一、GitHub链接
GitHub链接
二、设计思路以及实现方法
本来是打算使用c++的,但是后面发现python的实现更加方便,可以调用库。
关于分词的方法和相似度的计算,查阅了一些资料后最后选用了jieba分词以及jaccard系数。使用jieba是因为python直接调用库方便实现,使用jaccard是因为在对比了各个分词之后发现jaccard更加适合文本类型的相似度计算。
代码设计图:
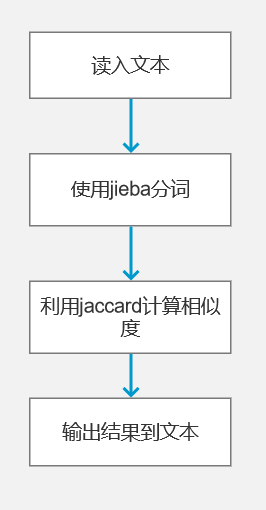
-
jieba分词法:
支持四种分词模式:
* 精确模式,试图将句子最精确地切开,适合文本分析;
jieba.cut(str, cut_all=False)
* 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
jieba.cut(str, cut_all=True)
* 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
jieba.cut_for_search(str)
* paddle模式,利用PaddlePaddle深度学习框架,训练序列标注(双向GRU)网络模型实现分词。同时支持词性标注。
jieba.cut(str,use_paddle=True)
这次代码中我选择了精准模式。 -
jaccard相似度:
给定两个集合A,B,Jaccard 系数定义为A与B交集的大小与A与B并集的大小的比值,定义如下:
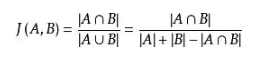
三、模块介绍
- 输入输出

f1 = open(argv[1],'r')
f2 = open(argv[2],'r')
f3 = open(argv[3],'w')
f1_text=f1.read()
f2_text=f2.read()
f3.write("...")
#print (f1.read())
f1.close()
f2.close()
f3.close()
-
jieba分词
def jieba_list(text): items="" s="" for i in range(0,len(text)): #存储中文 if 'u4e00' <= text[i] <= 'u9fff': s += text[i] elif text[i] == '。': if s != "": items += s s = "" if s != "": items += s s = "" #print(items) test_items = jieba.lcut(items, cut_all=True) return test_items -
jaccard相似度
def jaccard(text1,text2): #将分词去重 delete_text1 = set(text1) delete_text2 = set(text2) #print(delete_text1) #print(delete_text2) #记录相交分词的个数 temp = 0 for i in delete_text1: if i in delete_text2: temp += 1 fenmu = len(delete_text2) + len(delete_text1) - temp # 并集 jaccard_coefficient = float(temp / fenmu) # 交集 return jaccard_coefficient
四、结果输出
D:study编程专用pythonlearn1>python jaccard.py D:studysim_0.8s1.txt D:studysim_0.8s1.txt
Building prefix dict from the default dictionary ...
Loading model from cache C:Users57457AppDataLocalTempjieba.cache
Loading model cost 2.501 seconds.
Prefix dict has been built successfully.
1.0
D:study编程专用pythonlearn1>python jaccard.py D:studysim_0.8orig.txt D:studysim_0.8orig_0.8_add.txt
Building prefix dict from the default dictionary ...
Loading model from cache C:Users57457AppDataLocalTempjieba.cache
Loading model cost 1.772 seconds.
Prefix dict has been built successfully.
0.4635416666666667
D:study编程专用pythonlearn1>python jaccard.py D:studysim_0.8orig.txt D:studysim_0.8orig_0.8_del.txt
Building prefix dict from the default dictionary ...
Loading model from cache C:Users57457AppDataLocalTempjieba.cache
Loading model cost 1.799 seconds.
Prefix dict has been built successfully.
0.6505073280721533
D:study编程专用pythonlearn1>python jaccard.py D:studysim_0.8orig.txt D:studysim_0.8orig_0.8_dis_1.txt
Building prefix dict from the default dictionary ...
Loading model from cache C:Users57457AppDataLocalTempjieba.cache
Loading model cost 1.834 seconds.
Prefix dict has been built successfully.
0.9166666666666666
D:study编程专用pythonlearn1>python jaccard.py D:studysim_0.8orig.txt D:studysim_0.8orig_0.8_dis_3.txt
Building prefix dict from the default dictionary ...
Loading model from cache C:Users57457AppDataLocalTempjieba.cache
Loading model cost 2.310 seconds.
