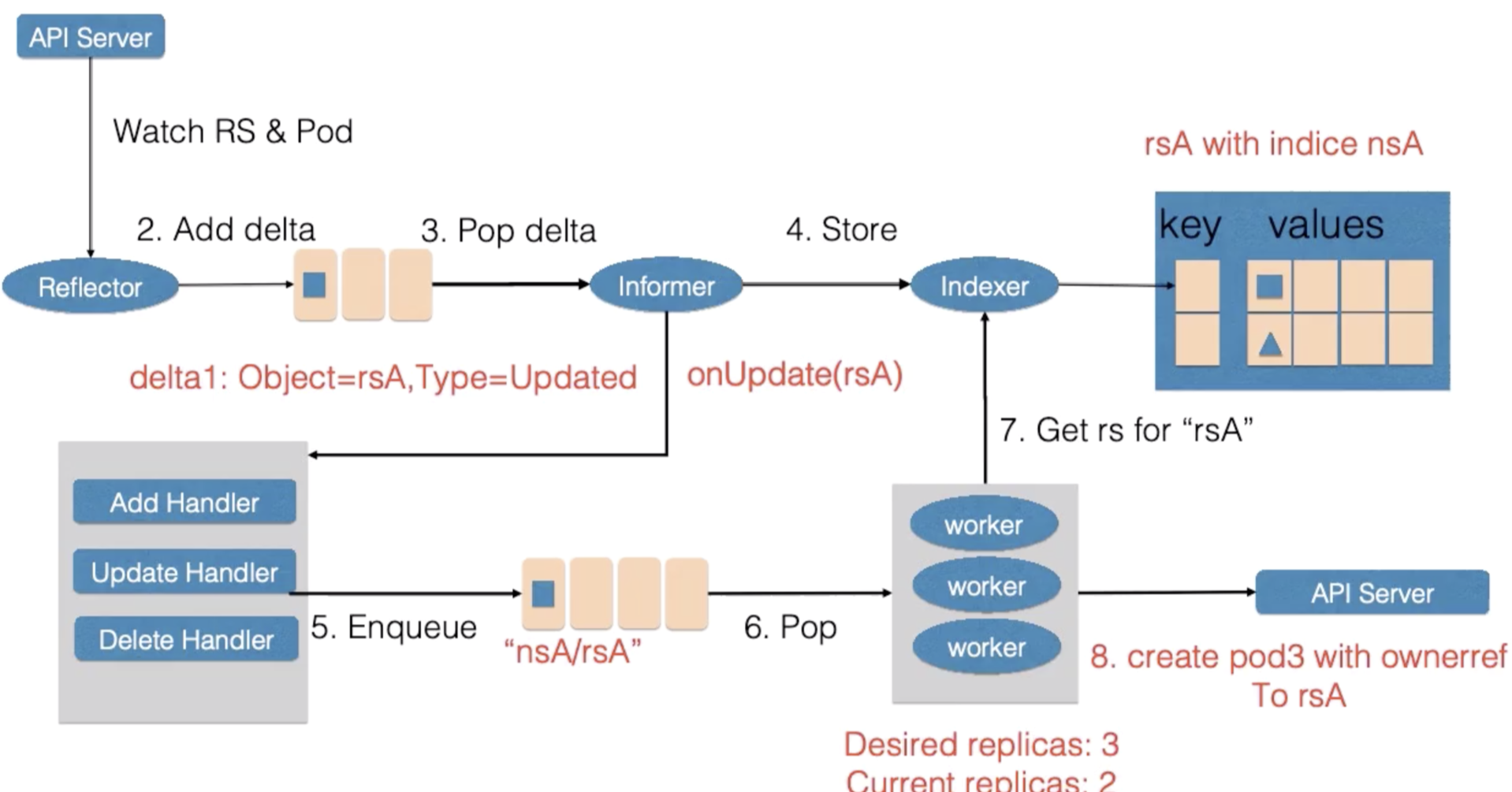
然后Reflector watch到的Pod新增事件,在DeltaFIFO中塞入了对象是Pod、类型是Add的记录。
Informer把新的Pod更新到Index中并调用ReplicaSet Controller的Add的回调函数。
ReplicaSet Controller的Add回调函数通过检查Pod的ownerReferences找到了对应的ReplicaSet,并把nsA/rsA字符串塞入到了工作队列中。
woker在得到新的工作项后,从缓存中取到了新的ReplicaSet记录,并得到了其所有创建的Pod。因为ReplicaSet 的status不是最新的(创建的Pod总数还未更新)。因此在此时ReplicaSet更新status使得spec和status达成一致。
StatefulSet
Deployment认为:它管理的所有相同版本的Pod都是一模一样的副本。也就是说,在Deployment Controller看来,所有相同版本的Pod都是完全相同的。
StatefulSet的特征:
-
每个Pod会有Order序号,会按照序号来创建、删除、更新Pod;
-
通过配置一个headless Service,使每个Pod有一个唯一的网络标识(hostname)
-
通过配置PVC模板,使每个Pod有一块或者多块PV存储盘;
-
支持一定数量的灰度发布。比如某StatefulSet有3副本,可以指定只升级其中的一个或者两个到新版本。
首先需要创建一个headless Service:
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
StatefulSet的.spec.serviceName需要对应Headless Service的名字
也可以随便取一个错误的名字(不会做校验)。此时不会为Pod分配唯一的hostname
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx # has to match .spec.template.metadata.labels
serviceName: “nginx”
replicas: 3 # by default is 1
template:
metadata:
labels:
app: nginx # has to match .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: k8s.gcr.io/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "my-storage-class"
resources:
requests:
storage: 1Gi
StatefulSet创建了三种资源:
-
ControllerRevision
通过ControllerRevision,StatefulSet可以很方便地管理不同版本的template模板。
在创建之初拥有的第一个template版本,会创建一个对应的ControllerRevision。当修改了image版本之后,StatefulSet Controller会创建一个新的ControllerRevision。
即,每一个ControllerRevision对应了每一个版本的Template,也对应了每一个版本的ControllerRevision hash。
-
PVC
在spec.volumeClaimTemplates中定义了叫www的PVC模板。通过这样的方式使每个Pod都有独立的PVC,并且挂载到容器中对应目录。
每个Pod创建前,会先创建PVC。顺序创建的PVC名为www-nginx-web-0、www-nginx-web-1……
注意:当前版本的StatefulSet不会在PVC中添加 OwnerReference,删除StatefulSet之后,StatefulSet创建的ControllerRevision和Pod都会被删除,但是PVC不会被级联删除。
-
Pod
按照0->1->2的顺序创建pod,创建的pod名为nginx-web-0、nginx-web-1……前面所有的Pod都要Ready之后,才会创建下一个 Pod
PVC创建完成后,Pending状态的Pod和PV进行绑定,然后变成了ContainerCreating,最后达到Running。
