一、RBD
Ceph 可以同时提供对象存储RADOSGW、块存储RBD、文件系统存储Ceph FS,RBD 即RADOS Block Device 的简称,RBD 块存储是常用的存储类型之一,RBD 块设备类似磁盘可以被挂载,RBD 块设备具有快照、多副本、克隆和一致性等特性,数据以条带化的方式存储在Ceph 集群的多个OSD 中。
条带化技术就是一种自动的将I/O 的负载均衡到多个物理磁盘上的技术,条带化技术就是将一块连续的数据分成很多小部分并把他们分别存储到不同磁盘上去。这就能使多个进程同时访问数据的多个不同部分而不会造成磁盘冲突,而且在需要对这种数据进行顺序访问的时候可以获得最大程度上的I/O 并行能力,从而获得非常好的性能。

ceph osd pool create <pool_name> pg_mun pgp_mun pgp是对pg的数据进行组合存储,pgp通常等于pg ceph osd pool create myrbd1 64 64
ceph osd pool application enable myrbd1 rbd
rbd pool init -p myrbd1
rbd存储池并不能直接用于块设备,而是需要事先在其中按需创建映像(image),并把映像文件作为块设备使用,rbd 命令可用于创建、查看及删除块设备相在的映像(image),以及克隆映像、创建快照、将映像回滚到快照和查看快照等管理操作,例如,下面的命令能够创建一个名为myimg1 的映像。
在myrbd1的pool中创建一个mying1的rbd,其大小为5G rbd create mying1 --size 5G --pool myrbd1 后续步骤会使用myimg2 ,由于centos 系统内核较低无法挂载使用,因此只开启部分特性。除了layering 其他特性需要高版本内核支持 rbd create myimg2 --size 3G --pool myrbd1 --image-format 2 --image-feature layering
cephadmin@ceph-deploy:~/ceph-cluster$ rbd ls --pool myrbd1 mying1 mying2
cephadmin@ceph-deploy:~/ceph-cluster$ rbd --image mying1 --pool myrbd1 info rbd image 'mying1': size 5 GiB in 1280 objects order 22 (4 MiB objects) snapshot_count: 0 id: 144f88aecd24 block_name_prefix: rbd_data.144f88aecd24 format: 2 features: layering, exclusive-lock, object-map, fast-diff, deep-flatten #默认开启所有特性 op_features: flags: create_timestamp: Fri Aug 20 22:08:32 2021 access_timestamp: Fri Aug 20 22:08:32 2021 modify_timestamp: Fri Aug 20 22:08:32 2021 cephadmin@ceph-deploy:~/ceph-cluster$ rbd --image mying2 --pool myrbd1 info rbd image 'mying2': size 3 GiB in 768 objects order 22 (4 MiB objects) snapshot_count: 0 id: 1458dabfc2f1 block_name_prefix: rbd_data.1458dabfc2f1 format: 2 features: layering #手动配置仅开启layering唯一特性 op_features: flags: create_timestamp: Fri Aug 20 22:11:30 2021 access_timestamp: Fri Aug 20 22:11:30 2021 modify_timestamp: Fri Aug 20 22:11:30 2021
1)、当前ceph的使用状态
cephadmin@ceph-deploy:~/ceph-cluster$ ceph df --- RAW STORAGE --- CLASS SIZE AVAIL USED RAW USED %RAW USED hdd 300 GiB 300 GiB 168 MiB 168 MiB 0.05 TOTAL 300 GiB 300 GiB 168 MiB 168 MiB 0.05 --- POOLS --- POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL device_health_metrics 1 1 0 B 0 0 B 0 95 GiB myrbd1 2 64 405 B 7 48 KiB 0 95 GiB
wget -q -O- 'https://mirrors.tuna.tsinghua.edu.cn/ceph/keys/release.asc' | sudo apt-key add - echo "deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific bionic main" >> /etc/apt/source.list apt update
apt install -y ceph-common
cephadmin@ceph-deploy:~/ceph-cluster$ sudo scp ceph.conf ceph.client.admin.keyring root@172.168.32.111:/etc/ceph/
root@client:~# rbd --pool myrbd1 map mying2 /dev/rbd0 root@client:~# fdisk -l | grep rbd0 Disk /dev/rbd0: 3 GiB, 3221225472 bytes, 6291456 sectors
root@client:~# mkfs.xfs /dev/rbd0 root@client:~# mount /dev/rbd0 /mnt root@client:~# df -TH|grep rbd0 /dev/rbd0 xfs 3.3G 38M 3.2G 2% /mnt
root@client:~# dd if=/dev/zero of=/mnt/rbd_test bs=1M count=300 root@client:~# ll -h /mnt/rbd_test -rw-r--r-- 1 root root 300M Aug 20 22:40 /mnt/rbd_test
cephadmin@ceph-deploy:~/ceph-cluster$ ceph df --- RAW STORAGE --- CLASS SIZE AVAIL USED RAW USED %RAW USED hdd 300 GiB 298 GiB 2.0 GiB 2.0 GiB 0.67 TOTAL 300 GiB 298 GiB 2.0 GiB 2.0 GiB 0.67 --- POOLS --- POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL device_health_metrics 1 1 0 B 0 0 B 0 94 GiB myrbd1 2 64 310 MiB 95 931 MiB 0.32 94 GiB #myrbd1的pool中已经使用了300M数据
1)、在ceph-deploy上创建普通账号及权限
cephadmin@ceph-deploy:/etc/ceph$ ceph auth get-or-create client.kaka mon 'allow r' osd 'allow rwx pool=myrbd1' [client.kaka] key = AQC/ISNhUdzSDBAAgD7q6bPsEN0ymTh6B7rw8g== cephadmin@ceph-deploy:/etc/ceph$ ceph auth get client.kaka [client.kaka] key = AQC/ISNhUdzSDBAAgD7q6bPsEN0ymTh6B7rw8g== caps mon = "allow r" caps osd = "allow rwx pool=myrbd1" exported keyring for client.kaka
#创建空的keyring文件 cephadmin@ceph-deploy:/etc/ceph$ sudo ceph-authtool --create-keyring ceph.client.kaka.keyring creating ceph.client.kaka.keyring #导入client.kaka信息进入key.ring文件 cephadmin@ceph-deploy:/etc/ceph$ sudo ceph auth get client.kaka -o ceph.client.kaka.keyring exported keyring for client.kaka cephadmin@ceph-deploy:/etc/ceph$ sudo ceph-authtool -l ceph.client.kaka.keyring [client.kaka] key = AQC/ISNhUdzSDBAAgD7q6bPsEN0ymTh6B7rw8g== caps mon = "allow r" caps osd = "allow rwx pool=myrbd1"
#1、安装ceph源 root@client:~#wget -q -O- 'https://mirrors.tuna.tsinghua.edu.cn/ceph/keys/release.asc' | sudo apt-key add - root@client:~#echo "deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific bionic main" >> /etc/apt/source.list root@client:~#apt update #2、安装ceph-common root@client:~#apt install ceph-common
