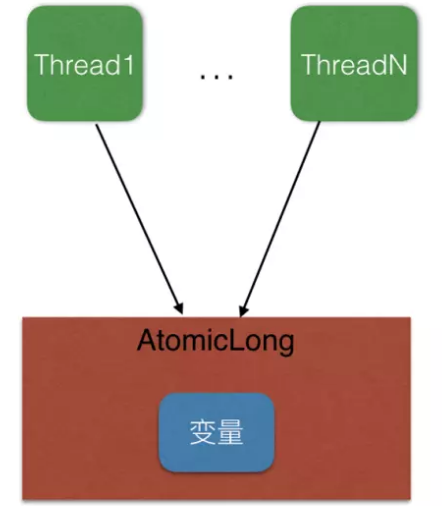
AtomicLong是作用是对长整形进行原子操作,显而易见,在java1.8中新加入了一个新的原子类LongAdder,该类也可以保证Long类型操作的原子性,相对于AtomicLong,LongAdder有着更高的性能和更好的表现,可以完全替代AtomicLong的来进行原子操作。
AtomicLong的代码很简单,下面仅以incrementAndGet()为例,对AtomicLong的原理进行说明。
incrementAndGet()源码如下:
public final long incrementAndGet() { for (;;) { // 获取AtomicLong当前对应的long值 long current = get(); // 将current加1 long next = current + 1; // 通过CAS函数,更新current的值 if (compareAndSet(current, next)) return next; } } // value是AtomicLong对应的long值 private volatile long value; // 返回AtomicLong对应的long值 public final long get() { return value; } public final boolean compareAndSet(long expect, long update) { return unsafe.compareAndSwapLong(this, valueOffset, expect, update); } compareAndSet()的作用是更新AtomicLong对应的long值。它会比较AtomicLong的原始值是否与expect相等,若相等的话,则设置AtomicLong的值为update。
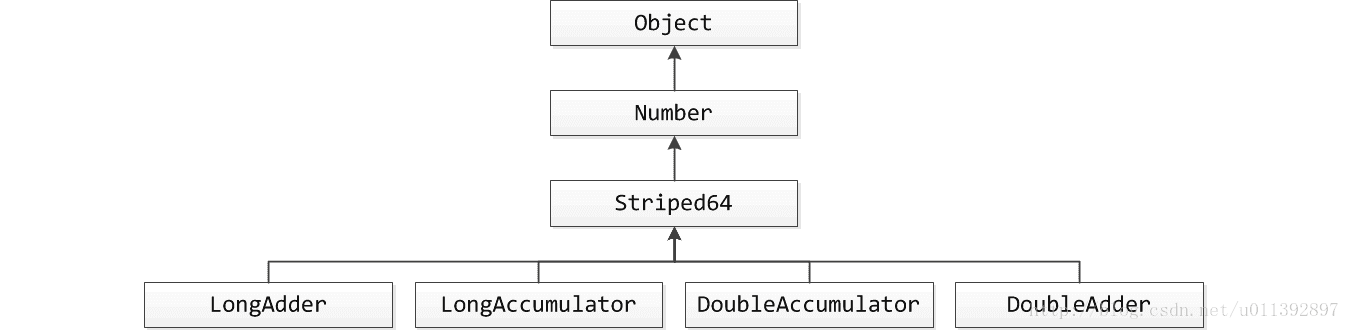
比AtomicLong更高效的LongAdder
AtomicLong的实现方式是内部有个value 变量,当多线程并发自增,自减时,均通过cas 指令从机器指令级别操作保证并发的原子性。
AtomicLong的实现方式是内部有个value 变量,当多线程并发自增,自减时,均通过CAS 指令从机器指令级别操作保证并发的原子性。
LongAdder是jdk8新增的用于并发环境的计数器,目的是为了在高并发情况下,代替AtomicLong/AtomicInt,成为一个用于高并发情况下的高效的通用计数器。
高并发下计数,一般最先想到的应该是AtomicLong/AtomicInt,AtmoicXXX使用硬件级别的指令 CAS 来更新计数器的值,这样可以避免加锁,机器直接支持的指令,效率也很高。但是AtomicXXX中的 CAS 操作在出现线程竞争时,失败的线程会白白地循环一次,在并发很大的情况下,因为每次CAS都只有一个线程能成功,竞争失败的线程会非常多。失败次数越多,循环次数就越多,很多线程的CAS操作越来越接近 自旋锁(spin lock)。计数操作本来是一个很简单的操作,实际需要耗费的cpu时间应该是越少越好,AtomicXXX在高并发计数时,大量的cpu时间都浪费会在 自旋 上了,这很浪费,也降低了实际的计数效率。
// jdk1.8的AtomicLong的实现代码,这段代码在sun.misc.Unsafe中 // 当线程竞争很激烈时,while判断条件中的CAS会连续多次返回false,这样就会造成无用的循环,循环中读取volatile变量的开销本来就是比较高的 // 因为这样,在高并发时,AtomicXXX并不是那么理想的计数方式 public final long getAndAddLong(Object o, long offset, long delta) { long v; do { v = getLongVolatile(o, offset); } while (!compareAndSwapLong(o, offset, v, v + delta)); return v; }
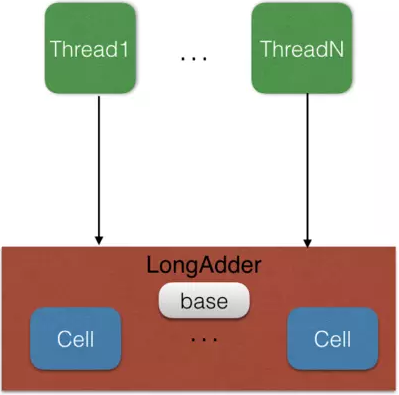
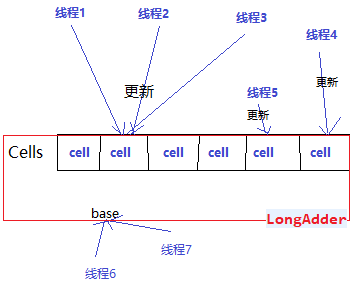
说LongAdder比在高并发时比AtomicLong更高效,这么说有什么依据呢?LongAdder是根据ConcurrentHashMap这类为并发设计的类的基本原理——锁分段,来实现的,它里面维护一组按需分配的计数单元,并发计数时,不同的线程可以在不同的计数单元上进行计数,这样减少了线程竞争,提高了并发效率。本质上是用空间换时间的思想,不过在实际高并发情况中消耗的空间可以忽略不计。
现在,在处理高并发计数时,应该优先使用LongAdder,而不是继续使用AtomicLong。当然,线程竞争很低的情况下进行计数,使用Atomic还是更简单更直接,并且效率稍微高一些。
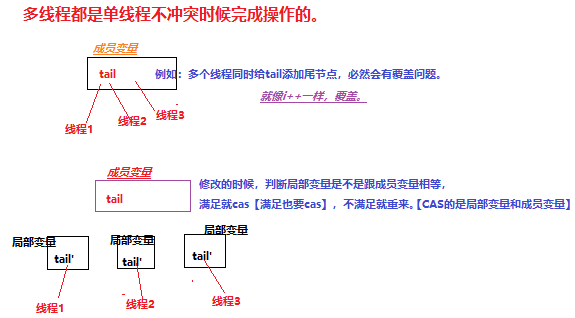
既要看单线程的执行结果,还要看多线程对他的影响。
每次操作时候都要看局部变量是不是等于成员变量(判断是否没有别的线程干扰),最后再把局部变量赋值给成员变量完成修改。成员变量的修改都是CAS。



@SuppressWarnings("serial")