StatefulSet 通过Pod的label(controller-revision-hash)标识Pod所属的版本 。
.spec.podManagementPolicy:默认是OrderedReady(按序扩缩容),也有Paralel(并行扩缩容)
spec.strategy:spec.strategy.type为OnDelete时,Statefulset controller不会自动更新Pod,必须手动删除旧的
spec.strategy.type为RollingUpdate时,按照2->1->0的顺序升级(删除重建),controller-revision-hash会随之升级,PVC则会自动复用。
partition:可以指定部分更新
PS:假设当前有个replicas为10的StatefulSet,Pod 序号为0~9。partition是8。更新时,会保留0~7这8个Pod为旧版本,只更新 2个新版本作为灰度。
PS:若partition≥replicas,更新无法成功
PS:清除的版本,必须没有Pod。否则该ControllerRevision不能被删除的。
StatefulSet的status字段:
collisionCount:为了collision avoidance而加上的字段
currentReplica:当前版本的数量
currentRevision:当前版本号
updateReplicas:新版本的数量
updateRevision:当前要更新的版本号
replicas、readyReplicas、updatedReplicas:字面意思
此处currentReplica、updateReplica、currentRevision、updateRevision都是一样的,表示所有Pod已经升级到了所需要的版本。
StatefulSet Controller实现原理:

StatefulSet Controller从工作队列将工作项取出来后,先Update Revision,即查看当前拿到的StatefulSet中的template,有没有对应的ControllerRevision。如果没有,说明template已经更新过,Controller就会创建一个新版本的Revision,也就有了一个新的ControllerRevision hash版本号。
Update in order:Controller把所有版本号拿出来,并且按照序号整理一遍。这个整理的过程中,如果发现有缺少的 Pod,就按照序号去创建;如果发现有多余的 Pod,就按照序号去删除。即查看所有Pod是否满足序号。
Update status:当保证了Pod数量和序号满足Replica数量之后,Controller会去查看是否需要更新Pod。即查看Pod期望的版本是否符合要求,并且通过序号来更新。
Update in order中删除 Pod后,其实是在下一次触发事件,Controller才会发现缺少Pod,然后在Update in order中把新的Pod创建出来。在这之后Controller才会Update status(通过命令行看到的status 信息)。
Job
Job Controller实现原理:

Job Controller负责的工作包括:
根据配置创建相应的pod;
跟踪Job的状态,根据配置重试或者继续创建;
根据依赖关系,保证上一个Job运行完成之后再运行下一个Job;
自动添加label来跟踪对应的Pod,并根据配置并行或串行地创建Pod;
Job的的资源对象描述文件:
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4
.spec.template.spec就是pod的spec。
.spec.template.spec.restartPolicy是重启策略,可以设置Never、OnFailure、Always三种。
若要并行运行job,还需要在spec中增加两个参数:
(1).spec.completions:指定本Pod队列执行次数,即该Job指定的可以运行的总次数。
(2).spec.parallelism:代表并行执行的个数,即一个管道或者缓冲器中缓冲队列的大小。
例如completions设置为8,parallelism设置成 2。即Job一定要执行8次,每次并行2个Pod,一共会执行4个批次。
.spec.backoffLimit表示一个Job到底能重试多少次。
$ kubectl get jobs Name COMPLETIONS DURATION AGE pi 1/1 71s 4m6s