#同步ceph.conf和ceph.client.kaka.keyring到客户端 cephadmin@ceph-deploy:/etc/ceph$ sudo scp ceph.conf ceph.client.kaka.keyring 172.168.32.111:/etc/ceph/ #客户端验证 root@client:/etc/ceph# ls ceph.client.admin.keyring ceph.client.kaka.keyring ceph.client.ywx.keyring ceph.conf rbdmap #权限验证 root@client:/etc/ceph# ceph --user kaka -s cluster: id: f0e7c394-989b-4803-86c3-5557ae25e814 health: HEALTH_OK services: mon: 3 daemons, quorum ceph-mon01,ceph-mon02,ceph-mon03 (age 10h) mgr: ceph-mgr01(active, since 10h), standbys: ceph-mgr02 osd: 16 osds: 11 up (since 10h), 11 in (since 10h) data: pools: 2 pools, 65 pgs objects: 94 objects, 310 MiB usage: 2.0 GiB used, 218 GiB / 220 GiB avail pgs: 65 active+clean
使用前面创建的mying1的img文件
root@client:/etc/ceph# rbd --user kaka --pool myrbd1 map mying1 rbd: sysfs write failed RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable myrbd1/mying1 object-map fast-diff deep-flatten". In some cases useful info is found in syslog - try "dmesg | tail". rbd: map failed: (6) No such device or address rbd: --user is deprecated, use --id #rbd文件映射失败,问题为客户端的kernel版本过低,不支持object-map fast-diff deep-flatten等参数。 #ubuntu20.04支持上述参数
在ceph-deploy上创建img文件mying3,不添加object-map fast-diff deep-flatten等参数。
#创建img文件mying3,image-format格式为2,image特性值开启layering cephadmin@ceph-deploy:/etc/ceph$ rbd create mying3 --size 3G --pool myrbd1 --image-format 2 --image-feature layering cephadmin@ceph-deploy:/etc/ceph$ rbd ls --pool myrbd1 mying1 mying2 mying3
在客户端上重新映射mying3
root@client:/etc/ceph# rbd --user kaka --pool myrbd1 map mying3 /dev/rbd1 #验证,rbd1挂载成功 root@client:/etc/ceph# fdisk -l /dev/rbd1 Disk /dev/rbd1: 3 GiB, 3221225472 bytes, 6291456 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 4194304 bytes / 4194304 bytes #可以格式化使用
root@client:/etc/ceph# fdisk -l Disk /dev/sda: 50 GiB, 53687091200 bytes, 104857600 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0x870c4380 Device Boot Start End Sectors Size Id Type /dev/sda1 * 2048 104855551 104853504 50G 83 Linux Disk /dev/rbd1: 3 GiB, 3221225472 bytes, 6291456 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 4194304 bytes / 4194304 bytes #格式化rbd1磁盘 root@client:/etc/ceph# mkfs.ext4 /dev/rbd1 mke2fs 1.44.1 (24-Mar-2018) Discarding device blocks: done Creating filesystem with 786432 4k blocks and 196608 inodes Filesystem UUID: dae3f414-ceae-4535-97d4-c369820f3116 Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912 Allocating group tables: done Writing inode tables: done Creating journal (16384 blocks): done Writing superblocks and filesystem accounting information: done #把/dev/rbd1挂载到/mnt目录 root@client:/etc/ceph# mount /dev/rbd1 /mnt root@client:/etc/ceph# mount |grep /dev/rbd1 /dev/rbd1 on /mnt type ext4 (rw,relatime,stripe=1024,data=ordered) #在/mnt中创建一个200M的文件 root@client:/etc/ceph# cd /mnt root@client:/mnt# root@client:/mnt# root@client:/mnt# dd if=/dev/zero of=/mnt/rbd-test bs=1M count=200 200+0 records in 200+0 records out 209715200 bytes (210 MB, 200 MiB) copied, 0.205969 s, 1.0 GB/s root@client:/mnt# ll -h total 201M drwxr-xr-x 3 root root 4.0K Aug 23 13:06 ./ drwxr-xr-x 22 root root 326 Aug 17 09:56 ../ drwx------ 2 root root 16K Aug 23 13:04 lost+found/ -rw-r--r-- 1 root root 200M Aug 23 13:06 rbd-test
#挂载rbd 之后系统内核会自动加载libceph.ko 模块 root@client:/mnt# lsmod |grep ceph libceph 315392 1 rbd libcrc32c 16384 3 xfs,raid456,libceph
可以扩展空间,不建议缩小空间
#当前mying3的空间 cephadmin@ceph-deploy:/etc/ceph$ rbd ls --pool myrbd1 -l NAME SIZE PARENT FMT PROT LOCK mying1 5 GiB 2 mying2 3 GiB 2 mying3 3 GiB 2 #拉伸mying3的镜像为8G cephadmin@ceph-deploy:/etc/ceph$ rbd resize --pool myrbd1 --image mying3 --size 8G Resizing image: 100% complete...done. cephadmin@ceph-deploy:/etc/ceph$ rbd ls --pool myrbd1 -l NAME SIZE PARENT FMT PROT LOCK mying1 5 GiB 2 mying2 3 GiB 2 mying3 8 GiB 2 #在客户端可以发现/dev/rbd1已经是8G了,但是文件系统还是3G root@client:/mnt# df -Th /mnt Filesystem Type Size Used Avail Use% Mounted on /dev/rbd1 ext4 2.9G 209M 2.6G 8% /mnt root@client:/mnt# df -Th /dev/rbd1 Filesystem Type Size Used Avail Use% Mounted on /dev/rbd1 ext4 2.9G 209M 2.6G 8% /mnt #拉伸系统 #1、取消挂载 root@client:~# umount /mnt #2、拉伸/dev/rbd1 root@client:~# resize2fs /dev/rbd1 #3、重新挂载 root@client:~# mount /dev/rbd1 /mnt root@client:~# df -Th /dev/rbd1 Filesystem Type Size Used Avail Use% Mounted on /dev/rbd1 ext4 7.9G 214M 7.3G 3% /mnt root@client:~# df -Th /mnt Filesystem Type Size Used Avail Use% Mounted on /dev/rbd1 ext4 7.9G 214M 7.3G 3% /mnt