abstract class Striped641 extends Number1 {
static final int NCPU = Runtime.getRuntime().availableProcessors();
transient volatile Cell[] cells;// cell数组,长度一样要是2^n,可以类比为jdk1.7的ConcurrentHashMap中的segments数组
// 累积器的基本值 ,没有遇到并发的情况,直接使用base,速度更快;
transient volatile long base;//cas更新
// 自旋标识,在对cells进行初始化,或者后续扩容时,需要通过CAS操作把此标识设置为1(busy,忙标识,相当于加锁), 取消busy时可以直接使用cellsBusy = 0,相当于释放锁
transient volatile int cellsBusy;//旋转锁
Striped641() {
}
final boolean casBase(long cmp, long val) {//原子更新base
return UNSAFE.compareAndSwapLong(this, BASE, cmp, val);
}
// 使用CAS将cells自旋标识更新为1,更新为0时可以不用CAS(赋值为0肯定是只有一个线程在赋值为0),直接使用cellsBusy就行
final boolean casCellsBusy() {//原子更新cellsBusy从0到1,以获取锁。
return UNSAFE.compareAndSwapInt(this, CELLSBUSY, 0, 1);
}
// 下面这两个方法是ThreadLocalRandom中的方法,不过因为包访问关系,这里又重新写一遍
// probe翻译过来是探测/探测器/探针这些,不好理解,它是ThreadLocalRandom里面的一个属性,
// 不过并不影响对Striped64的理解,这里可以把它理解为线程本身的hash值
static final int getProbe() {
return UNSAFE.getInt(Thread.currentThread(), PROBE);
}
// 相当于rehash,重新算一遍线程的hash值
static final int advanceProbe(int probe) {
probe ^= probe << 13; // xorshift
probe ^= probe >>> 17;
probe ^= probe << 5;
UNSAFE.putInt(Thread.currentThread(), PROBE, probe);//CAS设置当前线程的threadLocalRandomProbe
return probe;
}
//x:要增加的数。fn:执行函数。uncontended=false表示更新失败了,=true表示没有这个线程的Cell(不可能是更新成功了,更新成功就进不来这里)。
final void longAccumulate(long x, LongBinaryOperator fn, boolean wasUncontended) {//开始分段更新:1.base更新失败。2.前面分段更新不行或失败。
//新建,更新,扩容,初始化,更新base。
int h;//线程hash值
// 看下ThreadLocalRandom是否初始化。如果当前线程的threadLocalRandomProbe为0,说明当前线程是第一次进入该方法,
if ((h = getProbe()) == 0) {// 当前线程hash值=0,
ThreadLocalRandom.current(); //初始化当前线程的PROBE值不为0,
h = getProbe();
wasUncontended = true;//下面的cas语句走不走,还是间隔一个for循环在cas uncontended=false代表存在争用,uncontended=true代表不存在争用。
}
boolean collide = false; //下面的扩容语句走不走,还是间隔一个for循环在扩容 。collide=true代表cas有冲突,collide=false代表cas无冲突
for (;;) {
Cell[] as;//局部变量,线程执行时候,局部变量不会变,成员变量会改变(修改属性地址不变,重新new地址才改变)。as一进来就赋值后面没有更改过。
Cell a;//线程对应的cell,a一进来就赋值后面没有更改过。
//cellsBusy没有局部变量,直接使用成员变量。是一个锁。
int n;
long v;
//------------------------------------------重要---多线程时候,在一个线程的周期里面,前一个指令的判断(被另一个线程修改)现在不一定成立了-----------------------------------------------------//
/*每次执行真正操作时候,有可能刚才判断的条件全部不成立了,就要重来,那么刚才判断条件有什么用:不冲突有用。
执行成功时候:在锁住期间,刚才进来的判断都成立,近似于单线程操作,或者别的操作了,但是不影响现在要操作的条件。*/
/*多线程同时判断3个if,有可能一个线程判断第一个if不成立,但是判断第二个if时候,第一个if条件又成立了。走到后面的判断,只能说刚才前面的判断不成立,现在前面的判断不一定不成立了。
