单击返回:自学N-Compass之路
nCompass-网络流量基础知识及数据源
1. 流量分析基础知识
1.1 常见的流量分析方式:
- SNMP: 网管平台通过主动式获取设备接口流量信息。
- Flow:网络设备将穿越的数据流信息精简压缩打包。
- 日志:有些设备支持基于业务访问内容生成详细的交互信息。
- 原包:通常是交换机将穿越的数据包1:1的复制到一个新的物理端口发送至分析平台,然后分析平台进行拆解分析出指标。
SNMP :
网管平台以主动获取MIB-ID的方式读取设备接口硬件级信息,包含接口命名/速率/带宽/流入流出包数/流入流出吞吐量等。
优点: 运维人员最常用的流量分析方式,技术成熟
缺点:
- 数据精细化颗粒度较差,获取到的数值为最近5分钟平均值;
- 高频主动式获取可能会对地段设备性能消耗较大,业界内通常采用每5分钟或每1分钟读取一次;
- 分析内容极少,有效信息仅包含接口实时吞吐量,无法看到明细通讯对。
Flow(NetStream、NetFlow和sFlow)
Flow技术基于“流”提供报文统计功能,可以对网络设备的每个端口上出入方向的流量进行采样,对采样到的报文依据报文中的关键值(例如五元组等)对网络中的流量进行分类统计。
优点:轻量级
缺点:
- 采样比原因可能会导致数据准确性较差;
- 有效的分析内容较少,仅包含基本的五元组信息;
- 传输可能会消耗带宽。

日志:
优点:轻量级
缺点:
- 传输可能会占用业务带宽(有的日志内容只能从业务端口发出,不能出带外端口发出);
- 内容精细程度和各设备厂商所支持的分析程度有关。
原包(第一种:流量镜像):
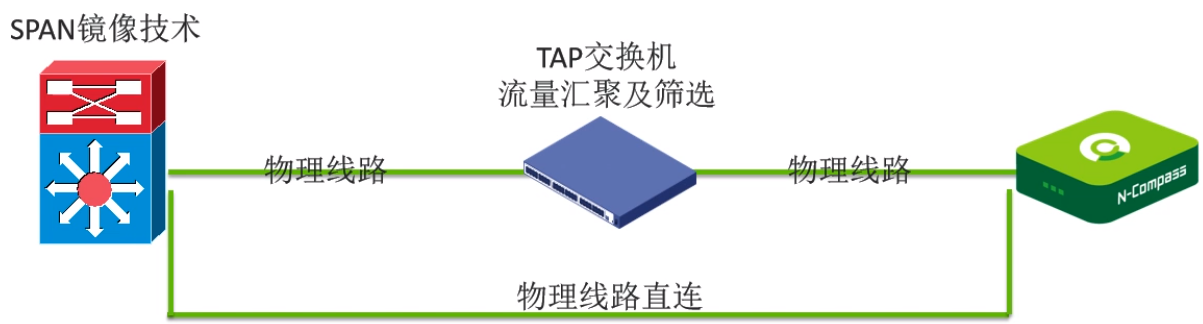
优点:
- 非入侵式旁路部署,不会对现网架构造成影响,隔离且独立的网络架构;
- 高密度镜像端口集中化管理;
- 良好的可扩展性。
缺点: 可能会对设备处理性能造成极微影响,
原包(第二种:分光器):
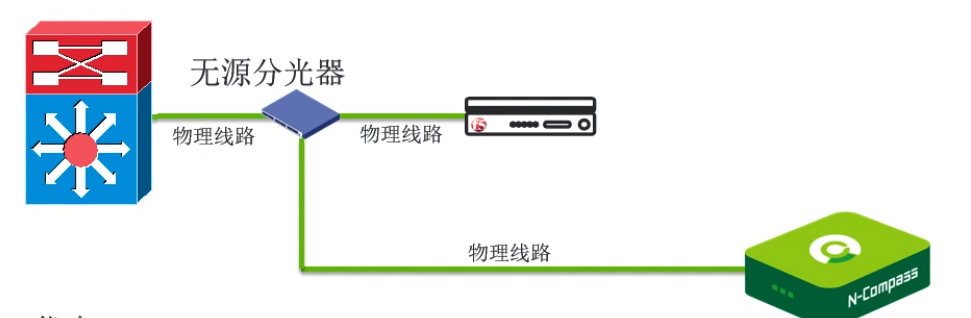
优点:
- 不会对网络设备的性能造成任何影响;
- 高密度镜像端口集中化管理;
- 良好的可扩展性;
- 分光器为无源设备,异常时会自动bypass,对业务影响几乎为零。
缺点: 初次上线分光器会中断业务。
1.2 nCompass采集口
- 电口:通用千兆电口模块。
- 光口:SFP 850nm LC多模模块,支持千/万兆。
- 注意,对端设备模块要求必须类型一致。
1.3 流量规划
- 监控节点:同一台设备的同一个物理接口才是一个监控节点。(同一台设备的不同物理接口不能当做一个监控节点。)
- 避免问题:非同一条数据流无法重组。(安全类设备随机回话序列号)
- 建议镜像方式:统一监控节点both双向镜像。
- 如何判定数据是同一监控节点? 通过一条数据流里面两个方向的数据(服务端到客户端,客户端到服务端),查看源目MAC是否是一对。
- 关键设备重点监控:例如串接的负载、WAF、代理设备、行为管理、防火墙、防水墙、防毒墙。(需分别监控交换机、入关键设备、出关键设备接口,尽可能的避免交换机异常导致故障定位分析的错误。)
1.4 监控原则
- 关键性:需监控所有4层设备(对数据包具有处理功能的设备,防火墙、负载等)前后端节点;交换机只对数据进行快速转发,通常场景下不会对数据进行处理,不监控交换机的前后端。
- 全面性:针对各关键业务系统架构特点合理部署监控节点,尽可能监控业务流上的每个关键节点。
- 准确性:交换机镜像出的流量尽可能的纯净,应避免出现单向流量或重复流量,以减轻设备性能压力。
- 唯一性:若两个监控点的流量重复,需借助TAP流量汇聚设备分别打上不同的VLAN标签或将以上两个节点的流量分配给不同的设备物理接口分析。
- 均衡性:针对各区域数据量特点合理分配设备接口及处理性能,做到压力分摊,以保证数据的准确性。例如,东西向数据交互量大、南北向IP通讯对量大等。
- 分压性:根据数据中心网络内部区域明细划分原则,大流量的不同区域尽可能使用不同的探针进行监控,以降低运维复杂度。
- 扩展性:设备的部署应考虑峰值流量以及未来一段时间内业务增长蹴球,避免输入到设备的流量
- 超出设备的实际处理能力。
1.5 nCompass的重要概念
“我的网络”:
nCompass流量分析平台是旁路设备,不像是串接的网络设备,很难去判定数据的流入/流出的方向,所以引入“我的网络”的概念。 进入“我的网络”流量为流入,离开“我的网络”流量为流出。
哪些地址段需要定义为“我的网络”:
- 公网对外提供服务地址
- 数据中心内部私有地址
- 外联第三方单位对外体用服务地址
“时间戳”:
nCompass平台会对收到的每个数据包打上nm级时间戳,准确定为100%。
不建议使用TAP设备打时间戳。
如何定义分支站点?
分支站点定义存在一个很大的误区,如何准确的定义分支站点?
