存储器的组织形式:
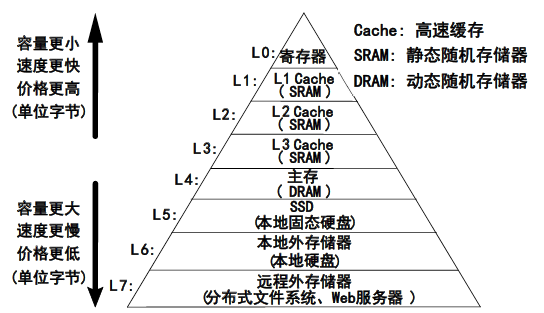
数据总是在相邻两层之间复制传送,最小传送单位是定长块,互为副本(不删除)
⭐️指令和数据有时间局部性和空间局部性。
高速缓冲存储器Cache
介于CPU和主存储器间的高速小容量存储器,由静态存储芯片SRAM组成,容量较小但比主存DRAM技术更加昂贵而快速, 接近于CPU的速度。CPU往往需要重复读取同样的数据块, Cache的引入与缓存容量的增大,可以大幅提升CPU内部读取数据的命中率,从而提高系统性能。通常由高速存储器、联想存储器、地址转换部件、替换部件等组成。
- 联想存储器:根据内容进行寻址的存储器(冯氏模型中是按照地址进行寻址,但在高速存储器中往往只存有部分信息,此时需要根据内容进行检索)
- 地址转换部件:通过联想存储器建立目录表以实现快速地址转换。命中时直接访问Cache;未命中时从内存读取放入Cache
- 替换部件:在缓存已满时按一定策略进行数据块替换,并修改地址转换部件
早期采用外部(Off-chip)Cache,不做在CPU内而是独立设置一个Cache;
现在采用片内(On-chip)Cache,将Cache和CPU作在一个芯片上,且采用多级Cache,同时使用L1 Cache和L2 Cache,甚至有L3 Cache。
(1)一般L1 Cache都是分立Cache,分为数据缓存和指令缓存,可以减少访存冲突引起的结构冒险,这样多条指令可以并行执行;内置;其成本最高,对CPU的性能影响最大
多级Cache的情况下,L1 Cache的命中时间比命中率更重要
(2)一般L2 Cache都是联合Cache,这样空间利用率高
没有L3 Cache的情况下,L2 Cache的命中率比命中时间更重要(缺失时需从主存取数,并要送L1和L2 cache)
(3)L3 Cache多为外置,在游戏和服务器领域有效;但对很多应用来说,总线改善比设置L3更加有利于提升系统性能
例:Intel Core i7处理器的Cache架构

i-cache和d-cache都是32KB、8路、4个时钟周期;
L2 cache:256KB 、8路、11个时钟周期。
所有核共享的L3 cache:8MB、16路、30~40个时钟周期。
Core i7中所有cache的块大小都是64B
鉴于程序执行与数据访问的一致性原理,存储管理软件使用Cache可以大幅提升程序执行效率。
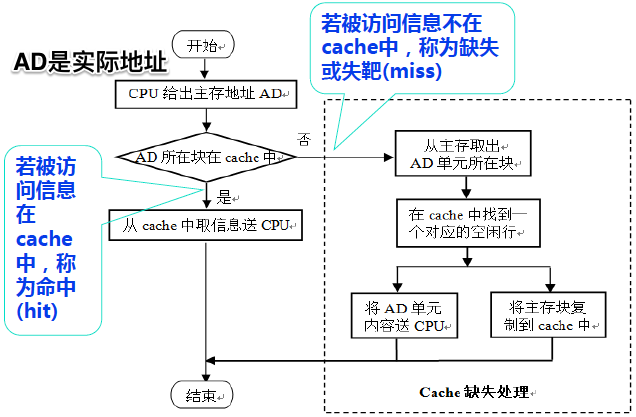
主存映射:
Cache越大,Miss率越低,但成本越高
把主存空间划分成大小相等的主存块(Block),Cache也被分成相同大小的块,称为Cache行(line)或槽(Slot)。
Block大小与Cache大小有关,且不能太大,也不能太小:采用大的Block能很好地利用空间局部性,但需要花费较多的时间来存取,缺失损失会变大。
将主存块和Cache行按照以下三种方式进行映射
- 直接(Direct)映射/模映射:每个主存块映射到Cache的固定行
Cache标记(tag)指出对应行取自哪个主存块群号。
有效位V,为1表示有效;开机或复位时,使所有行的有效位V=0;进程切换或DMA传送时,通过使V=0来冲刷Cache。
操作系统内核可以使用“cache冲刷”指令