所以进入一个if:要看2个判断,之前判断是什么,现在判断是什么,才进入这个if条件 */
/*casCellsBusy()用于锁住这个cells,别的线程不能扩容和初始化和新建cell(但是可以cas更新存在的cell)。但是casCellsBusy()前后的条件不一定再次成立了,所以锁住之后要再次判断刚才的条件
,多线程时候上一次的判断现在不一定成立了。*/
/*局部变量,线程执行时候,局部变量不会变,成员变量会改变(修改属性地址不变,重新new地址才改变)。as一进来就赋值后面没有更改过。*/
/*在一个线程里面:1.已经有cells,要么新建(新建时候看是不是空),要么更新(要看是不是原值),要么扩容(要看cells有没有变化)。2.没有cells就去初始化(初始话时候再看是不是空)。3.初始化抢不赢就去更新base。*/
//------------------------------------------重要-----多线程时候,在一个线程的判断周期里面,前一个指令的判断(被另一个线程修改)现在不一定成立了---------------------------------------------------//
//as == cells,只有初始化和扩容(因为重新new)才不相等,修改值还是相等的。
//每次重新来,都会重新获取as和a,as = cells,a = as[(n - 1) & h],并且更新线程hash。
// 1.已经有分段更新了cells!=null
if ((as = cells) != null && (n = as.length) > 0) {
//1.1 没有这个线程的Cell,新建
//重新来:1.新建cell时候有人占用cell。2.新建cell时候位置不为空。
if ((a = as[(n - 1) & h]) == null) {
if (cellsBusy == 0) { // cellsBusy=1表示有人在修改Cells数组(修改Cell从null到new Cell,扩容,初始化),CAS更新一个已经存在的Cell不用判断cellsBusy。
Cell r = new Cell(x); //这期间其他线程可以做很多事
if (cellsBusy == 0 && casCellsBusy()) {// cellsBusy是0就进来,然后变成cellsBusy=1,别的进不来。
//不可能多个线程同时进这里面来。
/*锁住cells,但是前面判断a=null,现在不一定a=null了,因为在前面判断到锁住cells期间cells有可能改变了,并且cellsBusy从0变到1又变到0。所以锁住之后在判断是不是空。*/
/*每次执行真正操作时候,有可能刚才判断的条件全部不成立了,就要重来,那么刚才判断条件有什么用:不冲突有用。
执行成功时候:在锁住期间,刚才进来的判断都成立,近似于单线程操作,或者别的操作了,但是不影响现在要操作的条件。*/
boolean created = false;
try {
Cell[] rs;
int m, j;
// 再次判断没有这个cell, 前面if判断了是空,走到这里时候有可能别人放进去了并且cellsBusy从0变到1再变到0了。如果不是null了,就不放,下次再来(直接更新)。
if ((rs = cells) != null && (m = rs.length) > 0 && rs[j = (m - 1) & h] == null) {
rs[j] = r;// 赋值
created = true;// 创建完成,退出,不用重新来了。
}
} finally {
cellsBusy = 0;//释放锁
}
if (created)// 创建完成,退出
break;
continue; // 这个线程没有成功创建,肯定重头再来
}
}
collide = false;// cell不存在,但是有人修改cells,collide = false,
}
//1.2有这个线程的cell
//wasUncontended=false重新来
else if (!wasUncontended) // wasUncontended=false表示更新失败了,再来,wasUncontended=true下次不进这里直接去cas更新,否则先不cas先再来一次。
wasUncontended = true;
// 1.3有这个线程的cell
//wasUncontended=true,更新失败了重新来。
else if (a.cas(v = a.value, ((fn == null) ? v + x : fn.applyAsLong(v, x))))//这个线程有Cell,去更新。
break;// 更新成功,退出。
// 1.4有这个线程的cell
//wasUncontended=true,更新失败,cells初始化扩容了,重新来
else if (n >= NCPU || cells != as) // CPU能够并行的CAS操作的最大数量是它的核心数 ,cells被改变了(扩容了肯定重新来)。
collide = false;
// 1.5有这个线程的cell
//wasUncontended=true,更新失败,cells没有初始化扩容,collide=false,重新来
else if (!collide) //=false走这里,collide=true,下次不走这里直接去扩容否则先不去扩容先再来一次。