网络工程师可能会对此产生误解,专线的互联地址也就是网络设备的接口地址不应该定义为站点,因为在访问的实际交互过程中,例如一台上海的终端192.21.0.1访问的目的肯定真实的业务IP,而不是网络设备的接口,原始流量中看到的源目IP也是一样。
2. nCompass数据源
2.1 数据源的几个概念
- 数据模型:nCompass平台的数据分类方式。数据模型之间可以通过共同的维度实现关联。
- 维度:是指流量分析里的分析对象,比如链路、IP、通讯对、省份、运营商、MAC、Vlan、租户、VXlan等等
- 指标:对分析对象的行为、状态、数量进行聚类、统计得到的结果。
维度和指标的区别:
- 指标随着时间变化、维度不随时间变化
- 指标有单位,维度没有单位
- 指标大多是数值,维度大多是名称
- 时间是特殊的维度
2.2 数据源的使用步骤
- 选择数据模型
- 选择维度
- 选择指标
- 过滤维度
- 筛选指标
2.3 常用的数据模型
- TCPIP:最常见的模型,包括OSI参考模型1-4层的维度:包括数量、延时、大小、成功失败等种指标。
- HTTP:专门分析HTTP协议的模型,包括域名、URL、useragent等各种维度:包括,延时、返回码的统计。
- HTTPS:专门FenixSSL握手的协议。
- Oracle、DB2、SQLserver:各种数据库模型。
- NetFlow:专门分析Flow的模型,包括netflow、Netstream、sflow等。
- ICMP模型:专门分析ICMP差错报文的模型。
- 拨测:主动拨测的模型。
2.4 数据源的使用(数据表格的方式)
数据回溯(里面有各种数据表格)
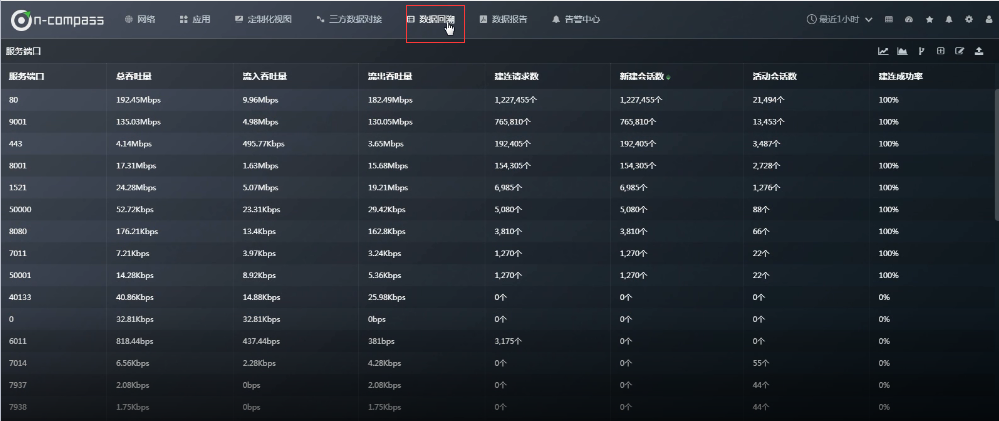
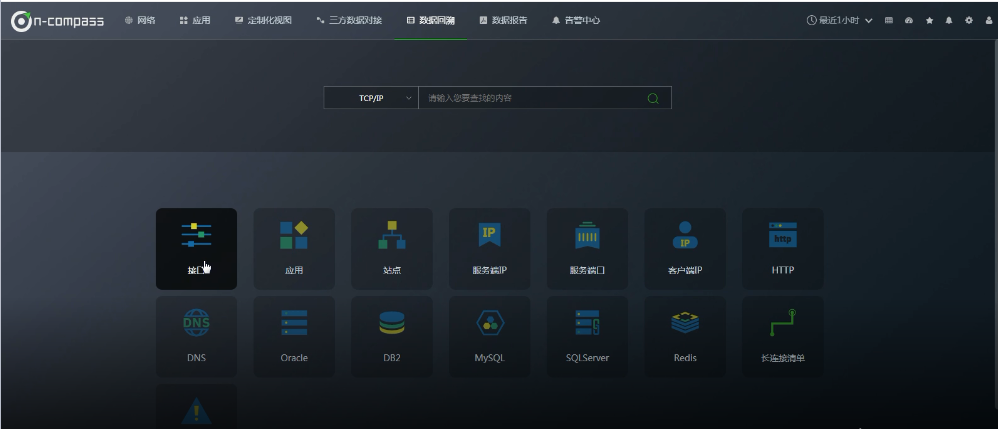
2.4.1 具体看一下“接口”数据表格:
维度:探针接口
指标: 总吞吐量、流量吞吐量、流出吞吐量、丢包率、网络时延、建连请求数、新建回话数、建连失败数。
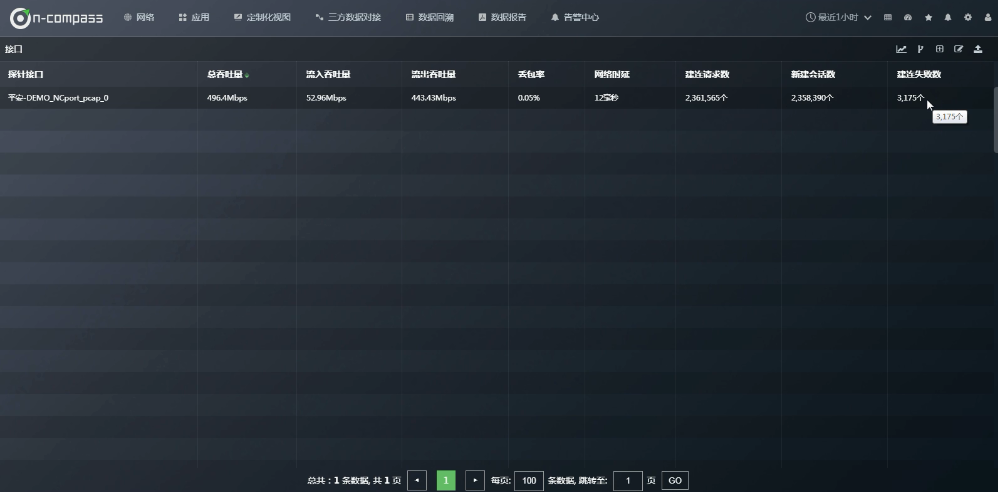
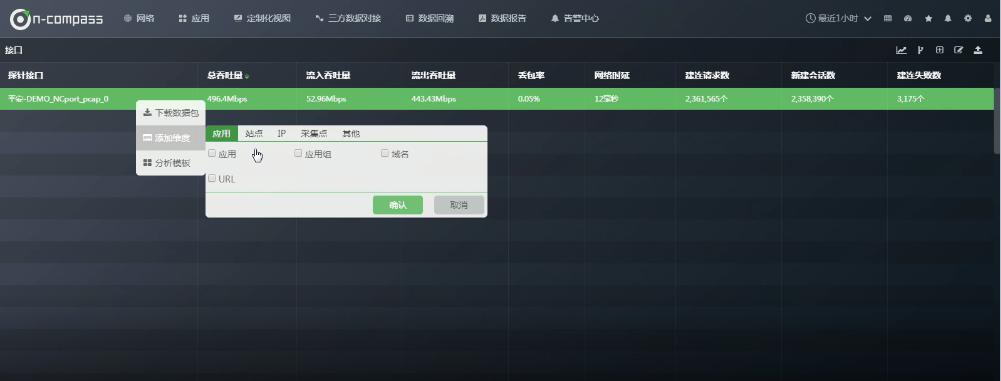
如果想知道这个接口里面各个通讯对的情况?