root@client:~#cat /etc/rc.d/rc.local rbd --user kaka -p myrbd1 map mying3 mount /dev/rbd1 /mnt [root@ceph-client2 ~]# chmod a+x /etc/rc.d/rc.local
1)查看镜像详细信息
cephadmin@ceph-deploy:/etc/ceph$ rbd --pool myrbd1 --image mying1 info rbd image 'mying1': size 5 GiB in 1280 objects order 22 (4 MiB objects) snapshot_count: 0 id: 144f88aecd24 block_name_prefix: rbd_data.144f88aecd24 format: 2 features: layering, exclusive-lock, object-map, fast-diff, deep-flatten #镜像特性 op_features: flags: create_timestamp: Fri Aug 20 22:08:32 2021 access_timestamp: Fri Aug 20 22:08:32 2021 modify_timestamp: Fri Aug 20 22:08:32 2021 cephadmin@ceph-deploy:/etc/ceph$ rbd --pool myrbd1 --image mying2 info rbd image 'mying2': size 3 GiB in 768 objects order 22 (4 MiB objects) snapshot_count: 0 id: 1458dabfc2f1 block_name_prefix: rbd_data.1458dabfc2f1 format: 2 features: layering op_features: flags: create_timestamp: Fri Aug 20 22:11:30 2021 access_timestamp: Fri Aug 20 22:11:30 2021 modify_timestamp: Fri Aug 20 22:11:30 2021
cephadmin@ceph-deploy:/etc/ceph$ rbd ls --pool myrbd1 -l --format json --pretty-format [ { "image": "mying1", "id": "144f88aecd24", "size": 5368709120, "format": 2 }, { "image": "mying2", "id": "1458dabfc2f1", "size": 3221225472, "format": 2 }, { "image": "mying3", "id": "1893f853e249", "size": 3221225472, "format": 2 } ]
cephadmin@ceph-deploy:/etc/ceph$ rbd help feature enable usage: rbd feature enable [--pool <pool>] [--namespace <namespace>] [--image <image>] [--journal-splay-width <journal-splay-width>] [--journal-object-size <journal-object-size>] [--journal-pool <journal-pool>] <image-spec> <features> [<features> ...] Enable the specified image feature. Positional arguments <image-spec> image specification (example: [<pool-name>/[<namespace>/]]<image-name>) <features> image features [exclusive-lock, object-map, journaling] Optional arguments -p [ --pool ] arg pool name --namespace arg namespace name --image arg image name --journal-splay-width arg number of active journal objects --journal-object-size arg size of journal objects [4K <= size <= 64M] --journal-pool arg pool for journal objects
特性简介
(1)layering: 支持镜像分层快照特性,用于快照及写时复制,可以对image 创建快照并保护,然后从快照克隆出新的image 出来,父子image 之间采用COW 技术,共享对象数据。 (2)striping: 支持条带化v2,类似raid 0,只不过在ceph 环境中的数据被分散到不同的对象中,可改善顺序读写场景较多情况下的性能。 (3)exclusive-lock: 支持独占锁,限制一个镜像只能被一个客户端使用。 (4)object-map: 支持对象映射(依赖exclusive-lock),加速数据导入导出及已用空间统计等,此特性开启的时候,会记录image 所有对象的一个位图,用以标记对象是否真的存在,在一些场景下可以加速io。 (5)fast-diff: 快速计算镜像与快照数据差异对比(依赖object-map)。 (6)deep-flatten: 支持快照扁平化操作,用于快照管理时解决快照依赖关系等。 (7)journaling: 修改数据是否记录日志,该特性可以通过记录日志并通过日志恢复数据(依赖独占锁),开启此特性会增加系统磁盘IO 使用。 (8)jewel 默认开启的特性包括: layering/exlcusive lock/object map/fast diff/deep flatten
cephadmin@ceph-deploy:/etc/ceph$ rbd --pool myrbd1 --image mying2 info rbd image 'mying2': size 3 GiB in 768 objects order 22 (4 MiB objects) snapshot_count: 0 id: 1458dabfc2f1 block_name_prefix: rbd_data.1458dabfc2f1 format: 2 features: layering op_features: flags: create_timestamp: Fri Aug 20 22:11:30 2021 access_timestamp: Fri Aug 20 22:11:30 2021 modify_timestamp: Fri Aug 20 22:11:30 2021 #启用指定存储池中的指定镜像的特性: cephadmin@ceph-deploy:/etc/ceph$ rbd feature enable exclusive-lock --pool myrbd1 --image mying2 cephadmin@ceph-deploy:/etc/ceph$ rbd feature enable object-map --pool myrbd1 --image mying2 cephadmin@ceph-deploy:/etc/ceph$ rbd feature enable fast-diff --pool myrbd1 --image mying2 #验证 cephadmin@ceph-deploy:/etc/ceph$ rbd --pool myrbd1 --image mying2 info rbd image 'mying2': size 3 GiB in 768 objects order 22 (4 MiB objects) snapshot_count: 0 id: 1458dabfc2f1 block_name_prefix: rbd_data.1458dabfc2f1 format: 2 features: layering, exclusive-lock, object-map, fast-diff #特性已开启 op_features: flags: object map invalid, fast diff invalid create_timestamp: Fri Aug 20 22:11:30 2021 access_timestamp: Fri Aug 20 22:11:30 2021 modify_timestamp: Fri Aug 20 22:11:30 2021
#禁用指定存储池中指定镜像的特性 cephadmin@ceph-deploy:/etc/ceph$ cephadmin@ceph-deploy:/etc/ceph$ rbd feature disable fast-diff --pool myrbd1 --image mying2 cephadmin@ceph-deploy:/etc/ceph$ rbd --pool myrbd1 --image mying2 info rbd image 'mying2': size 3 GiB in 768 objects order 22 (4 MiB objects) snapshot_count: 0 id: 1458dabfc2f1 block_name_prefix: rbd_data.1458dabfc2f1 format: 2 features: layering, exclusive-lock #fast-diff特性已关闭 op_features: flags: create_timestamp: Fri Aug 20 22:11:30 2021 access_timestamp: Fri Aug 20 22:11:30 2021 modify_timestamp: Fri Aug 20 22:11:30 2021
root@client:~#umount /mnt root@client:~#rbd --pool myrbd1 unmap mying3