collide = true;
// 1.6有这个线程的cell
//wasUncontended=true,更新失败,cells没有初始化扩容,collide=true,占用cells,扩容完成,重新来
//有这个线程的cell,cas失败,说明2个线程同时更新这个cell,就扩容。既然你不让我加,竞争这么厉害,那么扩容试试看。
else if (cellsBusy == 0 && /* 这期间其他线程可以做很多事 */casCellsBusy()) {
//不可能多个线程同时进这里面来。
try {
if (cells == as) { //锁住cells了,最开始as = cells,但是现在as不一定=cells,所以判断cells没变扩容,
Cell[] rs = new Cell[n << 1];// 执行2倍扩容
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;// 释放锁
}
collide = false;// 扩容意向为false
continue; // 扩容后还没有设置值(肯定重新来)
}
//1.7 有这个线程的cell
h = advanceProbe(h);// 修改当前线程的hash,降低hash冲突(线程hash改变是无所谓的,关注的是里面的值,与哪个线程放进去无关),避免下次还映射到这个cell。
}
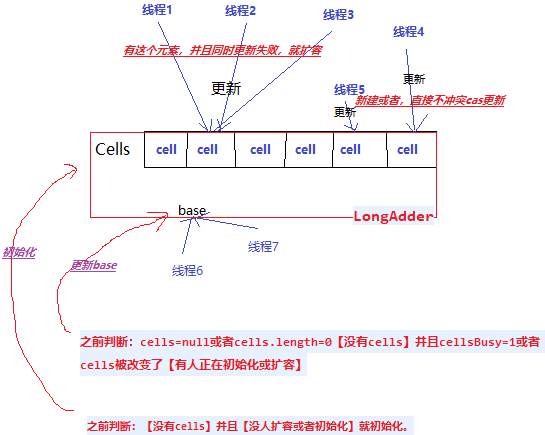
// 2。某个线程执行时候,前一个if判断:没有分段更新,cells==null或者cells.length=0。走到这里时候cells有可能不为空了,但是要进入这if必须:cellsBusy=0,
//同时cells还是刚才那个as=null(没有扩容和初始化)并且casCellsBusy()抢成功,就去初始化。
//线程执行到这里:之前判断:【没有cells】,并且现在【没人扩容或者初始化,并且cells为空】就初始化。
else if (cellsBusy == 0 && cells == as && /*这期间其他线程可以做很多事*/casCellsBusy()) {// cellsBusy=1,别的线程就不能动cells
//不可能多个线程同时进这里面来。
boolean init = false;
try {
if (cells == as) { //锁住cells了,但是cells不一定=as=空或者null了, 锁住之后一定要再检测一次,如果还是null就初始化
Cell[] rs = new Cell[2];// 初始化时只创建两个单元
rs[h & 1] = new Cell(x);// 对其中一个单元进行累积操作,另一个不管,继续为null
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;// 释放锁
}
if (init)// 初始化成功退出,初始化失败继续来
break;
}
// 3。走到这里:前面判断不成立(不代表现在的前面判断也不成立),之前判断:cells=null或者cells.length=0【没有cells】并且cellsBusy=1或者 cells被改变了【有人正在初始化或扩容】或者casCellsBusy()失败。
//有了分段更新,还是可以用base,提高效率。准备去扩容的,但是现在有可能别人已经扩容了(cells != as)或者casCellsBusy()失败(抢着去扩容没有抢成功)
else if (casBase(v = base, ((fn == null) ? v + x : fn.applyAsLong(v, x))))
break; // 更新base,成功就退出。
}
/*如果Cells表为空,尝试获取锁之后初始化表(初始大小为2);
如果Cells表非空,对应的Cell为空,自旋锁未被占用,尝试获取锁,添加新的Cell;
如果Cells表非空,找到线程对应的Cell,尝试通过CAS更新该值;
如果Cells表非空,线程对应的Cell CAS更新失败,说明存在竞争,尝试获取自旋锁之后扩容,将cells数组扩大,降低每个cell的并发量后再试*/
}
// double更long的逻辑基本上是一样的
final void doubleAccumulate(double x, DoubleBinaryOperator fn, boolean wasUncontended) {
int h;
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current(); // force initialization
h = getProbe();
wasUncontended = true;
}
boolean collide = false; // True if last slot nonempty
for (;;) {
Cell[] as;
Cell a;
int n;
long v;
if ((as = cells) != null && (n = as.length) > 0) {
if ((a = as[(n - 1) & h]) == null) {
if (cellsBusy == 0) { // Try to attach new Cell