接口右键---“添加维度”
- 应用: 应用、应用组、域名、URL
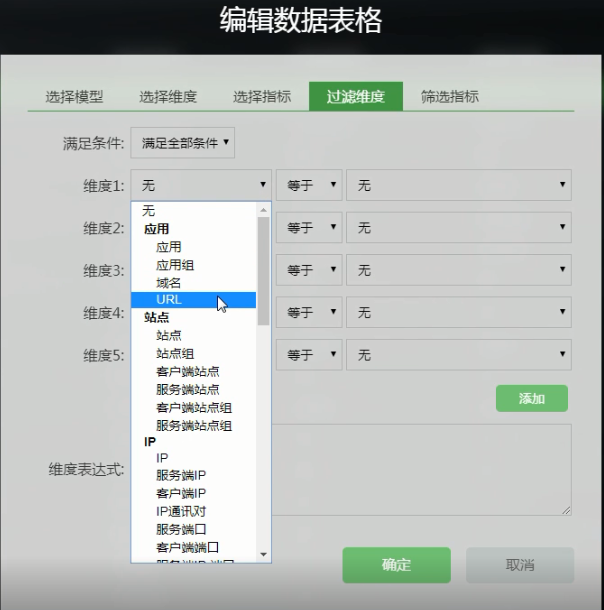
- 站点:站点、站点组、客户端站点、服务端站点、客户端站点组、服务端站点组
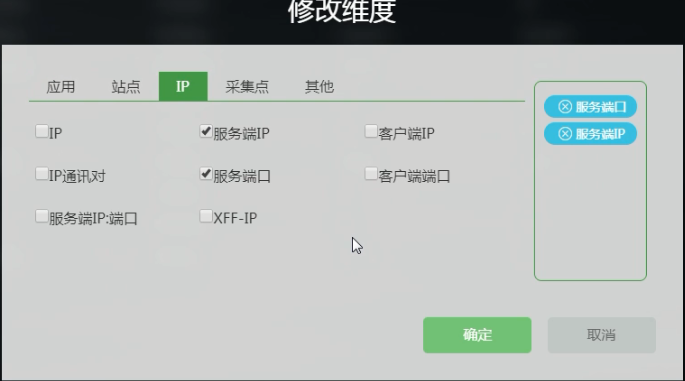
- IP:IP、服务端IP、客户端IP、IP通讯对、服务端口、客户端端口、服务端IP端口、XFF-IP
- 采集点:
- 其他:
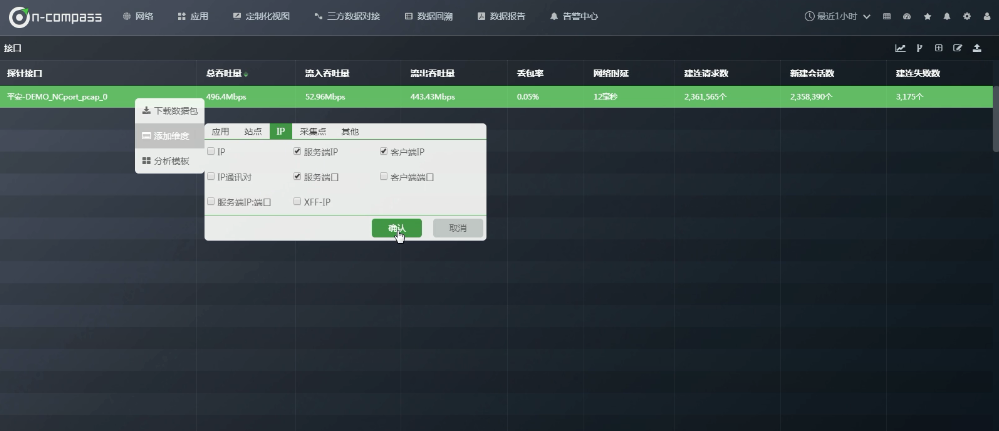
现在看一下常用的,在这个探针接口下面的 ” 服务端IP、客户端IP、服务端口” , 还可以进行排序。
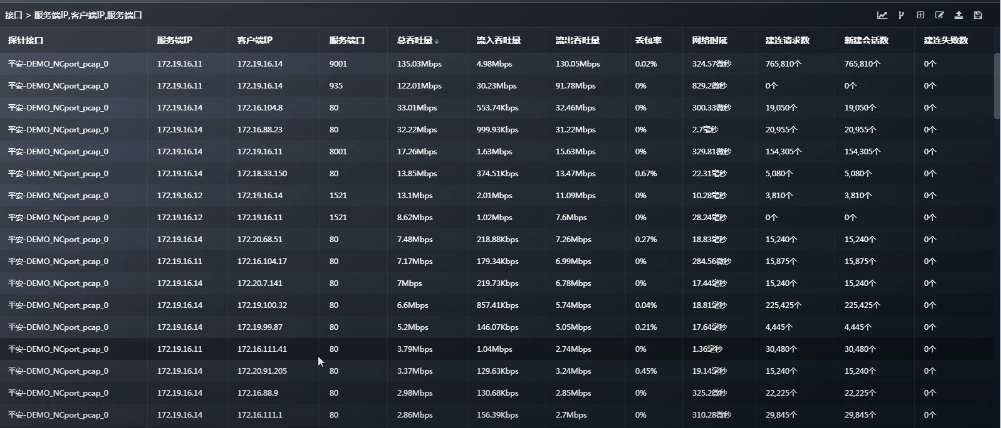
右上角可以单独 “修改维度” “修改指标” 。

“修改指标” 内具体内容:
