注:这次使用C语言做的这个程序。个别不懂的地方和算法部分是请教的其他同学,交流并吸收,所以收获颇多!
在程序中每一个地方我都做了注释,方便同学之间交流。也让老师容易看。程序也有很多不足的地方,但限于本人能力有限以及时间紧迫,难免出现很多问题,希望老师和同学能够帮助解决!
设计思路:(在代码中基本都做了注释,很好的体现了这里的设计思路)
1.这个程序首先我定义了一个结构体,内容包含单词的出现次数和单词的长度。
2.然后把所有单词出现的次数都设置为1,以便后面进行比较。
3.文件的读取工作很简单,以前学过。使用if((fp=fopen(filename,"r"))==NULL)语句即可。
4.然后开始识别单词,如果单词后面有空格则认为一个单词结束。使用flag标志,来进行确定。
5.最后根据出现次数进行排序,然后输出。
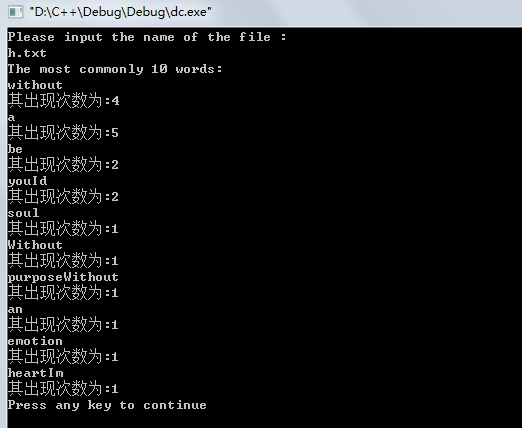
下面是程序读取文件后的运行结果:
代码部分:
#include<stdio.h> #include<stdlib.h> #include<string.h> struct S_word { int num; char a[15];// 单词的长度 }; int main() { struct S_word W[300]; //定义一个结构体W int i,m,n,k; char b[10]; // 用来和a【10】交换的数组 FILE *fp; // 定义文件 char ch; //从文件中读取字符 int flag=0; //标志空格后面是否有单词 int j=0; int temp; //排序时交换用 char filename[10]; /****************首先将出现次数均设置为1****************************/ for(i=0;i<300;i++) { W[i].num=1; } i=0; /****************首先将出现次数均设置为1****************************/ /****************打开文件****************************/ printf("Please input the name of the file : "); scanf("%s",filename); if((fp=fopen(filename,"r"))==NULL) { printf("error opening!"); exit(0); } /****************打开文件****************************/ /****************读取文件内容****************************/ while(!feof(fp)) { ch=fgetc(fp); W[i].a[j]='�'; if(ch>=65&&ch<=90||ch>=97&&ch<=122) { W[i].a[j]=ch; //识别单词 j++; flag=1; } else if(ch==' '&&flag==1) { flag=0; j=0; n=i; i++; if(n>=1) //每一个单词跟前面的比较,如果相同就使次数加一 { for(m=0;m<n;m++) { if(strcmp(W[n].a,W[m].a)==0) { W[m].num++; i=i-1; //如果单词相同则认为是一个单词 } } } } } /****************根据单词出现次数进行排序***************************/ for(n=0;n<i-1;n++) { k=n; for(j=n+1;j<i;j++) if(W[j].num>W[k].num) { k=j; temp=W[k].num; W[k].num=W[n].num; W[n].num=temp; strcpy(b,W[k].a); strcpy(W[k].a,W[n].a); strcpy(W[n].a,b); } } /****************根据单词出现次数进行排序**********/ /****************输出部分**************************/ printf("The most commonly 10 words: "); for(n=0;n<=9;n++) { printf("%s ",W[n].a); printf("其出现次数为:"); printf("%d ",W[n].num); } /****************输出部分**************************/ return 0; }