特点:容易实现,命中时间短,无需考虑淘汰问题;但不够灵活,Cache存储空间得不到充分利用,命中率低
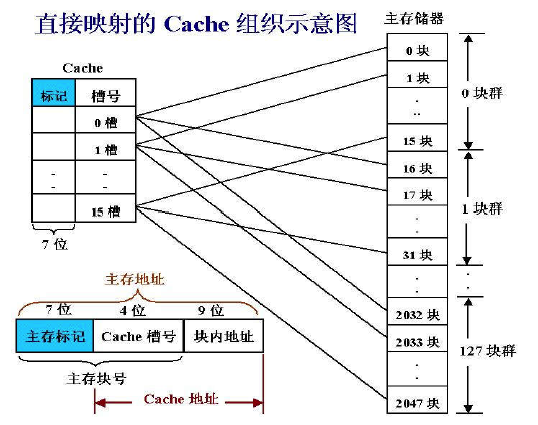
例子:

Block大小为16B,Cache共4K2^12行。
如何判断命中:中间的12位作为index索引找到对应行,拿地址中的tag和该行的tag对比,tag相等且V=1则hit
如果取32位word,块内地址高2位决定取块内哪个word,低2位决定取word四个字节中的哪一个
- 全相联(Full Associate):每个主存块映射到Cache的任一行
按内容访问,是相联存取方式
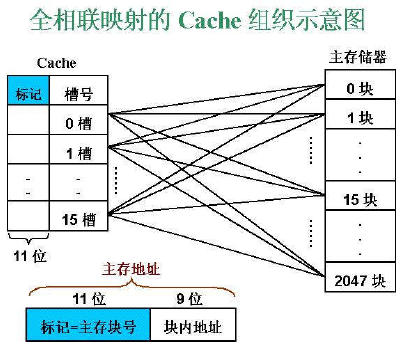
特点:同时比较所有Cache项的标志,无需Cache索引;命中时间长;没有冲突缺失,因为只要有空闲Cache块,都不会发生冲突;每一行都需要比较器,比较器位数长,占用容量增加。
- 组相联(Set Associate):每个主存块映射到Cache固定组中任
将Cache所有行分组,把主存块映射到Cache固定组的任一行中。也即:组间模映射、组内全映射。映射关系为:
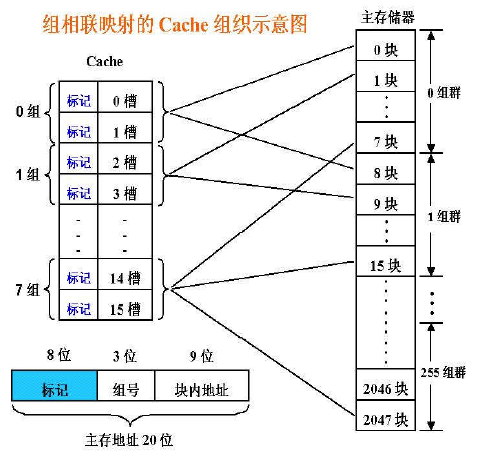
Cache标记(tag)指出对应行取自哪个主存块群号。
N-路组相联(N-way set associative):N 个直接映射的行并行操作
例如:2-路组相联
- Cache Index 选择其中的一个Cache行集合(共2行)
- 对这个集合中的两个Cache行的Tag并行进行比较
- 根据比较结果确定信息在哪个行,或不在Cache中
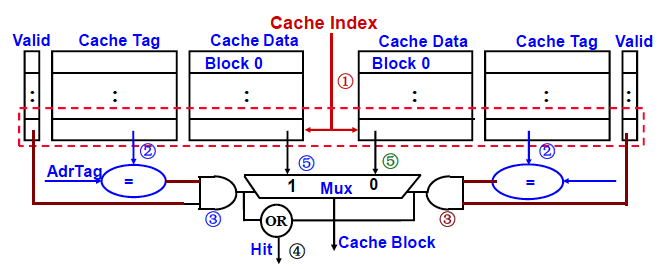
特点:结合直接映射和全相联映射的优点。当Cache组数为1时,变为全相联映射;当每组只有一个槽时,变为直接映射。
每组2或4行(称为2-路或4-路组相联)较常用。
通常每组4行以上很少用,只有在较大容量的L2 Cahce和L3 Cahce中使用 4-路以上。
| 可能的位置 | 关联度 | 缺失率 | 命中时间 | tag位数 | |
| 直接映射 | 唯一映射 | 最低,为1 | 最高 | 最小 | 最小 |
| 全相联映射 | 任意映射 | 最高,为Cache行数 | 最低(关联度越高命中率越高) | 最大 | 标记=主存块号 |
| N-路组相联映射 | N-路映射 | 居中,为N | 路数翻倍,增加1位 |
Cache替代算法:
- 先进先出FIFO (first-in-first-out)
FIFO的命中率并不随组的增大而提高。
- 最近最少用LRU ( least-recently used)
LRU的命中率随组的增大而提高。
LRU具体实现时,并不是通过移动块来实现的,而是通过给每个cache行设定一个计数器,根据计数值来记录这些主存块的使用情况。这个计数值称为LRU位。
计数器变化规则:
- 每组4行时,计数器有2位。计数值越小则说明越被常用。命中时,被访问行的计数器置0,比其低的计数器加1,其余不变。
- 未命中且该组未满时,新行计数器置为0,其余全加1。
- 未命中且该组已满时,计数值为3的那一行中的主存块被淘汰,新行计数器置为0,其余加1。