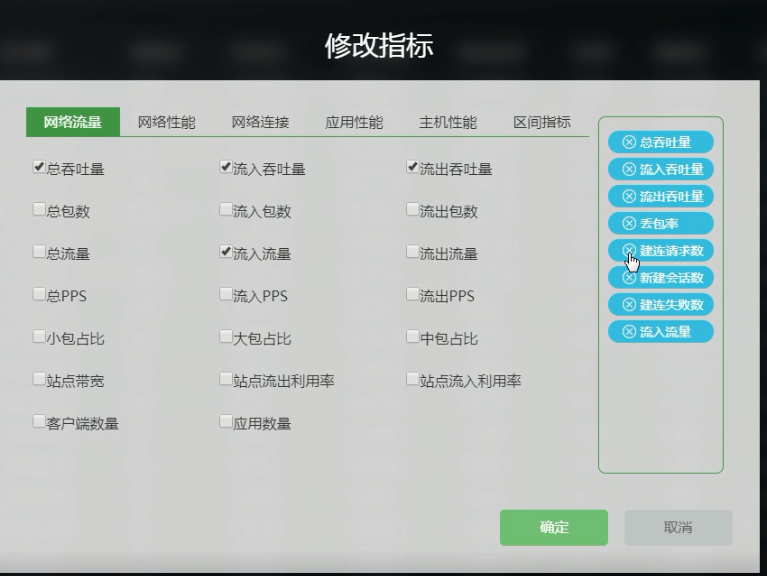

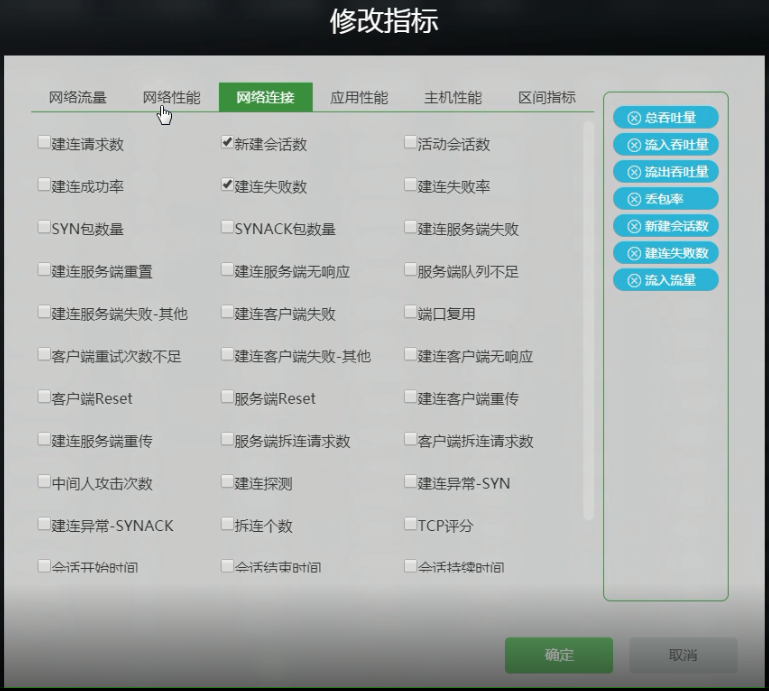
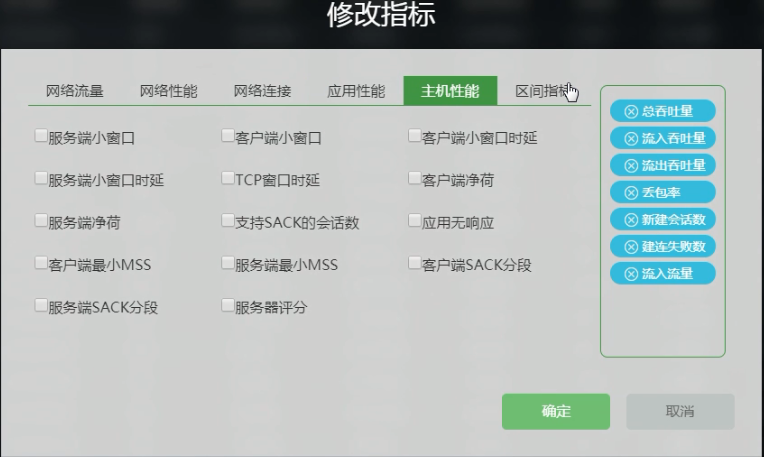
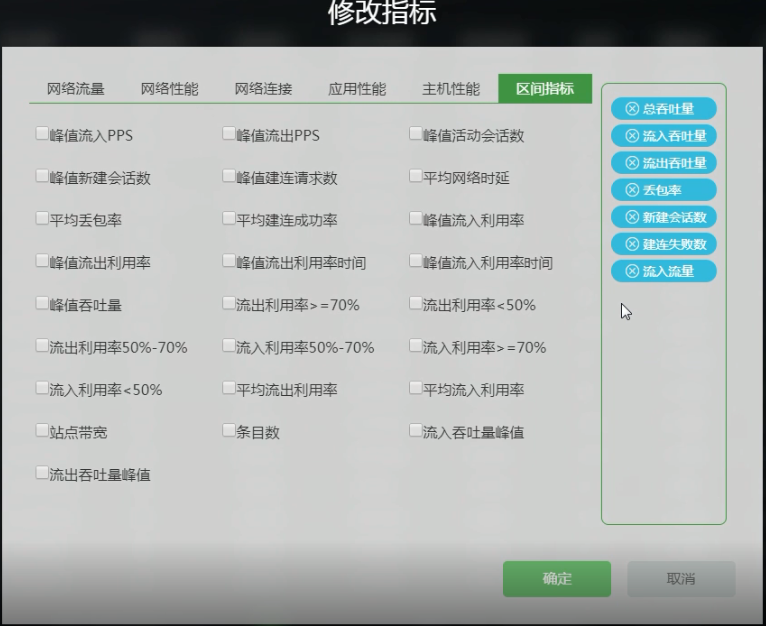
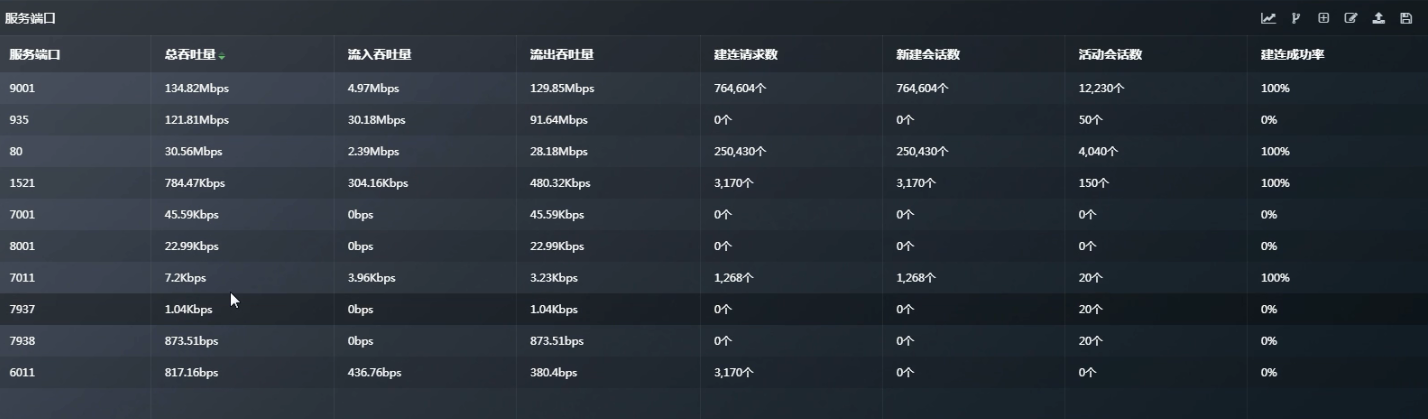
2.4.2 具体看一下“服务端口”数据表格(数据中心有哪些服务端口):
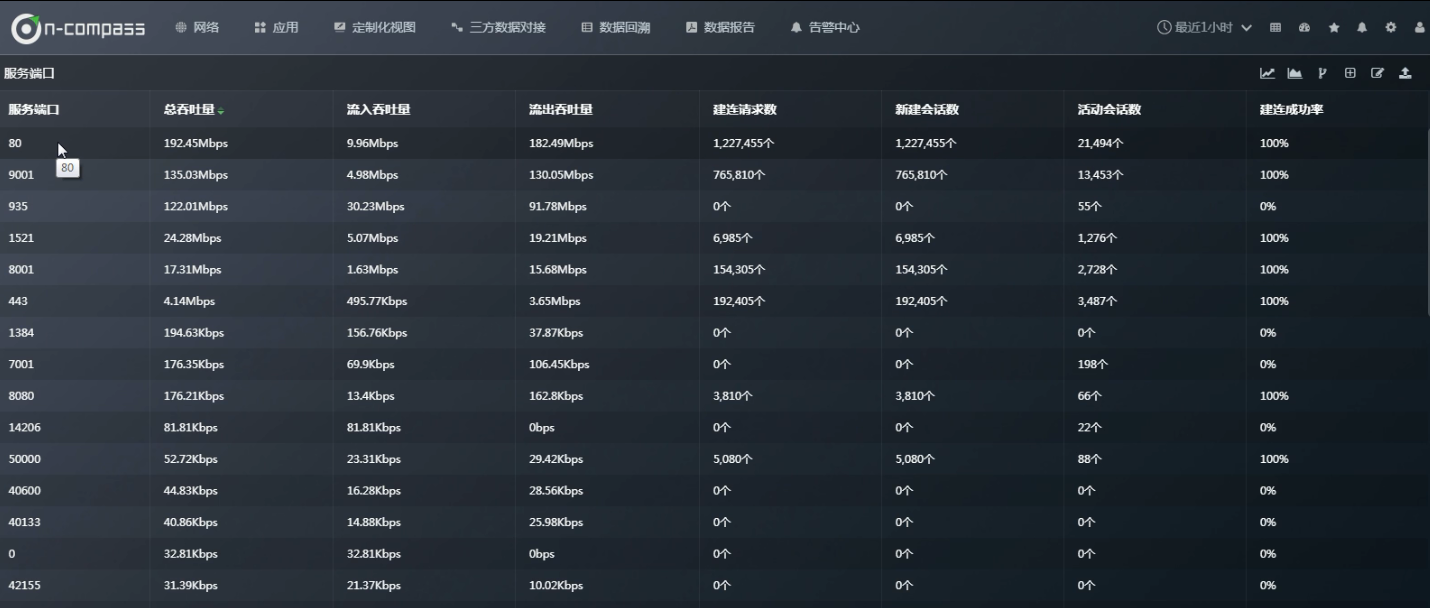
如何具体看都有哪些服务器使用了 80 端口:

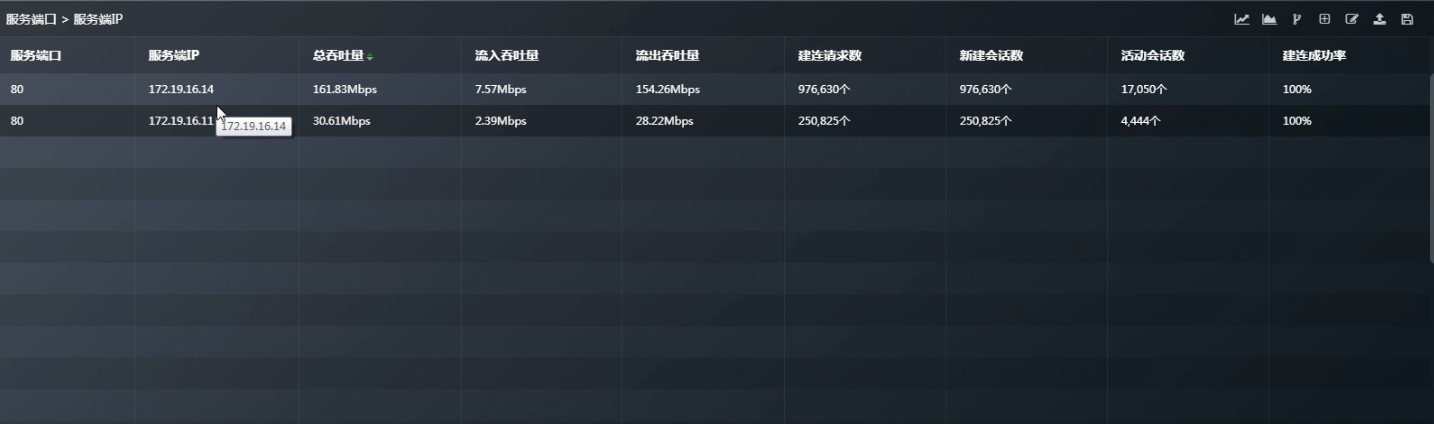
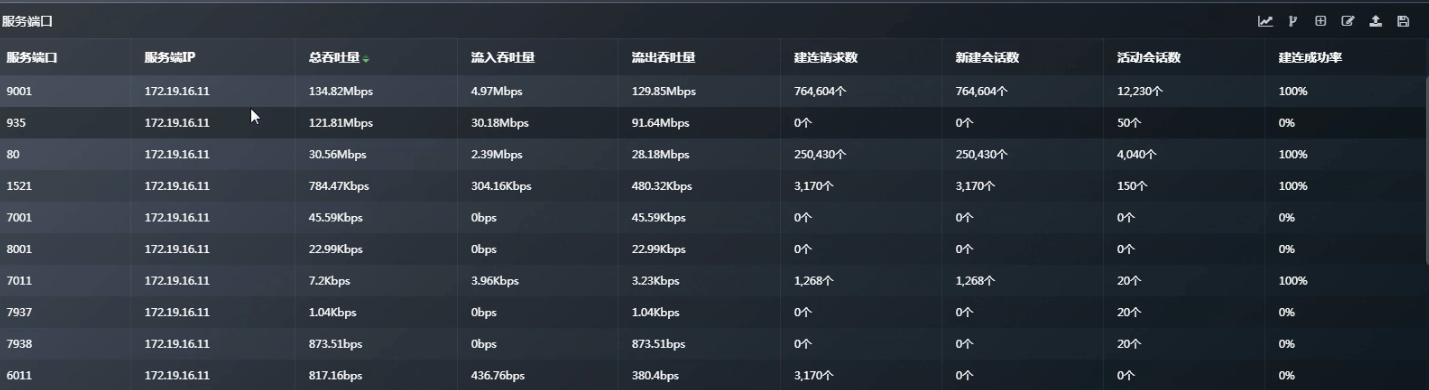
如何看一台服务器对外提供了哪些端口服务呢?