镜像删除后数据也会被删除而且是无法恢复,因此在执行删除操作的时候要慎重。
cephadmin@ceph-deploy:/etc/ceph$ rbd help rm usage: rbd rm [--pool <pool>] [--namespace <namespace>] [--image <image>] [--no-progress] <image-spec> Delete an image. Positional arguments <image-spec> image specification (example: [<pool-name>/[<namespace>/]]<image-name>) Optional arguments -p [ --pool ] arg pool name --namespace arg namespace name --image arg image name --no-progress disable progress output #删除pool=myrbd1中的mying1镜像 cephadmin@ceph-deploy:/etc/ceph$ rbd rm --pool myrbd1 --image mying1 Removing image: 100% complete...done. cephadmin@ceph-deploy:/etc/ceph$ rbd ls --pool myrbd1 mying2 mying3
删除的镜像数据无法恢复,但是还有另外一种方法可以先把镜像移动到回收站,后期确认删除的时候再从回收站删除即可。
cephadmin@ceph-deploy:/etc/ceph$rbd trash --help status Show the status of this image. trash list (trash ls) List trash images. trash move (trash mv) Move an image to the trash. trash purge Remove all expired images from trash. trash remove (trash rm) Remove an image from trash. trash restore Restore an image from trash. #查看镜像的状态 cephadmin@ceph-deploy:/etc/ceph$ rbd status --pool=myrbd1 --image=mying3 Watchers: watcher=172.168.32.111:0/80535927 client.14665 cookie=18446462598732840962 cephadmin@ceph-deploy:/etc/ceph$ rbd status --pool=myrbd1 --image=mying2 Watchers: watcher=172.168.32.111:0/1284154910 client.24764 cookie=18446462598732840961 #将mying2进行移动到回收站 cephadmin@ceph-deploy:/etc/ceph$ rbd trash move --pool myrbd1 --image mying2 cephadmin@ceph-deploy:/etc/ceph$ rbd ls --pool myrbd1 mying3 #查看回收站的镜像 cephadmin@ceph-deploy:/etc/ceph$ rbd trash list --pool myrbd1 1458dabfc2f1 mying2 #1458dabfc2f1镜像ID,恢复镜像时需要使用ID #从回收站还原镜像 cephadmin@ceph-deploy:/etc/ceph$ rbd trash restore --pool myrbd1 --image mying2 --image-id 1458dabfc2f1 cephadmin@ceph-deploy:/etc/ceph$ rbd ls --pool myrbd1 -l NAME SIZE PARENT FMT PROT LOCK mying2 3 GiB 2 mying3 8 GiB 2 #永久删除回收站的镜像 #如果镜像不再使用,可以直接使用trash remove 将其从回收站删除 cephadmin@ceph-deploy:/etc/ceph$rbd trash remove --pool myrbd1 --image-id 1458dabfc2f1
1)、镜像快照命令
cephadmin@ceph-deploy:/etc/ceph$rbd help snap snap create (snap add) #创建快照 snap limit clear #清除镜像的快照数量限制 snap limit set #设置一个镜像的快照上限 snap list (snap ls) #列出快照 snap protect #保护快照被删除 snap purge #删除所有未保护的快照 snap remove (snap rm) #删除一个快照 snap rename #重命名快照 snap rollback (snap revert) #还原快照 snap unprotect #允许一个快照被删除(取消快照保护)
#在客户端查看当前数据 root@client:~# ll -h /mnt total 201M drwxr-xr-x 3 root root 4.0K Aug 23 13:06 ./ drwxr-xr-x 22 root root 326 Aug 17 09:56 ../ drwx------ 2 root root 16K Aug 23 13:04 lost+found/ -rw-r--r-- 1 root root 200M Aug 23 13:06 rbd-test #在ceph-deploy创建快照 cephadmin@ceph-deploy:/etc/ceph$ rbd help snap create usage: rbd snap create [--pool <pool>] [--namespace <namespace>] [--image <image>] [--snap <snap>] [--skip-quiesce] [--ignore-quiesce-error] [--no-progress] <snap-spec> cephadmin@ceph-deploy:/etc/ceph$ rbd snap create --pool myrbd1 --image mying3 --snap mying3-snap-20210823 Creating snap: 100% complete...done. #验证快照 cephadmin@ceph-deploy:/etc/ceph$ rbd snap list --pool myrbd1 --image mying3 SNAPID NAME SIZE PROTECTED TIMESTAMP 4 mying3-snap-20210823 8 GiB Mon Aug 23 14:01:30 2021
#客户端删除数据,并卸载rbd root@client:~# rm -rf /mnt/rbd-test root@client:~# ll /mnt total 20 drwxr-xr-x 3 root root 4096 Aug 23 14:03 ./ drwxr-xr-x 22 root root 326 Aug 17 09:56 ../ drwx------ 2 root root 16384 Aug 23 13:04 lost+found/ root@client:~# umount /mnt root@client:~# rbd --pool myrbd1 unmap --image mying3 #使用快照恢复数据 root@client:~# rbd help snap rollback usage: rbd snap rollback [--pool <pool>] [--namespace <namespace>] [--image <image>] [--snap <snap>] [--no-progress] <snap-spec> #回滚快照 cephadmin@ceph-deploy:/etc/ceph$ sudo rbd snap rollback --pool myrbd1 --image mying3 --snap mying3-snap-20210823 Rolling back to snapshot: 100% complete...done. #在客户端验证 root@client:~# rbd --pool myrbd1 map mying3 /dev/rbd1 root@client:~# mount /dev/rbd1 /mnt root@client:~# ll -h /mnt total 201M drwxr-xr-x 3 root root 4.0K Aug 23 13:06 ./ drwxr-xr-x 22 root root 326 Aug 17 09:56 ../ drwx------ 2 root root 16K Aug 23 13:04 lost+found/ -rw-r--r-- 1 root root 200M Aug 23 13:06 rbd-test #数据恢复成功
cephadmin@ceph-deploy:/etc/ceph$ rbd snap list --pool myrbd1 --image mying3 SNAPID NAME SIZE PROTECTED TIMESTAMP 4 mying3-snap-20210823 8 GiB Mon Aug 23 14:01:30 2021 cephadmin@ceph-deploy:/etc/ceph$ rbd snap rm --pool myrbd1 --image mying3 --snap mying3-snap-20210823 Removing snap: 100% complete...done. cephadmin@ceph-deploy:/etc/ceph$ rbd snap list --pool myrbd1 --image mying3 cephadmin@ceph-deploy:/etc/ceph$