Cell r = new Cell(Double.doubleToRawLongBits(x));
if (cellsBusy == 0 && casCellsBusy()) {
boolean created = false;
try { // Recheck under lock
Cell[] rs;
int m, j;
if ((rs = cells) != null && (m = rs.length) > 0 && rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
if (created)
break;
continue; // Slot is now non-empty
}
}
collide = false;
} else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
else if (a.cas(v = a.value, ((fn == null) ? Double.doubleToRawLongBits(Double.longBitsToDouble(v) + x)
: Double.doubleToRawLongBits(fn.applyAsDouble(Double.longBitsToDouble(v), x)))))
break;
else if (n >= NCPU || cells != as)
collide = false; // At max size or stale
else if (!collide)
collide = true;
else if (cellsBusy == 0 && casCellsBusy()) {
try {
if (cells == as) { // Expand table unless stale
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
h = advanceProbe(h);
} else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try { // Initialize table
if (cells == as) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(Double.doubleToRawLongBits(x));
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
} else if (casBase(v = base, ((fn == null) ? Double.doubleToRawLongBits(Double.longBitsToDouble(v) + x)
: Double.doubleToRawLongBits(fn.applyAsDouble(Double.longBitsToDouble(v), x)))))
break; // Fall back on using base
}
}
private static final sun.misc.Unsafe UNSAFE;
private static final long BASE;
private static final long CELLSBUSY;
private static final long PROBE;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> sk = Striped641.class;
BASE = UNSAFE.objectFieldOffset(sk.getDeclaredField("base"));
CELLSBUSY = UNSAFE.objectFieldOffset(sk.getDeclaredField("cellsBusy"));
Class<?> tk = Thread.class;
PROBE = UNSAFE.objectFieldOffset(tk.getDeclaredField("threadLocalRandomProbe"));
} catch (Exception e) {
throw new Error(e);
}
}
// 一个Cell里面一个value,可以看成是一个简化的AtomicLong,通过cas操作来更新value的值
// @sun.misc.Contended是一个高端的注解,代表使用缓存行填来避免伪共享
@sun.misc.Contended
static final class Cell {
volatile long value;// cas更新其值
Cell(long x) {
value = x;
}
final boolean cas(long cmp, long val) {// cas更新
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);
}
private static final sun.misc.Unsafe UNSAFE;
private static final long valueOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> ak = Cell.class;