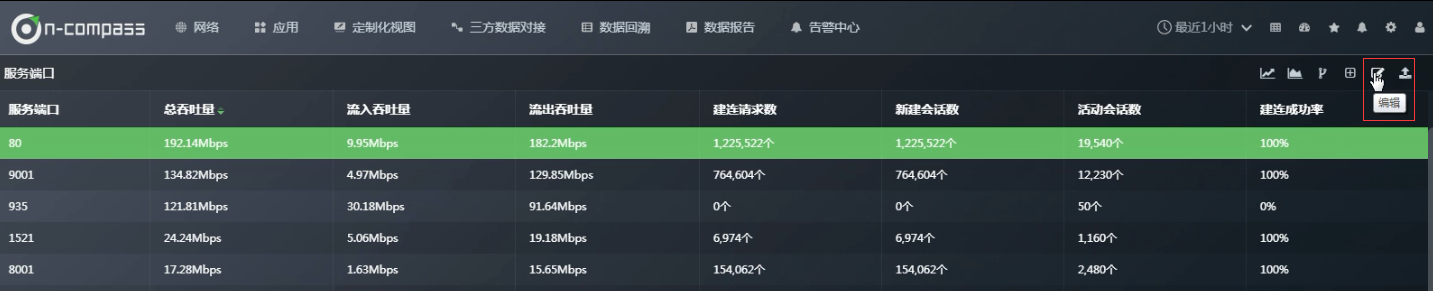

此时可以把“服务端IP”也添加进来

2.5 Dashboard 数据源的使用
新建一个Dashboard --- 图表区
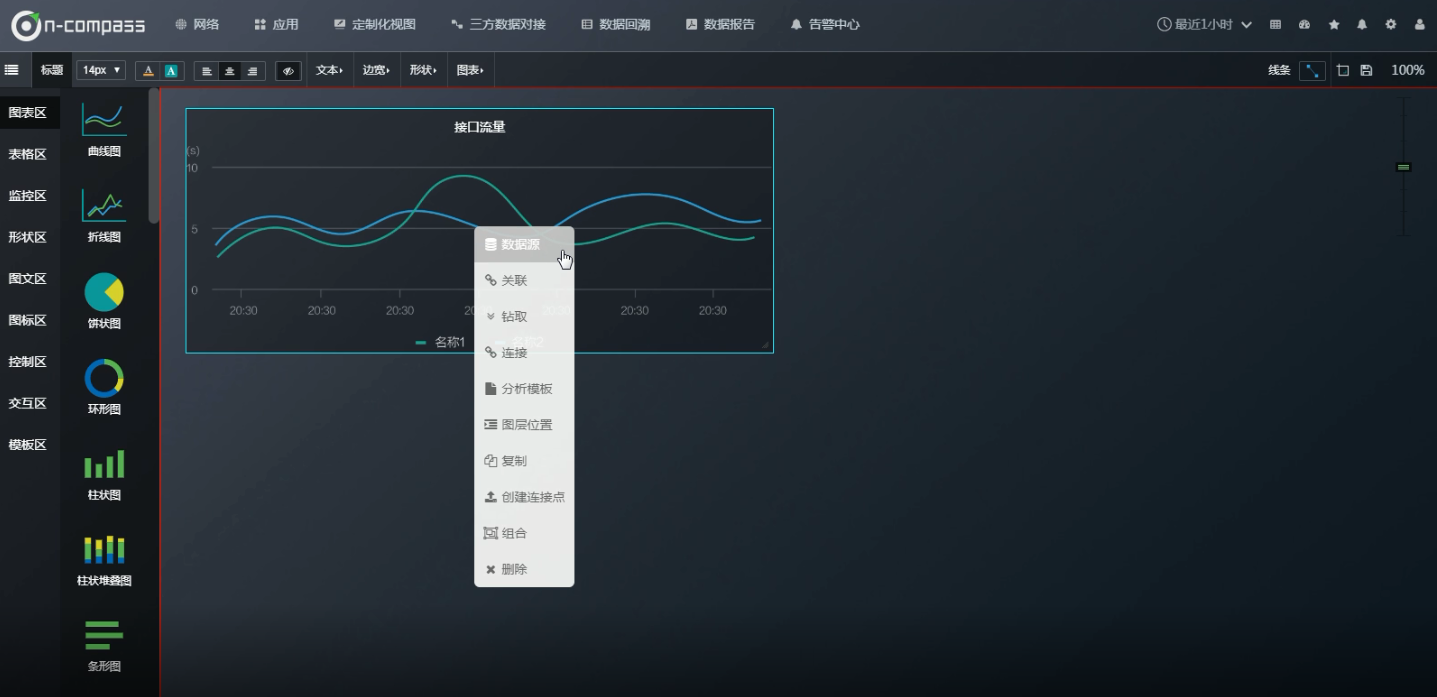



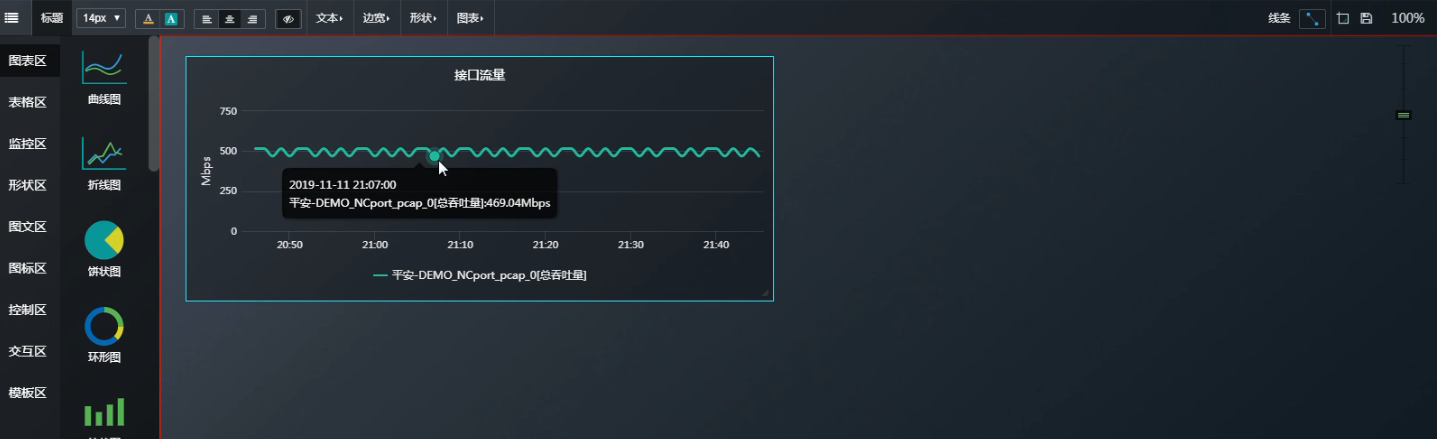
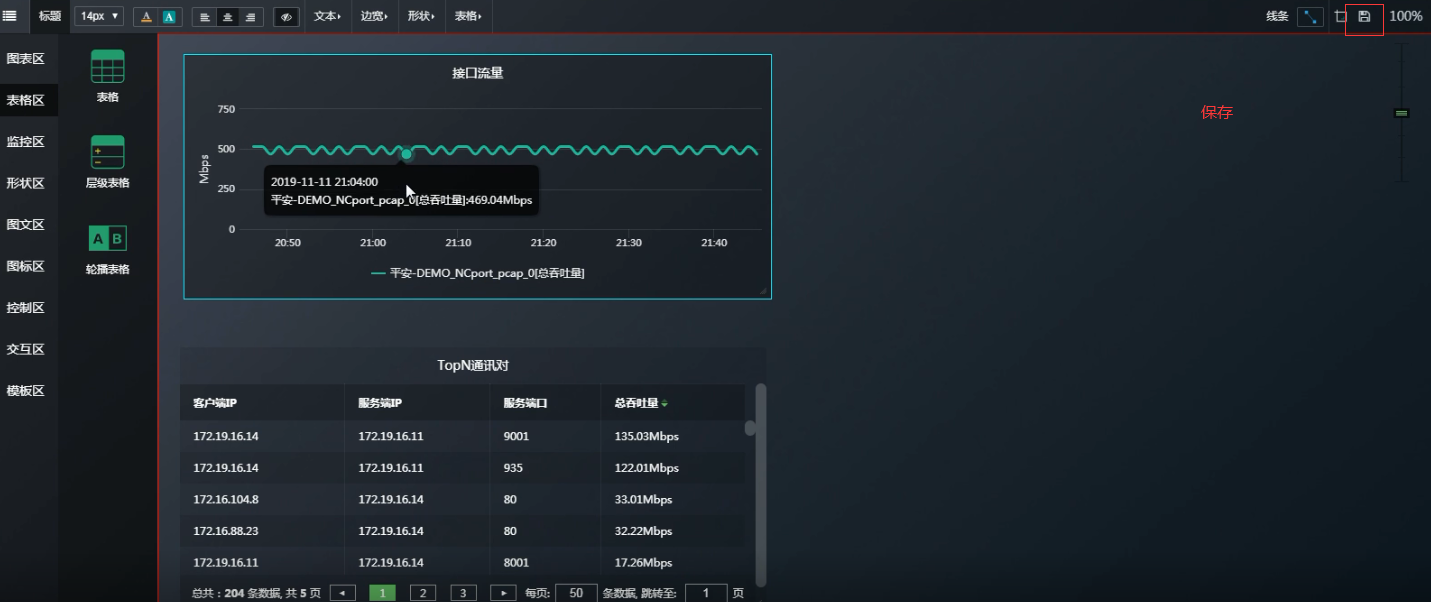