#设置与修改快照数量限制 cephadmin@ceph-deploy:/etc/ceph$ rbd snap limit set --pool myrbd1 --image mying3 --limit 30 cephadmin@ceph-deploy:/etc/ceph$ rbd snap limit set --pool myrbd1 --image mying3 --limit 20 cephadmin@ceph-deploy:/etc/ceph$ rbd snap limit set --pool myrbd1 --image mying3 --limit 15 #清除快照数量限制 cephadmin@ceph-deploy:/etc/ceph$ rbd snap limit clear --pool myrbd1 --image mying3
ceph FS 即ceph filesystem,可以实现文件系统共享功能,客户端通过ceph 协议挂载并使用ceph 集群作为数据存储服务器。 Ceph FS 需要运行Meta Data Services(MDS)服务,其守护进程为ceph-mds,ceph-mds 进程管理与cephFS 上存储的文件相关的元数据,并协调对ceph 存储集群的访问。
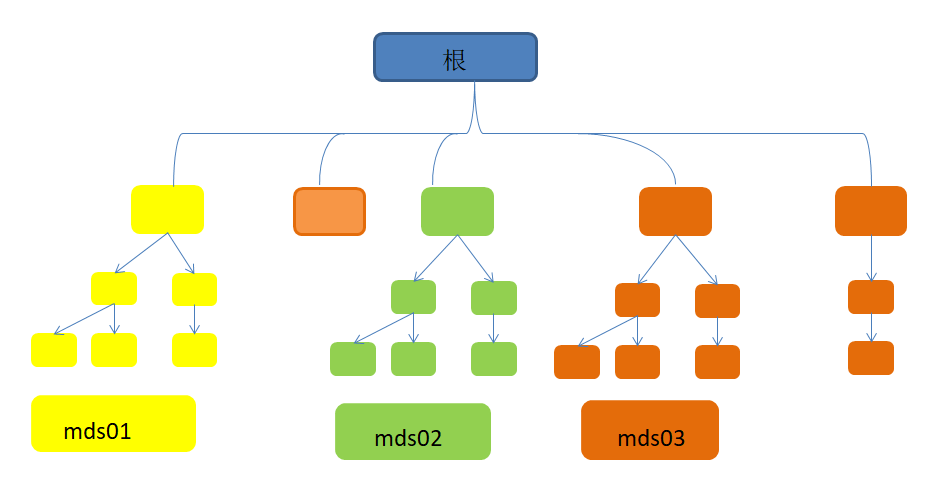
cephadmin@ceph-deploy:~/ceph-cluster$ ceph mds stat
mycephfs:2 {0=ceph-mds01=up:active,1=ceph-mgr02=up:active} 2 up:standby
#创建kingseal普通用户 cephadmin@ceph-deploy:~/ceph-cluster$ sudo ceph auth add client.kingseal mon 'allow r' mds "allow rw" osd "allow rwx pool=cephfs-data" added key for client.kingseal #验证用户 cephadmin@ceph-deploy:~/ceph-cluster$ sudo ceph auth get client.kingseal [client.kingseal] key = AQCDWSZhj1yTJRAASUnXfwFkKab1CrIJV/5uDw== caps mds = "allow rw" caps mon = "allow r" caps osd = "allow rwx pool=cephfs-data" exported keyring for client.kingseal #创建kingseal的空keyring cephadmin@ceph-deploy:~/ceph-cluster$ ceph-authtool --create-keyring ceph.client.kingseal.keyring creating ceph.client.kingseal.keyring #将用户信息导入keyring文件 cephadmin@ceph-deploy:~/ceph-cluster$ ceph auth get client.kingseal -o ceph.client.kingseal.keyring exported keyring for client.kingseal #创建key文件,cephfs挂载使用 cephadmin@ceph-deploy:~/ceph-cluster$ ceph auth print-key client.kingseal AQCDWSZhj1yTJRAASUnXfwFkKab1CrIJV/5uDw==
cephadmin@ceph-deploy:~/ceph-cluster$scp ceph.conf ceph.client.kingseal.keyring kingseal.key 172.168.32.111:/etc/ceph
root@client:~# ceph --user kingseal -s
cluster:
id: fdefc83b-1ef9-4986-a4c1-8af7603f43bf
health: HEALTH_WARN
clock skew detected on mon.ceph-mon03
services:
mon: 3 daemons, quorum ceph-mon01,ceph-mon02,ceph-mon03 (age 37m)
mgr: ceph-mgr01(active, since 56m), standbys: ceph-mgr02
mds: 2/2 daemons up, 2 standby
osd: 16 osds: 16 up (since 41m), 16 in (since 41m)
data:
volumes: 1/1 healthy
pools: 3 pools, 97 pgs
objects: 41 objects, 3.6 KiB
usage: 104 MiB used, 800 GiB / 800 GiB avail
pgs: 97 active+clean
客户端挂载有两种方式,一是内核空间一是用户空间,内核空间挂载需要内核支持ceph 模块,用户空间挂载需要安装ceph-fuse。
(1)客户端通过key文件挂载
#创建挂载目录cephfs-key root@client:~# mkdir /cephfs-key #挂载cephfs root@client:~# mount -t ceph 172.168.32.104:6789,172.168.32.105:6789,172.168.32.106:6789:/ /cephfs-key -o name=kingseal,secretfile=/etc/ceph/kingseal.key #注意:172.168.32.104:6789,172.168.32.105:6789,172.168.32.106:6789为ceph-mon地址和端口
root@client:~# cat /etc/ceph/kingseal.key AQCDWSZhj1yTJRAASUnXfwFkKab1CrIJV/5uDw== root@client:~# mount -t ceph 172.168.32.104:6789,172.168.32.105:6789,172.168.32.106:6789:/ /cephfs-key -o name=kingseal,secret=AQCDWSZhj1yTJRAASUnXfwFkKab1CrIJV/5uDw==
客户端内核加载ceph.ko 模块挂载cephfs 文件系统
root@client:~# lsmod | grep ceph ceph 376832 1 libceph 315392 1 ceph fscache 65536 1 ceph libcrc32c 16384 3 xfs,raid456,libceph root@client:~# modinfo ceph filename: /lib/modules/4.15.0-112-generic/kernel/fs/ceph/ceph.ko license: GPL description: Ceph filesystem for Linux author: Patience Warnick <patience@newdream.net> author: Yehuda Sadeh <yehuda@hq.newdream.net> author: Sage Weil <sage@newdream.net> alias: fs-ceph srcversion: B2806F4EAACAC1E19EE7AFA depends: libceph,fscache retpoline: Y intree: Y name: ceph vermagic: 4.15.0-112-generic SMP mod_unload signat: PKCS#7 signer: sig_key: sig_hashalgo: md4
如果内核本较低而没有ceph 模块,那么可以安装ceph-fuse 挂载,但是推荐使用内核模块挂载。
#安装ceph-fuse apt install ceph-fuse #创建挂载目录ceph-fsus mkdir ceph-fsus #使用ceph-fsus挂载 root@client:~# ll /etc/ceph/ total 32 drwxr-xr-x 2 root root 126 Aug 25 23:07 ./ drwxr-xr-x 100 root root 8192 Aug 25 23:07 ../ -rw------- 1 root root 151 Aug 25 22:49 ceph.client.admin.keyring -rw------- 1 root root 152 Aug 25 23:02 ceph.client.kingseal.keyring -rw-r--r-- 1 root root 516 Aug 25 23:02 ceph.conf -rw-r--r-- 1 root root 40 Aug 25 23:02 kingseal.key -rw-r--r-- 1 root root 92 Jun 7 22:39 rbdmap #client.kingseal为ceph.client.kingseal.keyring root@client:~# ceph-fuse --name client.kingseal -m 172.168.32.104:6789,172.168.32.105:6789,172.168.32.106:6789 ceph-fsus/ ceph-fuse[5569]: starting ceph client 2021-08-25T23:28:07.140+0800 7f4feeea9100 -1 init, newargv = 0x55a107cc4920 newargc=15 ceph-fuse[5569]: starting fuse
root@client:~# df -Th ...... 172.168.32.104:6789,172.168.32.105:6789,172.168.32.106:6789:/ ceph 254G 0 254G 0% /cephfs-key ceph-fuse fuse.ceph-fuse 254G 0 254G 0% /root/ceph-fsus
