相信很多测试小伙伴儿都听过或者使用过web自动化selenium,那您有没有研究过selenium的原理呢?为什么要使用webdriver.exe,webdriver.exe是干啥用的?selenium.common.exceptions.WebDriverException: Message: 'xxxdriver' executable needs to be in PATH如何解决的 ?今天和大家一起分析下selenium整体运行原理,有一个直观的认识。
以python为例
此处省略环境搭建和安装过程了,不知道的小伙伴儿可以自行百度。
大家都知道在使用selenium时,需要先要导入webdriver,通过webriver模块实例化driver对象
from selenium import webdriver chrome = webdriver.Chrome()
webdriver.Chrome()都做了什么?
通过跟踪Chrome类的__init__方法发现,在初始化时调用了Service类的start方法
# WebDriver初始化方法,executable_path为chromedriver def __init__(self, executable_path="chromedriver", port=0, options=None, service_args=None, desired_capabilities=None, service_log_path=None, chrome_options=None, keep_alive=True) # Service类初始化和调用start方法 from .service import Service self.service = Service( executable_path, port=port, service_args=service_args, log_path=service_log_path) self.service.start()
继续跟踪Service类中start方法
cmd = [self.path] cmd.extend(self.command_line_args()) self.process = subprocess.Popen(cmd, env=self.env, close_fds=platform.system() != 'Windows', stdout=self.log_file, stderr=self.log_file, stdin=PIPE)
cmd列表的第一个参数是传入的executable_path="chromedriver"
cmd列表的第二个参数是可用的端口号
# class Service(object)中的方法,说明该方法需要子类重写 def command_line_args(self): raise NotImplemented("This method needs to be implemented in a sub class") # 子类class Service(service.Service) def command_line_args(self): return ["--port=%d" % self.port] + self.service_args # self.port 属性在子类Service未声明,说明是在父类中声明的 # 父类中的__init__方法中 self.port = port if self.port == 0: self.port = utils.free_port() # 由此可知port是调用utils.free_port获取一个可用端口,这就是为什么每次运行端口都不一样的原因所在
从上面分析可以得到cmd的参数为
cmd = ['chromedriver', '--port=52857']
端口是随机可用的
即start方法实际是使用subprocess中的Popen方法执行cmd中的命令chromedriver --port=52857
我们在dos窗口中执行该命令

貌似是起了一个服务,在浏览器输入 localhost:52857试试

可以访问,那关掉该cmd窗口再进行访问呢?
无法访问了,可以看出subprocess.Popen(cmd)实际是启动了一个服务,那cmd命令中chromewebdrive是什么呢?
通过命令where chromewebdriver,发现 chromewebdriver就是我们添加到path路径的浏览器驱动