COMPLETIONS:任务里有几个Pod,其中完成了多少个。
DURATION:Job里面的实际业务运行了多长时间。
AGE:这个Pod创建了多少时间。
生成的job中,会自动加上此Pod选择器:
selector:
matchLabels:
controller-uid: df858f2d-82cf-4726-85e9-8e7899d13d74
创建的Pod会自动加上controller-uid:xxx和的标签
如果job运行失败,.status.conditions中会显示Failed的reson和message
status:
conditions:
- lastProbeTime: "2020-10-20T12:09:53Z"
lastTransitionTime: "2020-10-20T12:09:53Z"
message: Job has reached the specified backoff limit
reason: BackoffLimitExceeded
status: "True"
type: Failed
failed: 2
startTime: "2020-10-20T12:09:07Z"
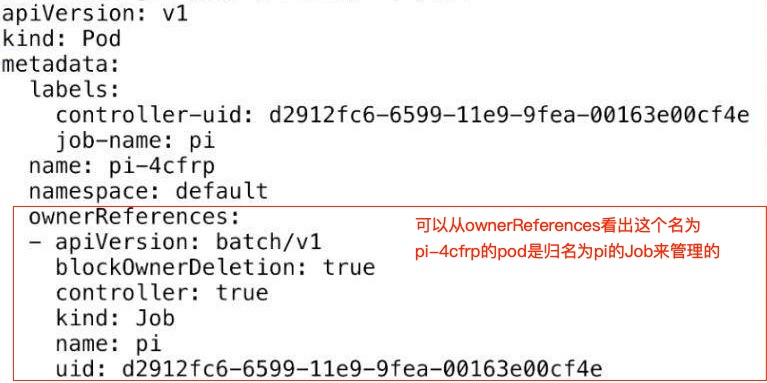
job的yaml文件无法看出Job创建了哪些Pod,只能通过kubectl describe job xxx看相应的Event,发现Job会创建叫job−name−{random-suffix}的Pod:
CronJob
CronJob主要是用来运作一些定时任务(如Jenkins构建等),和Job相比会多几个不同的字段:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
.spec.schedule:设置时间格式,格式和Linux的crontab一样
.spec.startingDeadlineSeconds:每次运行Job的时候最长可以等多长时间,超过时间CronJob就会停止这个 Job
.spec.concurrencyPolicy:是否允许并行运行。
PS:并行运行指的是,如果Job运行的时间特别长,第二个Job需要运行的时候上一个Job还没完成,会同时运行两个Job。
.spec.successfulJobsHistoryLimit:定时Job的执行历史的存留数。
DaemonSet
DaemonSet也是Kubernetes提供的一个default controller,它是一个守护进程的控制器,能帮我们做到以下几件事情:
保证集群内的每一个节点都运行一组相同的 pod
根据节点的状态保证新加入的节点自动创建对应的 pod
在移除节点的时候,能删除对应的 pod
跟踪每个 pod 的状态,当pod出现异常会及时recovery
常用于以下几点内容:
存储:需要每台节点上都运行一个类似于 Agent 的东西
日志收集:如logstash或者fluentd,需要每台节点都运行一个Agent
监控:如说Promethues
配置示例:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
创建的Daemonset会在每个node创建叫daemonset−name−{random-suffix}的Pod,通过matchLabel去管理对应所属的Pod
$ kubectl get ds NAME DESIRED CURRENT READY UP-TO-DATA AVAILABLE NODE ELECTION AGE fluentd-elasticsearch 4 4 4 4 4 <node> 4s
DESIRED:需要的pod个数
CURRENT:当前已存在pod个数
READY:就绪的个数
UP-TO-DATA:最新创建的个数
AVAILABLE:可用pod个数
NODE ELECTION:节点选择数
DaemonSet有两种更新策略:
RollingUpdate(默认):先更新第一个Pod,然后老的Pod被移除,通过健康检查之后再建第二个Pod
OnDelete:模板更新后,Pod不会有任何变化。除非手动删除某一个节点上的Pod
DaemonSet Controller实现原理:

大体上与Job Controller类似,不过它还会监控Node的状态,根据配置的affinity或者label去选择对应的节点后,进行Pod的创建、Pod的版本比较和升级等。
更新完了之后,它会更新整个DaemonSet的状态
参考资源:阿里云云原生公开课