(1)fstab
cat /etc/fstab 172.168.32.104:6789,172.168.32.105:6789,172.168.32.106:6789:/ /cephfs-key ceph defaults,name=kingseal,secretfile=/etc/ceph/kingseal.key,_netdev 0 0
chmod +x /etc/rc.local cat /etc/rc.local mount -t ceph 172.168.32.104:6789,172.168.32.105:6789,172.168.32.106:6789:/ /cephfs-key -o name=kingseal,secretfile=/etc/ceph/kingseal.key
1、RadosGW对象存储说明
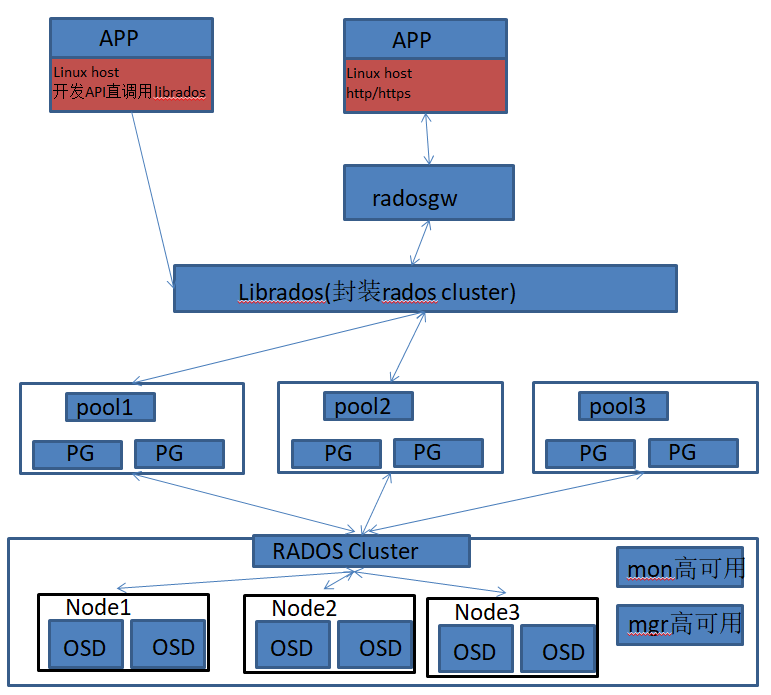
RadosGW 是对象存储(OSS,Object Storage Service)的一种实现方式,RADOS 网关也称为Ceph对象网关、RADOSGW、RGW,是一种服务,使客户端能够利用标准对象存储API 来访问Ceph集群,它支持AWS S3 和Swift API,rgw 运行于librados 之上,在ceph 0.8 版本之后使用Civetweb的web 服务器来响应api 请求,可以使用nginx 或或者apache 替代,客户端基于http/https协议通过RESTful API 与rgw 通信,而rgw 则使用librados 与ceph 集群通信,rgw 客户端通过s3 或者swift api 使用rgw 用户进行身份验证,然后rgw 网关代表用户利用cephx 与ceph存储进行身份验证。
S3 由Amazon 于2006 年推出,全称为Simple Storage Service,S3 定义了对象存储,是对象存储事实上的标准,从某种意义上说,S3 就是对象存储,对象存储就是S3,它对象存储市场的霸主,后续的对象存储都是对S3 的模仿。
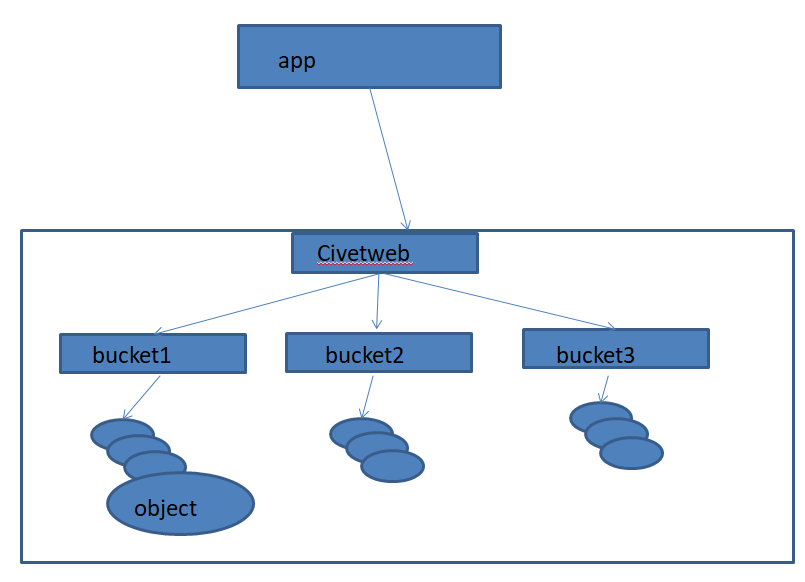
1)通过对象存储将数据存储为对象,每个对象除了包含数据,还包含数据自身的元数据。 2)对象通过Object ID 来检索,无法通过普通文件系统的方式通过文件路径及文件名称操作来直接访问对象,只能通过API 来访问,或者第三方客户端(实际上也是对API 的封装)。 3)对象存储中的对象不整理到目录树中,而是存储在扁平的命名空间中,Amazon S3 将这个扁平命名空间称为bucket,而swift 则将其称为容器。 4)无论是bucket 还是容器,都不能嵌套。 5)bucket 需要被授权才能访问到,一个帐户可以对多个bucket 授权,而权限可以不同。 6)方便横向扩展、快速检索数据。 7)不支持客户端挂载,且需要客户端在访问的时候指定文件名称。 8)不是很适用于文件过于频繁修改及删除的场景。
bucket 特性:
1)存储空间是您用于存储对象(Object)的容器,所有的对象都必须隶属于某个存储空间,可以设置和修改存储空间属性用来控制地域、访问权限、生命周期等,这些属性设置直接作用于该存储空间内所有对象,因此您可以通过灵活创建不同的存储空间来完成不同的管理功能。 2)同一个存储空间的内部是扁平的,没有文件系统的目录等概念,所有的对象都直接隶属于其对应的存储空间。 3)每个用户可以拥有多个存储空间 4)存储空间的名称在OSS 范围内必须是全局唯一的,一旦创建之后无法修改名称。 5)存储空间内部的对象数目没有限制。
1)只能包括小写字母、数字和短横线(-)。 2)必须以小写字母或者数字开头和结尾。 3)长度必须在3-63 字节之间
Radosgw的架构图
Radosgw的逻辑图
1)Amazon S3:提供了user、bucket 和object 分别表示用户、存储桶和对象,其中bucket 隶属于user,可以针对user 设置不同bucket 的名称空间的访问权限,而且不同用户允许访问相同的bucket。 2)OpenStack Swift:提供了user、container 和object 分别对应于用户、存储桶和对象,不过它还额外为user 提供了父级组件account,用于表示一个项目或租户,因此一个account 中可包含一到多个user,它们可共享使用同一组container,并为container 提供名称空间。 3)RadosGW:提供了user、subuser、bucket 和object,其中的user 对应于S3 的user,而subuser则对应于Swift 的user,不过user 和subuser 都不支持为bucket 提供名称空间,因此,不同用户的存储桶也不允许同名;不过,自Jewel 版本起,RadosGW 引入了tenant(租户)用于为user 和bucket 提供名称空间,但它是个可选组件,RadosGW 基于ACL 为不同的用户设置不同的权限控制,如: Read 读加执行权限 Write 写权限 Readwrite 只读 full-control 全部控制权限
radosgw是部署在ceph-mgr01和ceph-mgr02上
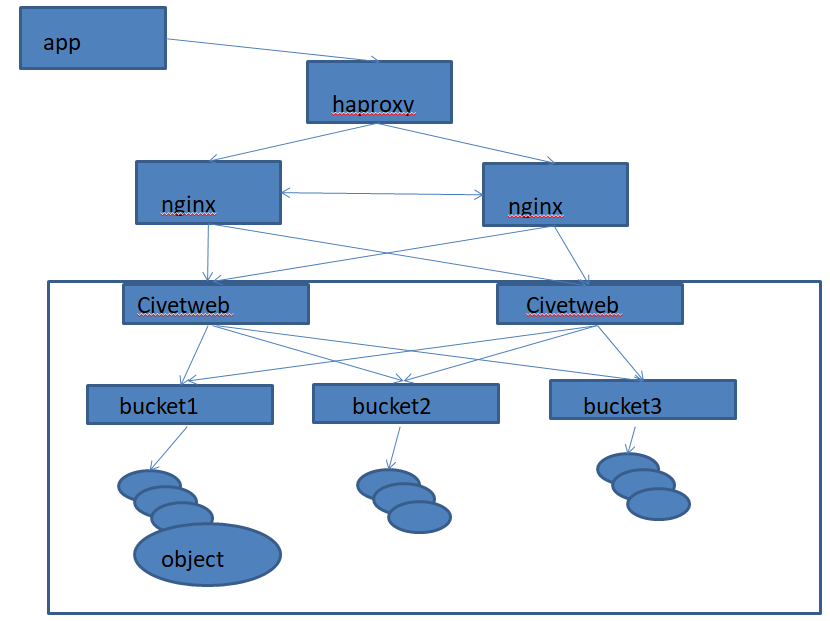
4.2自定义radosgw的端口
配置文件可以在ceph deploy 服务器修改然后统一推送,或者单独修改每个radosgw 服务器的配置为同一配置。
修改默认端口7480为8080端口,在ceph-deploy上配置,并推送个其它所有节点。
ceph-deploy上修改ceph.conf文件
cephadmin@ceph-deploy:~/ceph-cluster$cat ceph.conf [global] fsid = c31ea2e3-47f7-4247-9d12-c0bf8f1dfbfb public_network = 172.168.0.0/16 cluster_network = 10.0.0.0/16 mon_initial_members = ceph-mon01 mon_host = 172.168.32.104 auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx [mds.ceph-mds02] #mds_standby_for_fscid = mycephfs mds_standby_for_name = ceph-mds01 mds_standby_replay = true [mds.ceph-mds03] mds_standby_for_name = ceph-mgr02 mds_standby_replay = true #增加以下内容,client.rgw后面为主机名 [client.rgw.ceph-mgr02] rgw_host = ceph-mgr02 rgw_frontends = civetweb port=8080 [client.rgw.ceph-mgr01] rgw_host = ceph-mgr01 rgw_frontends = civetweb port=8080
将配置文件推送到集群其它节点中
# 推送完成之后,所有节点的/etc/ceph/ceph.conf配置文件将和上面一致
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy --overwrite-conf config push ceph-mgr{01..02}
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy --overwrite-conf config push ceph-mon{01..03}
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy --overwrite-conf config push ceph-node{01..03}
重启前查看radosgw的端口为7480
root@ceph-mgr02:~# ss -antlp|grep 7480
LISTEN 0 128 0.0.0.0:7480 0.0.0.0:* users:(("radosgw",pid=13832,fd=74))
LISTEN 0 128 [::]:7480 [::]:* users:(("radosgw",pid=13832,fd=75))
root@ceph-mgr01:~# ps -ef|grep radosgw
ceph 13551 1 0 15:19 ? 00:00:58 /usr/bin/radosgw -f --cluster ceph --name client.rgw.ceph-mgr01 --setuser ceph --setgroup ceph
root@ceph-mgr02:~# ps -ef|grep radosgw
ceph 13832 1 0 15:19 ? 00:00:55 /usr/bin/radosgw -f --cluster ceph --name client.rgw.ceph-mgr02 --setuser ceph --setgroup ceph
root@ceph-mgr01:~# systemctl restart ceph-radosgw@rgw.ceph-mgr01
root@ceph-mgr02:~# systemctl restart ceph-radosgw@rgw.ceph-mgr02
#查看radosgw的端口该为了8080
root@ceph-mgr02:~# ss -antlp|grep 8080
LISTEN 0 128 0.0.0.0:8080 0.0.0.0:* users:(("radosgw",pid=15954,fd=69))
验证