那么如果想知道曲线上面某一时间点的具体内容是什么? 可以新建一个表格区
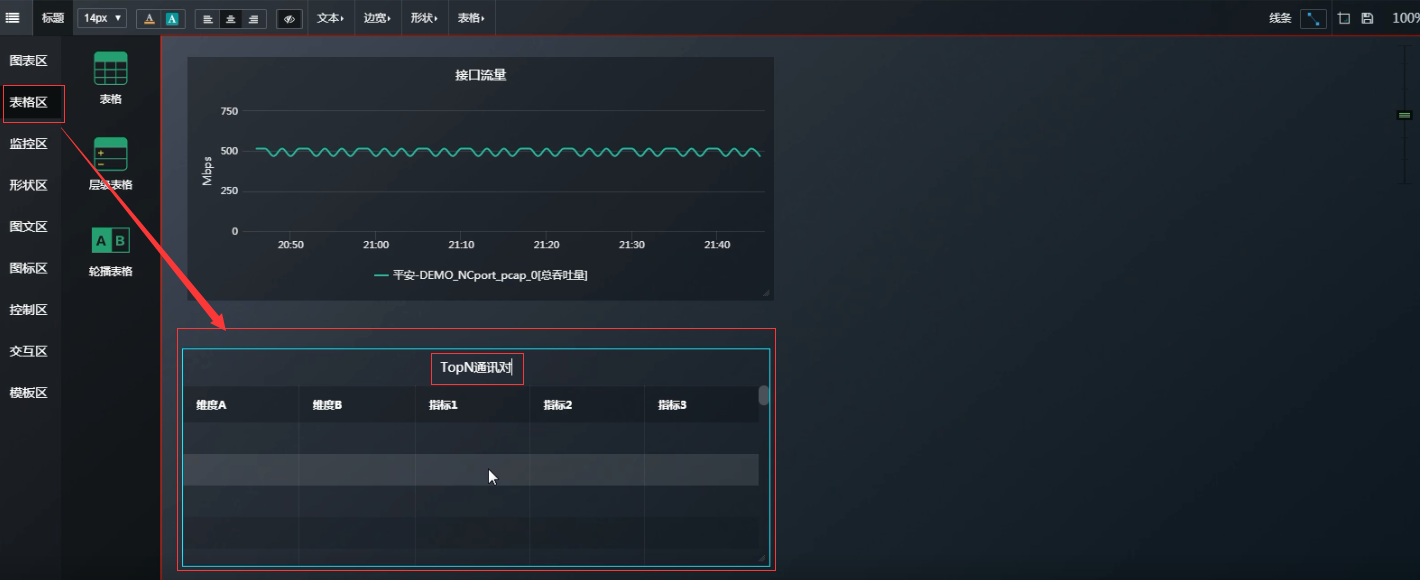
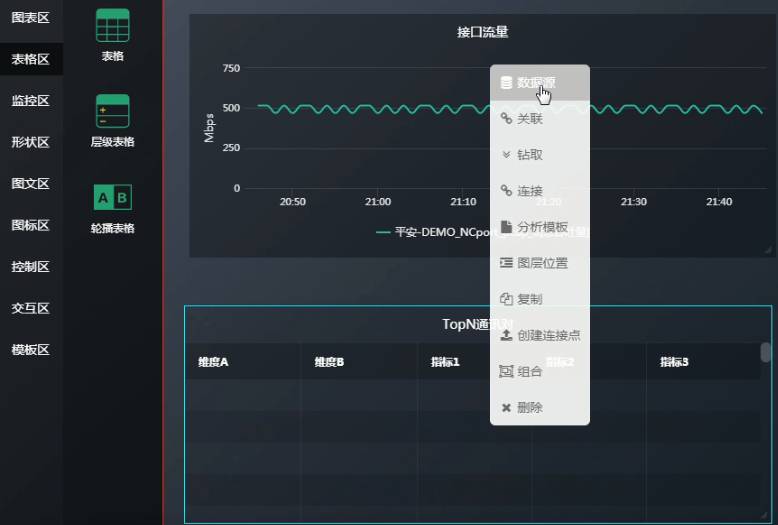

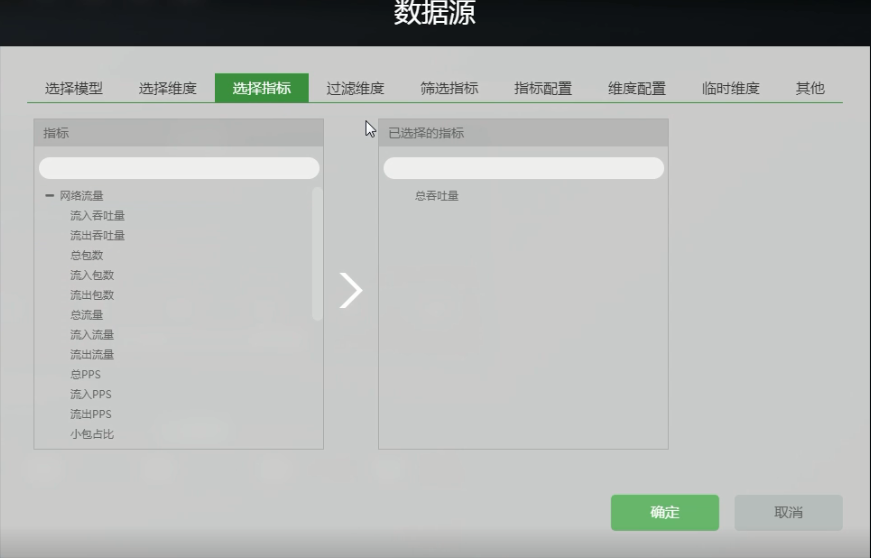
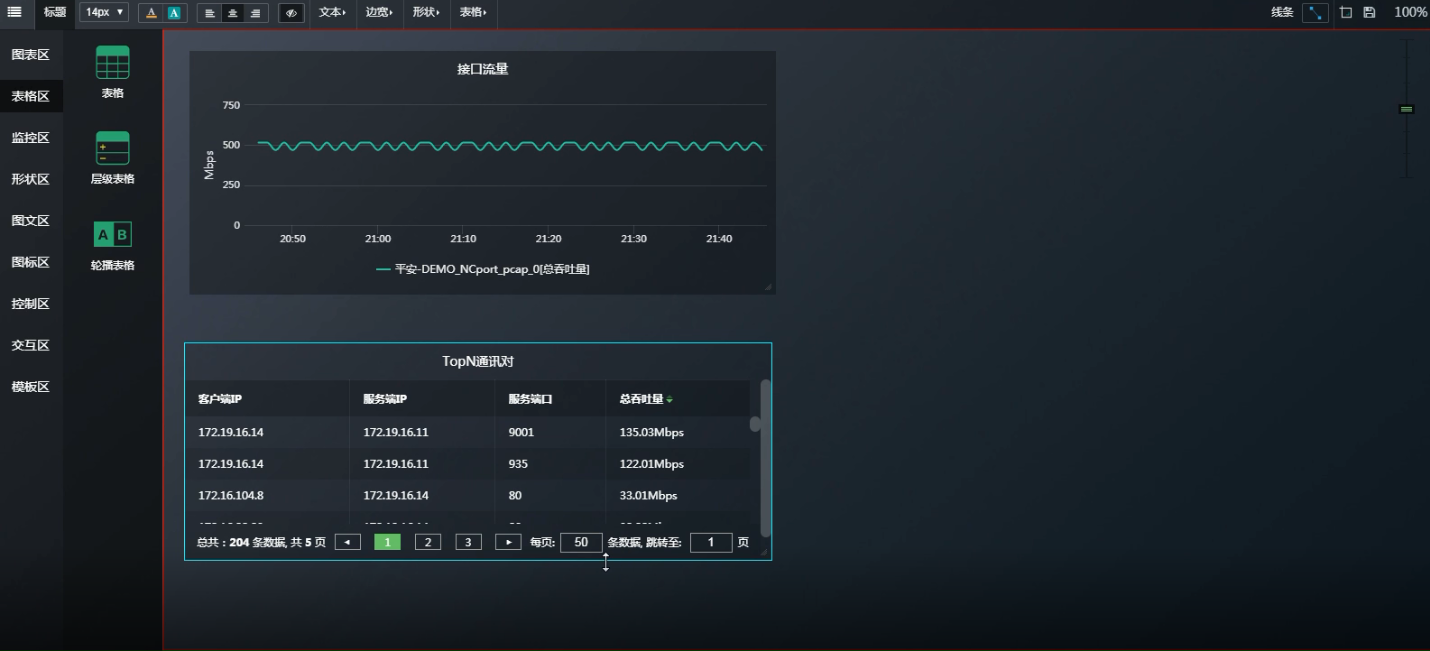