valueOffset = UNSAFE.objectFieldOffset(ak.getDeclaredField("value"));
} catch (Exception e) {
throw new Error(e);
}
}
}
}
public class LongAdder1 extends Striped641 implements Serializable { private static final long serialVersionUID = 7249069246863182397L; public LongAdder1() { } /*看到这里我想应该有很多人明白为什么LongAdder会比AtomicLong更高效了, 没错,唯一会制约AtomicLong高效的原因是高并发,高并发意味着CAS的失败几率更高, 重试次数更多,越多线程重试,CAS失败几率又越高,变成恶性循环,AtomicLong效率降低。 那怎么解决?** LongAdder给了我们一个非常容易想到的解决方案:减少并发,将单一value的更新压力分担到多个value中去 (每个线程更新value数组里面的自己value【多个线程访问的同一个数组(也只有一个数组)但是cas更新的是只是其中一个value】 【因为数组有限,所以不同的线程也会出现同时cas更新一个value的情况】【会出现:多个线程同时访问这个数组的同一个cell】, 不再是多个线程更新同一个value导致cas经常失败), 降低单个value的 “热度”,分段更新 */ /*这样,线程数再多也会分担到多个value上去更新,只需要增加value就可以降低 value的 “热度” AtomicLong中的 恶性循环不就解决了吗? cells 就是这个 “段” cell中的value 就是存放更新值的, 这样,当我需要总数时,把cells 中的value都累加一下不就可以了么!!*/ /*当然,聪明之处远远不仅仅这里,在看看add方法中的代码,casBase方法可不可以不要,直接分段更新,上来就计算 索引位置,然后更新value? 答案是不好,不是不行,因为,casBase操作等价于AtomicLong中的CAS操作,要知道,LongAdder这样的处理方式是有坏处的, 分段操作必然带来空间上的浪费,可以空间换时间,但是,能不换就不换,看空间时间都节约~! 所以,casBase操作保证了在低并发时,不会立即进入分支做分段更新操作,因为低并发时, casBase操作基本都会成功,只有并发高到一定程度了,才会进入分支, 所以,Doug Lea对该类的说明是:** 低并发时LongAdder和AtomicLong性能差不多,高并发时LongAdder更高效!***/ /*因为低并发时候,使用的是base的原子更新,没有启用分段更新(cells=null,并且casBase成功),高并发才启用分段更新。*/ /*如此,longAccumulate中做了什么事,也基本略知一二了,因为cell中的value都更新失败(说明该索引到这个cell的线程也很多 ,并发也很高时) 或者cells数组为空时才会调用longAccumulate,*/ // +x,并发计数器LongAdder加X。要么在base+x更新要么在Cell[]数组里面找到对应的Cell+x更新。 public void add(long x) {//base和cells只有一个,并且是LongAdder的属性。 Cell[] as; long b, v; int m; Cell a; //cells!=null不用判断后面进去(表明已经启用了分段更新),cells=null并且base的cas更新失败进去(表示没有启用分段更新但是高并发了, //需要启用分段更新),cells=null并且base的cas更新成功就退出(没有启用分段更新,并且不是高并发,此时跟AotomicLong是一样的)。 //并发时候更新失败,AtomicLong的处理方式是死循环尝试更新,直到成功才返回,而LongAdder则是进入这个分支。 if ((as = cells) != null || !casBase(b = base, b + x)/*cas把base的值从b变成b+x*/) { //进来:1.已经启用分段更新了。2.没有启用分段更新但是cas失败了表示高并发了。否则:没有启用分段更新并且不是高并发,就不进来。 boolean uncontended = true; if (as == null //cells=null进去,没有启用分段更新(进来了)表示高并发了。 || (m = as.length - 1) < 0 //cells.length<=0,没有启用分段更新(进来了)表示高并发了。 || (a = as[getProbe() & m]) == null //对as的长度取余,从as中获取这个线程对应的a Cell。=null表示还没有这个线程对应的cell, || !(uncontended = a.cas(v = a.value, v + x))) //a这个Cell里面的value增加x失败, 更新成功就不会进下面了。 //1.cells=null。2.cells!=null但没有这个线程的Cell。2.有这个线程的Cell但是更新失败了。 longAccumulate(x, null, uncontended); //uncontended=false表示更新失败了,=true表示没有这个线程的Cell(不可能是更新成功了,更新成功就进不来这里)。 } } public void increment() { add(1L); } public void decrement() { add(-1L); } //将多个cell数组中的值加起来的和就类似于AtomicLong中的value // 此返回值可能不是绝对准确的,因为调用这个方法时还有其他线程可能正在进行计数累加, // 方法的返回时刻和调用时刻不是同一个点,在有并发的情况下,这个值只是近似准确的计数值 // 高并发时,除非全局加锁,否则得不到程序运行中某个时刻绝对准确的值,但是全局加锁在高并发情况下是下下策 // 在很多的并发场景中,计数操作并不是核心,这种情况下允许计数器的值出现一点偏差,此时可以使用LongAdder // 在必须依赖准确计数值的场景中,应该自己处理而不是使用通用的类。 public long sum() { Cell[] as = cells; Cell a; long sum = base; if (as != null) { for (int i = 0; i < as.length; ++i) { if ((a = as[i]) != null) sum += a.value; } } return sum; } public void reset() { Cell[] as = cells; Cell a; base = 0L; if (as != null) { for (int i = 0; i < as.length; ++i) { if ((a = as[i]) != null) a.value = 0L; } } } public long sumThenReset() { Cell[] as = cells; Cell a; long sum = base; base = 0L; if (as != null) { for (int i = 0; i < as.length; ++i) { if ((a = as[i]) != null) { sum += a.value; a.value = 0L; } } } return sum; } public String toString() { return Long.toString(sum()); } public long longValue() { return sum(); } public int intValue() { return (int) sum(); } public float floatValue() { return (float) sum(); } public double doubleValue() { return (double) sum(); } private static class SerializationProxy implements Serializable { private static final long serialVersionUID = 7249069246863182397L; private final long value;//LongAdder1的总和 SerializationProxy(LongAdder1 a) { value = a.sum(); } private Object readResolve() { LongAdder1 a = new LongAdder1(); a.base = value; return a; } } private Object writeReplace() { return new SerializationProxy(this); } private void readObject(java.io.ObjectInputStream s) throws java.io.InvalidObjectException { throw new java.io.InvalidObjectException("Proxy required"); } }
public abstract class Number1 implements java.io.Serializable { public abstract int intValue(); public abstract long longValue(); public abstract float floatValue(); public abstract double doubleValue(); /* System.out.println((byte)127);//127 System.out.println((byte)128);//-128 System.out.println((byte)129);//-127 System.out.println((byte)255);//-1 System.out.println((byte)256);//0 System.out.println((byte)257);//1 */ public byte byteValue() { return (byte) intValue(); } public short shortValue() { return (short) intValue(); } private static final long serialVersionUID = -8742448824652078965L; }