cephadmin@ceph-deploy:~/ceph-cluster$ curl 172.168.32.102:8080 <?xml version="1.0" encoding="UTF-8"?><ListAllMyBucketsResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/"><Owner><ID>anonymous</ID><DisplayName></DisplayName></Owner><Buckets></Buckets></ListAllMyBucketsResult> cephadmin@ceph-deploy:~/ceph-cluster$ curl 172.168.32.103:8080 <?xml version="1.0" encoding="UTF-8"?><ListAllMyBucketsResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/"><Owner><ID>anonymous</ID><DisplayName></DisplayName></Owner><Buckets></Buckets></ListAllMyBucketsResult>
4.3 启用radosgw的ssl配置
仅在ceph-mgr01上配置
在ceph-mgr01上配置自签名证书
openssl req -newkey rsa:4096 -nodes -sha256 -keyout ca.key -x509 -days 3650 -out ca.crt openssl req -newkey rsa:4096 -nodes -sha256 -keyout civetweb.key -out civetweb.csr openssl x509 -req -days 3650 -in civetweb.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out civetweb.crt #验证证书 root@ceph-mgr01:/etc/ceph/certs# ll total 24 drwxr-xr-x 2 root root 108 Aug 30 23:34 ./ drwxr-xr-x 3 root root 117 Aug 30 23:23 ../ -rw-r--r-- 1 root root 2106 Aug 30 23:32 ca.crt -rw------- 1 root root 3268 Aug 30 23:31 ca.key -rw-r--r-- 1 root root 41 Aug 30 23:34 ca.srl -rw-r--r-- 1 root root 1996 Aug 30 23:34 civetweb.crt -rw-r--r-- 1 root root 1744 Aug 30 23:33 civetweb.csr -rw------- 1 root root 3272 Aug 30 23:32 civetweb.key #将证书导入为civetweb.pem root@ceph-mgr01:/etc/ceph/certs# cat civetweb.key civetweb.crt > civetweb.pem root@ceph-mgr01:/etc/ceph/certs# tree . ├── ca.crt ├── ca.key ├── ca.srl ├── civetweb.crt ├── civetweb.csr ├── civetweb.key └── civetweb.pem
注意:在生产案例中ceph-mgr01和ceph-mgr02都要配置,并且所有节点的ceph.conf的配置文件都必须一样
root@ceph-mgr01:/etc/ceph/certs# vim /etc/ceph/ceph.conf [global] fsid = c31ea2e3-47f7-4247-9d12-c0bf8f1dfbfb public_network = 172.168.0.0/16 cluster_network = 10.0.0.0/16 mon_initial_members = ceph-mon01 mon_host = 172.168.32.104 auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx [mds.ceph-mds02] #mds_standby_for_fscid = mycephfs mds_standby_for_name = ceph-mds01 mds_standby_replay = true [mds.ceph-mds03] mds_standby_for_name = ceph-mgr02 mds_standby_replay = true [client.rgw.ceph-mgr02] rgw_host = ceph-mgr02 rgw_frontends = civetweb port=8080 [client.rgw.ceph-mgr01] rgw_host = ceph-mgr01 #ssl配置 rgw_frontends = "civetweb port=8080+8443s ssl_certificate=/etc/ceph/certs/civetweb.pem"
在ceph-mgr01上重启radosgw
root@ceph-mgr01:/etc/ceph/certs# ps -ef|grep radosgw ceph 17393 1 0 22:19 ? 00:00:12 /usr/bin/radosgw -f --cluster ceph --name client.rgw.ceph-mgr01 --setuser ceph --setgroup ceph root 18454 18265 0 23:40 pts/0 00:00:00 grep --color=auto radosgw root@ceph-mgr01:/etc/ceph/certs# systemctl restart ceph-radosgw@rgw.ceph-mgr01.service
在ceph-mgr01上验证端口
root@ceph-mgr01:/etc/ceph/certs# ss -antlp|grep 8443
LISTEN 0 128 0.0.0.0:8443 0.0.0.0:* users:(("radosgw",pid=18459,fd=72))
验证
cephadmin@ceph-deploy:~/ceph-cluster$ curl http://172.168.32.102:8080 <?xml version="1.0" encoding="UTF-8"?><ListAllMyBucketsResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/"><Owner><ID>anonymous</ID><DisplayName></DisplayName></Owner><Buckets></Buckets></ListAllMyBucketsResult> cephadmin@ceph-deploy:~/ceph-cluster$ curl -k https://172.168.32.102:8443 <?xml version="1.0" encoding="UTF-8"?><ListAllMyBucketsResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/"><Owner><ID>anonymous</ID><DisplayName></DisplayName></Owner><Buckets></Buckets></ListAllMyBucketsResult>
#创建日志目录 root@ceph-mgr01:/etc/ceph/certs# mkdir /var/log/radosgw root@ceph-mgr01:/etc/ceph/certs# chown ceph.ceph /var/log/radosgw #修改ceph-mgr01的ceph.conf配置 [global] fsid = c31ea2e3-47f7-4247-9d12-c0bf8f1dfbfb public_network = 172.168.0.0/16 cluster_network = 10.0.0.0/16 mon_initial_members = ceph-mon01 mon_host = 172.168.32.104 auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx [mds.ceph-mds02] #mds_standby_for_fscid = mycephfs mds_standby_for_name = ceph-mds01 mds_standby_replay = true [mds.ceph-mds03] mds_standby_for_name = ceph-mgr02 mds_standby_replay = true [client.rgw.ceph-mgr02] rgw_host = ceph-mgr02 rgw_frontends = civetweb port=8080 [client.rgw.ceph-mgr01] rgw_host = ceph-mgr01 #配置日志文件、超时时间及线程数 rgw_frontends = "civetweb port=8080+8443s ssl_certificate=/etc/ceph/certs/civetweb.pem request_timeout_ms=3000 error_log_file=/var/log/radosgw/civetweb.error.log access_log_file=/var/log/radosgw/civetweb.access.log num_threads=100"
重启ceph-mgr01上radosgw
root@ceph-mgr01:/etc/ceph/certs# ps -ef|grep radosgw ceph 18459 1 0 23:41 ? 00:00:01 /usr/bin/radosgw -f --cluster ceph --name client.rgw.ceph-mgr01 --setuser ceph --setgroup ceph root@ceph-mgr01:/etc/ceph/certs# systemctl restart ceph-radosgw@rgw.ceph-mgr01.service