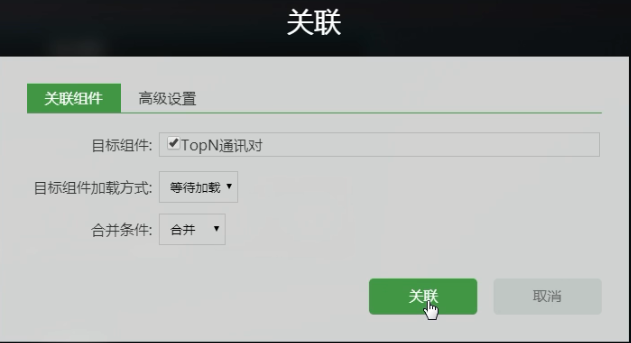
此时可以讲“接口流量”的图标区 和 “TopN通讯对”的表格区 做关联 。
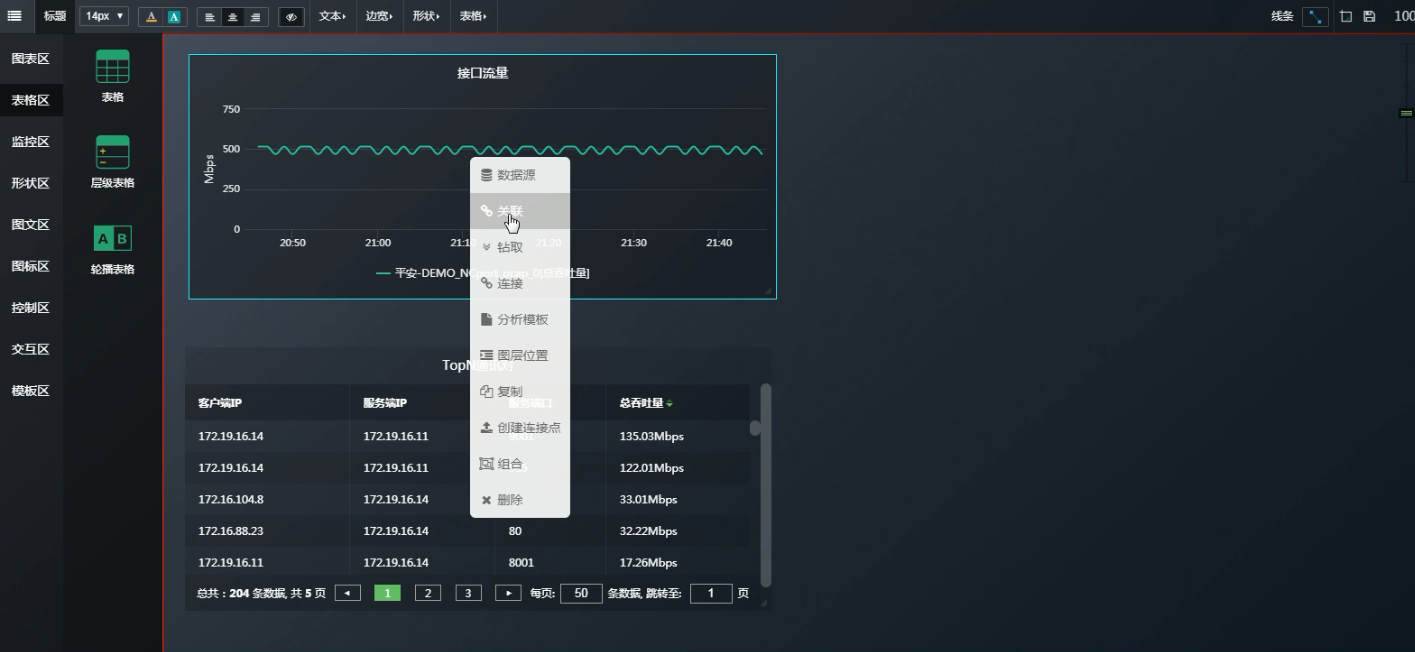
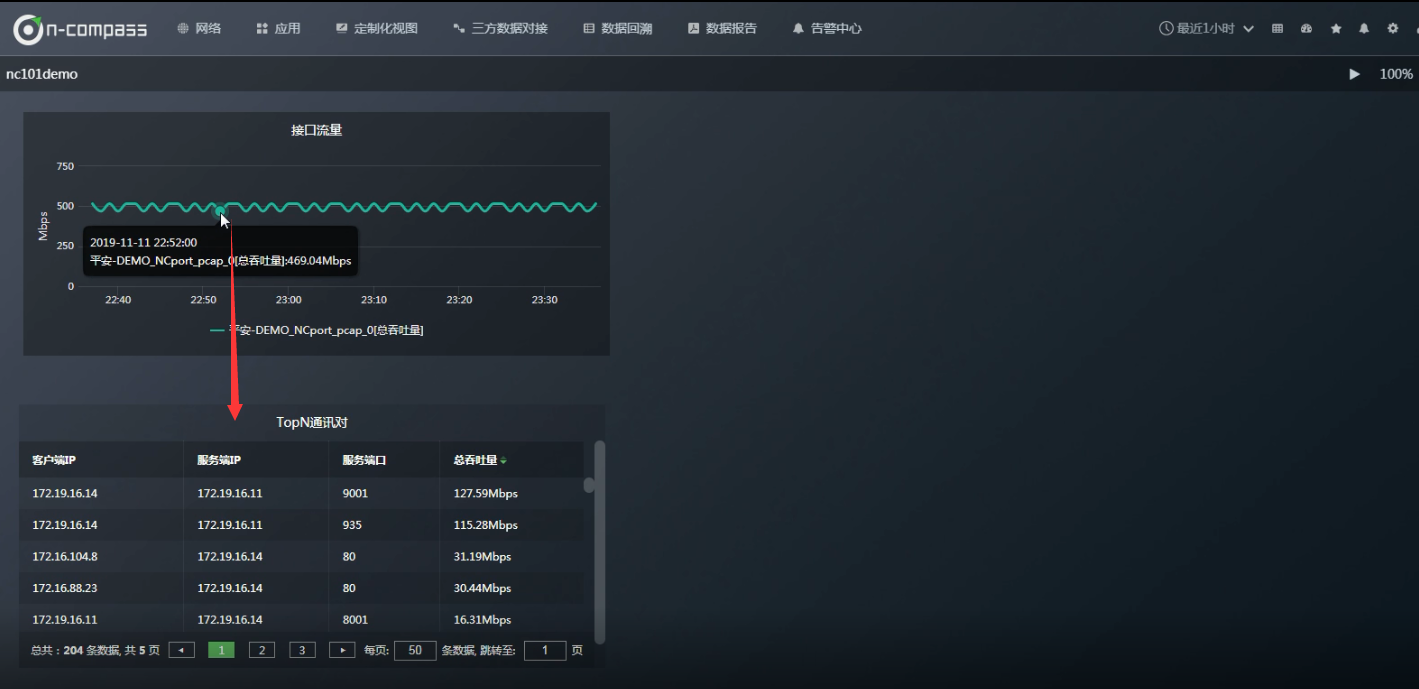
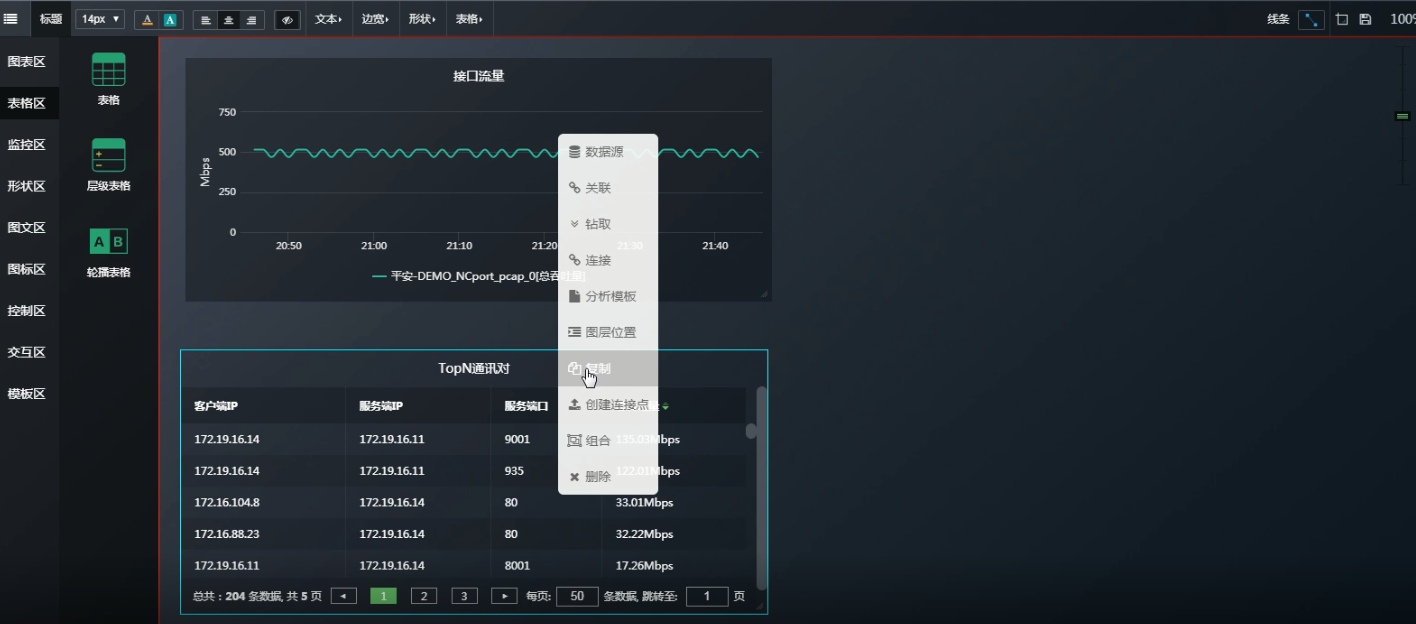
如果当你看到IP通讯对之后, 想进一步只看某一个客户端IP访问的所有服务器端IP端口,如何查看?
