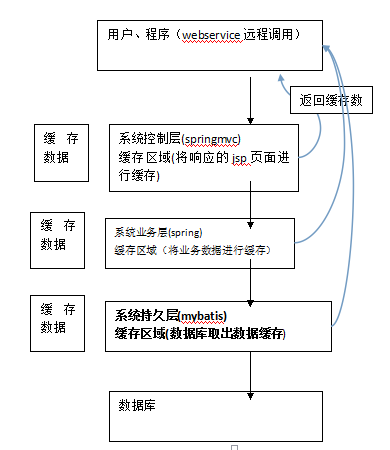
查询缓存 1.1缓存的意义 数据在磁盘会有一个IO,高并发读取效率就很低,将用户经常查询的数据放在缓存(内存)中,用户去查询数据就不用从磁盘上(关系型数据库数据文件)查询,从缓存中查询,从而提高查询效率,解决了高并发系统的性能问题。如果mysql只有600个,用缓存则不走mysql,提高了系统的性能。 springMVC、spring、mybatis都有缓存区,也就是说控制层、业务层、持久层都有缓存区,
1.1mybatis持久层缓存
mybatis提供一级缓存和二级缓存
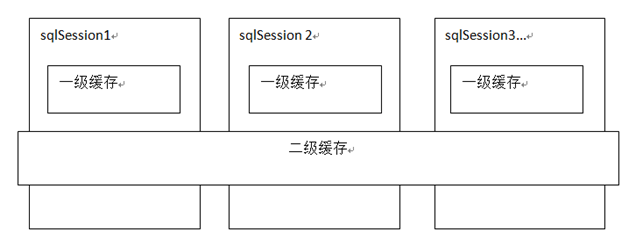
mybatis一级缓存是一个SqlSession级别,sqlsession只能访问自己的一级缓存的数据,二级缓存是跨sqlSession,是mapper级别的缓存,对于mapper级别的缓存不同的sqlsession是可以共享的。sqlSession1,sqlSession2,sqlSession3是3个对象,这3个对象都可以访问一个mapper.xml定义的selsect语句。
1.1 一级缓存原理
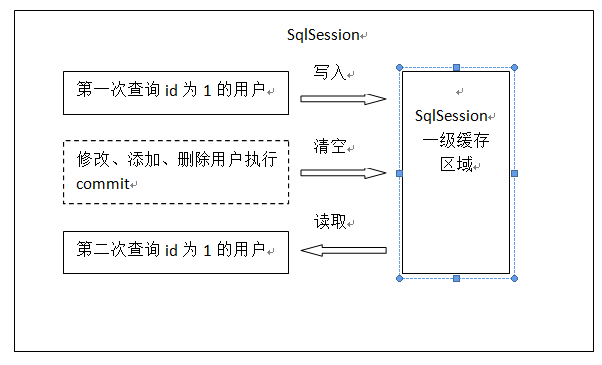
第一次发出一个查询sql(查询sql,这里指的是查询缓存),sql查询结果写入sqlsession的一级缓存中(持久层缓存 ),缓存使用的数据结构是一个map<key,value> key(sql查询的唯一标识):hashcode+sql+sql输入参数+输出参数 value:用户信息 ,同一个sqlsession再次发出相同的sql,就从缓存中取不走数据库。如果两次中间出现commit操作(修改、添加、删除),本sqlsession中的一级缓存区域全部清空,下次再去缓存中查询不到所以要从数据库查询,从数据库查询到再写入缓存。 每次查询都先从缓存中查询:源码如下:localCache是一级缓存的cache,

如果缓存中查询到则将缓存数据直接返回。
如果缓存中查询不到就从数据库查询:

1.1.1一级缓存配置 mybatis默认支持一级缓存不需要配置。 注意:mybatis和spring整合后进行mapper代理开发,不支持一级缓存,mybatis和spring整合,spring按照mapper的模板去动态生成mapper代理对象,模板中在最后统一关闭sqlsession。只要sqlsession被close了则缓存就没有了。 1.1.2一级缓存测试
测试:
public class CacheTest { // 会话工厂 private SqlSessionFactory sqlSessionFactory; // 创建工厂 @Before public void init() throws IOException { // 配置文件(SqlMapConfig.xml) String resource = "SqlMapConfig.xml"; // 加载配置文件到输入 流 InputStream inputStream = Resources.getResourceAsStream(resource); // 创建会话工厂 sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream); } //一级缓存 @Test public void testCache1() throws Exception { SqlSession sqlSession = sqlSessionFactory.openSession(); UserMapper userMapper = sqlSession.getMapper(UserMapper.class); //第一次查询用户id为1的用户 User user = userMapper.findUserById(1);//findUserById是一个接口,实现是动态代理生成的无法打断点, System.out.println(user); //中间修改用户要清空缓存(修改,删除,添加用户会清除缓存),目的防止查询出脏数据 /*user.setUsername("测试用户2"); userMapper.updateUser(user); sqlSession.commit();*/ //第二次查询用户id为1的用户 User user2 = userMapper.findUserById(1); System.out.println(user2); sqlSession.close(); }