cephadmin@ceph-deploy:~/ceph-cluster$ curl -k https://172.168.32.102:8443 cephadmin@ceph-deploy:~/ceph-cluster$ curl -k https://172.168.32.102:8443 cephadmin@ceph-deploy:~/ceph-cluster$ curl -k https://172.168.32.102:8443 #在ceph-mgr01上查看访问日志 root@ceph-mgr01:/etc/ceph/certs# tail -10 /var/log/radosgw/civetweb.access.log 172.168.32.101 - - [30/Aug/2021:23:54:17 +0800] "GET / HTTP/1.1" 200 413 - curl/7.58.0 172.168.32.101 - - [30/Aug/2021:23:54:18 +0800] "GET / HTTP/1.1" 200 413 - curl/7.58.0 172.168.32.101 - - [30/Aug/2021:23:54:18 +0800] "GET / HTTP/1.1" 200 413 - curl/7.58.0 172.168.32.101 - - [30/Aug/2021:23:54:19 +0800] "GET / HTTP/1.1" 200 413 - curl/7.58.0
5.1)创建radosgw用户
在ceph-deploy上创建radosgwadmin账户
cephadmin@ceph-deploy:~/ceph-cluster$ radosgw-admin user create --uid=radosgwadmin --display-name='radosgwadmin'
{
"user_id": "radosgwadmin",
"display_name": "radosgwadmin",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"subusers": [],
"keys": [
{
"user": "radosgwadmin",
"access_key": "N4CFRDJ2O503H3QMA30Y",
"secret_key": "68Ude2uJmCMRHhV9HpABujFMtcd9ZS2NVsBz6RG8"
}
],
"swift_keys": [],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"default_storage_class": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
}
#使用下面命令查看已创建的账户信息
root@ceph-mgr01:/etc/ceph/certs# radosgw-admin user info --uid=radosgwadmin --display-name='radosgwadmin'
s3cmd是一个通过命令行访问ceph RGW实现创建存储桶、上传、下载及管理数据到对象存储的命令行客户端工具
root@client:~# apt install -y s3cmd
root@client:~# s3cmd --configure Enter new values or accept defaults in brackets with Enter. Refer to user manual for detailed description of all options. Access key and Secret key are your identifiers for Amazon S3. Leave them empty for using the env variables. Access Key: N4CFRDJ2O503H3QMA30Y # 粘贴服务端生成的Access Key Secret Key: 68Ude2uJmCMRHhV9HpABujFMtcd9ZS2NVsBz6RG8 # 粘贴服务端生成的Secret Key Default Region [US]: # 直接回车即可 Use "s3.amazonaws.com" for S3 Endpoint and not modify it to the target Amazon S3. S3 Endpoint [s3.amazonaws.com]: 172.168.32.102:8080 # 输入对象存储的IP地址,可以为域名和radosgw的VIP Use "%(bucket)s.s3.amazonaws.com" to the target Amazon S3. "%(bucket)s" and "%(location)s" vars can be used if the target S3 system supports dns based buckets. DNS-style bucket+hostname:port template for accessing a bucket [%(bucket)s.s3.amazonaws.com]: 172.168.32.102:8080/%(bucket) # 输入对象存储的bucket地址 Encryption password is used to protect your files from reading by unauthorized persons while in transfer to S3 Encryption password: # 空密码回车 Path to GPG program [/usr/bin/gpg]: # /usr/bin/gpg命令路径 回车 When using secure HTTPS protocol all communication with Amazon S3 servers is protected from 3rd party eavesdropping. This method is slower than plain HTTP, and can only be proxied with Python 2.7 or newer Use HTTPS protocol [Yes]: no # 是否使用https,选no On some networks all internet access must go through a HTTP proxy. Try setting it here if you can't connect to S3 directly HTTP Proxy server name: # haproxy 留空回车 New settings: Access Key: D028HA7T16KJHU2602YA Secret Key: RWczKVORMdDBw2mtgLs2dUPq2xrCehnjOtB6pHPY Default Region: US S3 Endpoint: 192.168.5.91 DNS-style bucket+hostname:port template for accessing a bucket: %(bucket).172.168.32.102 Encryption password: Path to GPG program: /usr/bin/gpg Use HTTPS protocol: False HTTP Proxy server name: HTTP Proxy server port: 0 Test access with supplied credentials? [Y/n] y #测试通过会提示保存 Please wait, attempting to list all buckets... Success. Your access key and secret key worked fine :-) Now verifying that encryption works... Not configured. Never mind. Save settings? [y/N] y # y 要保存配置文件 Configuration saved to '/root/.s3cfg' # 最后配置文件保存的位置/root.s3cfg
# 创建my-bucket桶 root@client:~# s3cmd mb s3://my-bucket Bucket 's3://my-bucket/' created # 查看所有的桶 root@client:~# s3cmd ls 2021-08-30 16:42 s3://my-bucket # 向指定桶中上传/etc/hosts文件 root@client:~# s3cmd put /etc/hosts s3://my-bucket upload: '/etc/hosts' -> 's3://my-bucket/hosts' [1 of 1] 186 of 186 100% in 1s 93.30 B/s done #向指定目录下载文件 root@client:~# s3cmd get s3://my-bucket/hosts /tmp/ download: 's3://my-bucket/hosts' -> '/tmp/hosts' [1 of 1] 186 of 186 100% in 0s 3.71 kB/s done # 显示my-bucket中的文件 root@client:~# s3cmd ls s3://my-bucket 2021-08-30 16:43 186 s3://my-bucket/hosts # 删除my-bucket中的hosts文件 root@client:~# s3cmd del s3://my-bucket/hosts delete: 's3://my-bucket/hosts' root@client:~# s3cmd ls s3://my-bucket root@client:~# # 删除my-bucket root@client:~# s3cmd rb s3://my-bucket Bucket 's3://my-bucket/' removed root@client:~# s3cmd ls root@client:~# #注意:修改bucket存储的信息,就是重新上传修改后的信息