log.dir是数据持久化到磁盘的路径。
kafka-topics --zookeeper localhost:2181 --create --topic test1
安装Docker
创建CentOS容器
安装JDK 1.7+
安装Zookeeper
启动Kafka broker
中间的kafka3个框应该是叫kafka的broker也叫kafka的server。生产者将数据发布到kafka的服务中,消费者从kafka的服务中获取数据。
Kafka里面有zookeeper。既可以在虚拟机上部署kafka也可以通过docker去部署kafka。生产者和消费者都要指定topic。
Docker安装和部署kafka的时候,首先安装Docker,然后创建centos容器,安装jdk7,安装zookper和kafka容器。
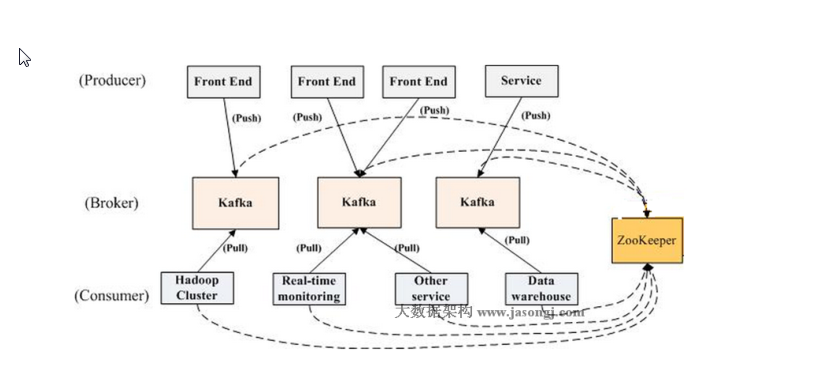
kafka架构:
生产者,消费者,Broker(接收生产者消息,给消费者订阅,收生产者发送的数据,并且将他持久化,同时提供给consume去订阅,Broker也是kafka的server,是一个服务需要单独起起来),ZooKeeper(不是kafka的一部分,只是要使用ZooKeeper)。
Broker和ZooKeeper作为后台服务,生产者,消费者作为sdk,可以通过生产者的sdk发送数据给Broker,通过消费者的sdk从Broker中拿数据。
生产者push数据推给Broker,消费者通过pull拉从Broker拿数据。为了防止消费者不能处理过多的数据,因此是消费者去取而不是Broker推过去。Broker不用知道消费者的存在。
生产者如何感知Broker的存在,生产者如何知道将一条消息发送给那个Broker,消费者如何感知有哪些Broker,从哪个Broker取数据。
生产者会如何获取整个kafka的元信息:在0.8以前生产者需要通过Zookeeper来获取整个Broker集群的信息,0.8以后在实例化一个生产者的时候可以指定多个Broker的url,比如集群有300个Broker,可以只指定3个Broker的IP和端口给消费者,生产者就可以通过这3个Broker获知整个集群的Broker信息列表,生产者会将这些元信息存在内存当中,如果有某个Broker挂了,生产者需要重新更新Broker的信息。
消费者如何获取整个Broker-kafka的元信息:实例化消费者的时候指定一个获多个zookeeper的ip和端口,因为整个集群的元信息都会存进zookeeper里面去,消费者只要连接了zookeeper就只知道整个集群有多少个topic,每个topic再哪个Broker上面。
生产者如何知道消息发送到哪个Broker上面去,消费者如何知道从哪个Broker去消费数据,这就涉及到patition和topic的概念。生产者就是通过patiton判断把消息发送给哪个Broker。
生产者发送的所有数据都要指定该消息应该被发布到哪个topic,消费者再订阅的时候也要指定订阅哪个topic的消息,消费者可以显示指定topic也可以通过黑名单白名单来指定消费和不消费哪些topic。topic是一个逻辑概念,同一个topic的消息可以分布在一个或多个节点上面,一个topic包含一个或多个partition,每条消息仅属于一个topic。
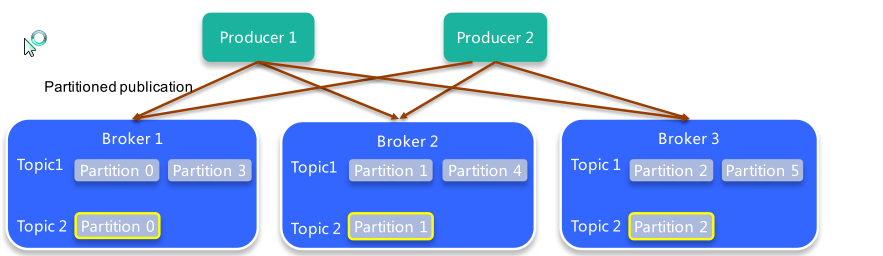
如图这个集群有3个Broker,同时有2个topic,topic1有6个patition,topic2有3个patition,每个topic具有的patition数量不一定相同。Broker会让patition均匀的分配,均匀分配才能让整个集群的负载均衡。
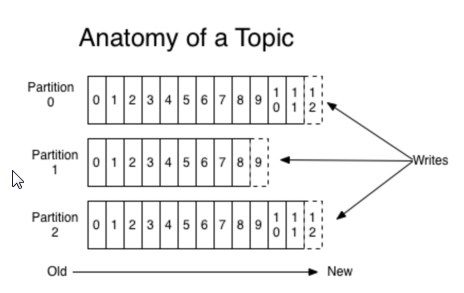
patition是一个物理概念,一个patition只分布于一个Broker上,一个patition对应一个文件夹,一个patition包含多个Segment,Segment是透明的,用户并不感知Segment的存在,一个Segment对应一个文件。kafka会将数据持久化到硬盘上,kafka会把数据保留168小时,168小时之前的数据都删掉。或者超过10G数据就删除。
如果一个topic有3和pation,在log指定的磁盘路径中看到topic1-0,topic1-1,topic1-2 3个文件夹,可以知道patition对应一个文件夹,patition里面有0000.index和0000.log文件,index文件是索引,log文件是真正的数据。inidex存每条消息的起始位置跟offset对应的关系,通过index文件找到log文件的位置。要找到一条消息,首先应该知道消息在哪个patition中并且这条消息在patition中的offset是多少。
生产者发送消息的时候要决定消息发送到哪个Broker上去,
public class HashPartitioner implements Partitioner {//patition的接口
public HashPartitioner(VerifiableProperties verifiableProperties) {}
@Override
//这个方法返回值是消息应该被发送到哪个patition,因为一个patition只在一个Broker上,这个方法就是告诉这个消息应该被发送到哪个patition或者哪个Broker上去。
public int partition(Object key, int numPartitions) {//一个参数是消息的key,二个参数是pation的总数(这条消息发送到的topic的patition的总数),
if ((key instanceof Integer)) {
return Math.abs(Integer.parseInt(key.toString())) % numPartitions;
}
return Math.abs(key.hashCode() % numPartitions);
}
}
同步生产者异步生产者。
同步生产者是向Broker发送一条消息之后发送失败就会重试发送3次,3次还是失败就会抛出异常或者加入失败队列后面再发送。
异步生产者是发送一条数据之后就把数据放入一个队列里面,有一个后台进程不停地去队列拿数据然后发送给Broker。队列满了或者阻塞超过一定时间,kafka会将新的数据丢掉。
CAP理论(帽子理论):A节点更新了,B节点要跟着更新。主节点挂了次节点要能工作。