Prefix dict has been built successfully.
0.8378220140515222
D:study编程专用pythonlearn1>python jaccard.py D:studysim_0.8orig.txt D:studysim_0.8orig_0.8_dis_7.txt
Building prefix dict from the default dictionary ...
Loading model from cache C:Users57457AppDataLocalTempjieba.cache
Loading model cost 1.915 seconds.
Prefix dict has been built successfully.
0.7338842975206612
D:study编程专用pythonlearn1>python jaccard.py D:studysim_0.8orig.txt D:studysim_0.8orig_0.8_dis_10.txt
Building prefix dict from the default dictionary ...
Loading model from cache C:Users57457AppDataLocalTempjieba.cache
Loading model cost 2.036 seconds.
Prefix dict has been built successfully.
0.6769558275678552
D:study编程专用pythonlearn1>python jaccard.py D:studysim_0.8orig.txt D:studysim_0.8orig_0.8_dis_15.txt
Building prefix dict from the default dictionary ...
Loading model from cache C:Users57457AppDataLocalTempjieba.cache
Loading model cost 1.846 seconds.
Prefix dict has been built successfully.
0.4877932024892293
D:study编程专用pythonlearn1>python jaccard.py D:studysim_0.8orig.txt D:studysim_0.8orig_0.8_mix.txt
Building prefix dict from the default dictionary ...
Loading model from cache C:Users57457AppDataLocalTempjieba.cache
Loading model cost 2.271 seconds.
Prefix dict has been built successfully.
0.6966233766233766
D:study编程专用pythonlearn1>python jaccard.py D:studysim_0.8orig.txt D:studysim_0.8orig_0.8_rep.txt
Building prefix dict from the default dictionary ...
Loading model from cache C:Users57457AppDataLocalTempjieba.cache
Loading model cost 2.032 seconds.
Prefix dict has been built successfully.
0.3995140576188823
结果分析:和其他人的结果差距较大,根据分析应该是因为主要用的set和list并交集,把重复的字都省略了,导致最后得出的相似度较低。本来打算换成利用了sklearn的CounterVectorizer类和numpy的,但是sklearn库一直下载失败,就作罢了。
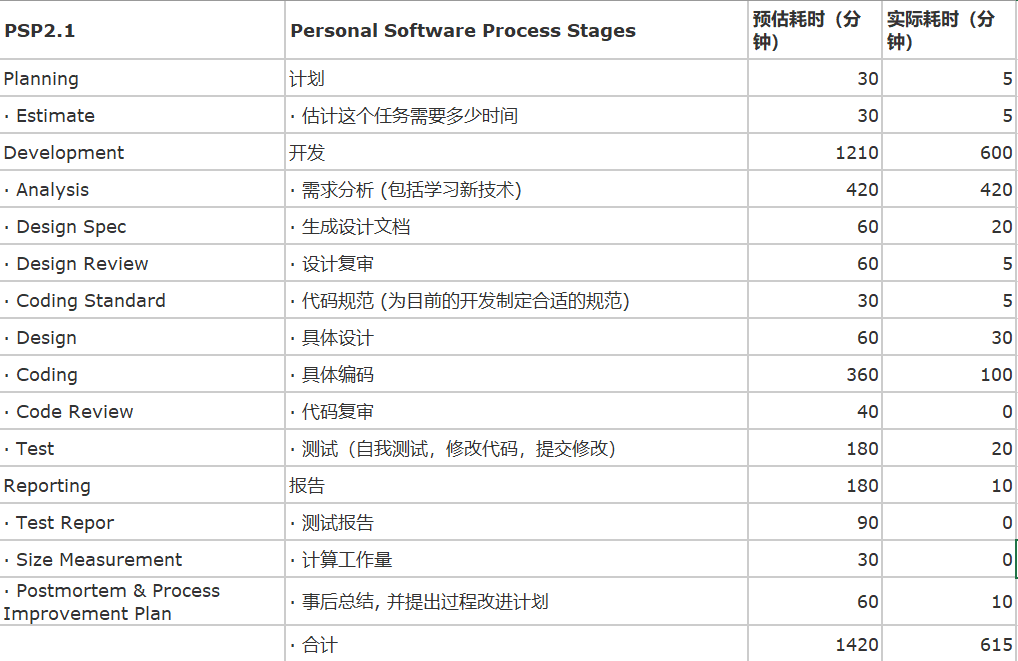
五、PSP表格