计数值为0的行中的主存块最常被访问,计数值为3的行中的主存块最不经常被访问,先被淘汰。
颠簸/乒乓(Thrashing / PingPong)现象:当分块局部化范围(即:某段时间集中访问的存储区)超过了Cache存储容量时,命中率变得很低。极端情况下,假设地址流是1、2、3、4、1、2、3、4、1……而Cache每组只有3行,那么,不管是FIFO,还是LRU算法,其命中率都为0。
- 最不经常用LFU ( least-frequently used)
- 随机替换算法(Random)
以下情况会出现Cache一致性问题:
- 因为Cache中的内容是主存块副本,当对Cache中的内容进行更新时,就存在Cache和主存如何保持一致的问题。
- 当多个设备都允许访问主存时。I/O设备可直接读写内存时,如果Cache中的内容被修改,则I/O设备读出的对应主存单元的内容无效;若I/O设备修改了主存单元的内容,则Cache中对应的内容无效。
- 当多个CPU都带有各自的Cache而共享主存时。某个CPU修改了自身Cache中的内容,则对应的主存单元和其他CPU中对应的内容都变为无效。
解决cache一致性问题的关键是处理好写操作。通常有两种写操作方式:
- 全写法Write Through(通写法、写直达法、直写法):
若写命中,则同时写cache和主存
若写不命中,则有以下两种处理方式:
(1)Write Allocate (写分配):先在主存块中更新相应存储单元, 然后分配一个cache行,将更新后的主存块装入分配的cache行中。该方法试图利用空间局部性,但每次写不命中都要从主存读一个块。
(2)Not Write Allocate (非写分配):直接写主存单元,不把主存块装入到Cache。该方法可以减少读入主存块的时间, 但没有很好利用空间局部性。
全写法在替换时不必将被替换的cache内容写回主存, 而且cache和主存的一致性能得到充分保证。但即使很少的存储指令也会极大增加CPI。
可以在 Cache 和 Memory之间加一个Write Buffer(写缓冲) ,它是一个FIFO队列,一般有4项,在存数频率不高时效果好。
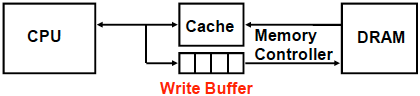
CPU同时写数据到Cache和Write Buffer;存控(Memory controller)将缓冲内容写主存
当频繁写时,易使写缓存饱和,发生阻塞。可以加一个二级Cache或者使用Write Back方式的Cache
- 回写法Write Back(一次性写方式、写回法):只写cache不写主存,缺失时一次写回,每行有个修改位dirty bit脏位,大大降低主存带宽需求,控制可能很复杂
由于回写法没有同步更新cache和主存内容, 所以存在cache和主存内容不一致而带来的潜在隐患。 通常需要其他的同步机制来保证存储信息的一致性。
总结:写不命中时,直写Cache可用非写分配或写分配;回写Cache一定用写分配
总结:

最好的情况是hit、hit、hit,此时,不需要访问主存
最坏的情况是miss、miss、miss需访问磁盘、并访存至少2次
hit、hit、miss和miss、hit、hit访存1次
miss、hit、miss不需访问磁盘、但访存至少2次