双击运行chromewebdriver.exe 发现,和subprocess.Popen(cmd)是惊人的相似,只是端口不同而已,也是可以通过浏览器访问

再执行完subprocess.Popen(cmd),紧接着执行RemoteWebDriver的初始化方法,代码如下:
# RemoteWebDriver类的初始化方法 RemoteWebDriver.__init__( self, command_executor=ChromeRemoteConnection( remote_server_addr=self.service.service_url, keep_alive=keep_alive), desired_capabilities=desired_capabilities)
通过对代码进行跟踪,RemoteWebDriver.__init__实际就是通过http的形式向webdriverserver获取一个session
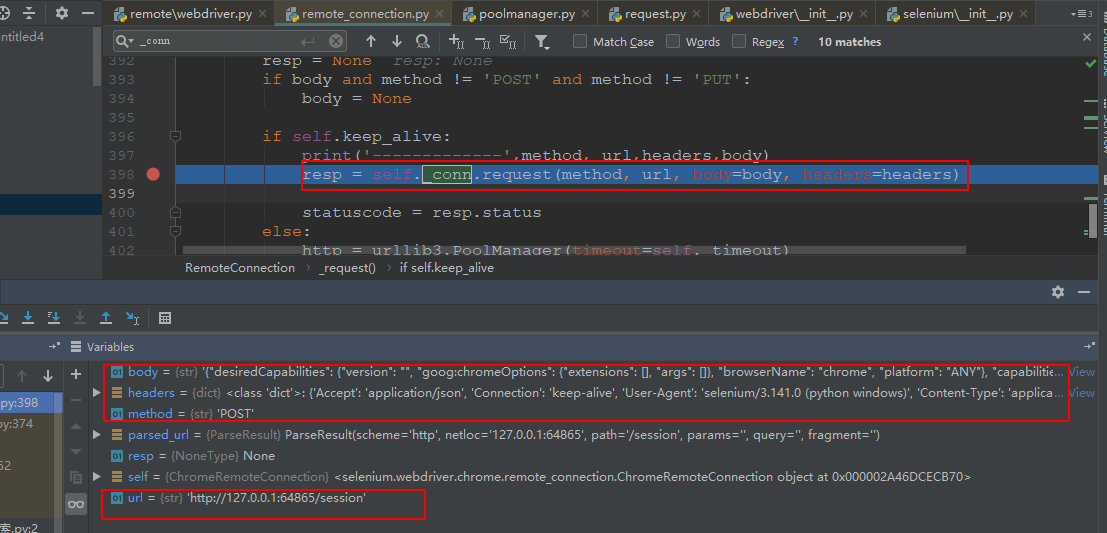
综上webdriver.Chrome()其实就是启动了一个本地服务,并通过http获取一个新的session
接下来继续分析chrome.get('http://www.baidu.com')都做什么?
def get(self, url): """ Loads a web page in the current browser session. """ self.execute(Command.GET, {'url': url}) # 都是调用的 self._request发起http请求 def execute(self, command, params): return self._request(command_info[0], url, body=data)
通过print或者debug,get方法本质也是向webdriver server 发起一次http请求,session/${session}/url
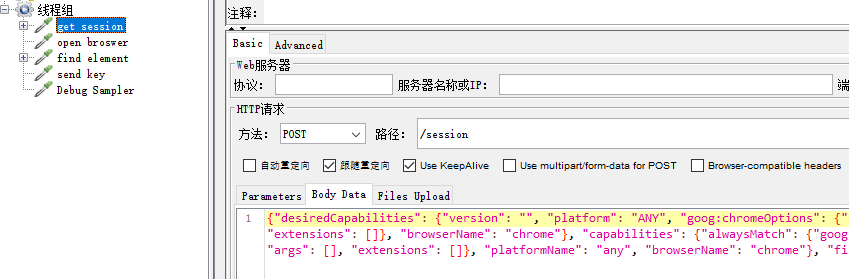
为了验证上说结论我们用接口的形式是否可以打开chrome浏览器
步骤:
1、本地双击webdriver.exe 启动一个一个webdriver 服务,端口9515
2、通过接口localhost:9515/session, 获取session
3、通过接口localhost:9515/session/${session}/url,打开浏览器
接口1
localhost:9515/session method: POST params: {"desiredCapabilities": {"version": "", "platform": "ANY", "goog:chromeOptions": {"args": [], "extensions": []}, "browserName": "chrome"}, "capabilities": {"alwaysMatch": {"goog:chromeOptions": {"args": [], "extensions": []}, "platformName": "any", "browserName": "chrome"}, "firstMatch": [{}]}}
接口2
session/${session}/url
method: POST
params: { "url": "http://www.baidu.com", "sessionId": "${session}" }
在jmeter中运行上述接口,启动了Chrome浏览器比打开百度首页
综上可以得出selenium的整个交互过程了,下面就是selenium的运行原理,写得不对的欢迎板砖

思考:
selenium web UI自动化能否可以向接口自动化那些来编写web UI自动化呢?这样有什么好处和不足