复制一份表格粘贴在表格区------再原表格右键关联-----

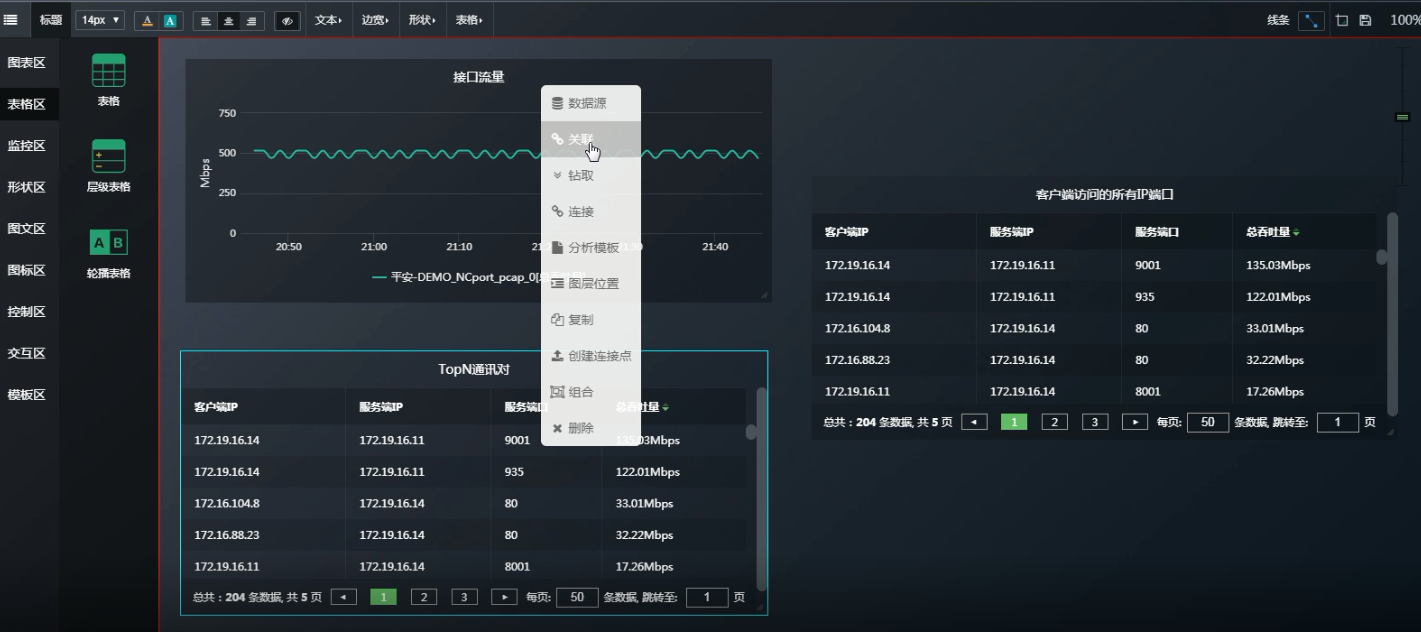
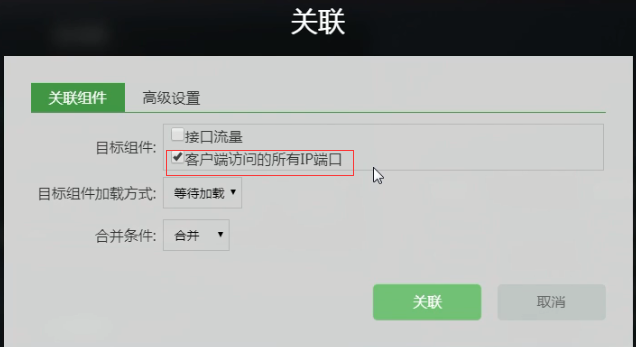
关联的时候把“服务器IP”“服务端口” 去掉, 意思就是当从表格“Top N通讯对”复制到关联表格“客户端访问的所有IP端口”时,会忽略“服务器IP”“服务端口” 。

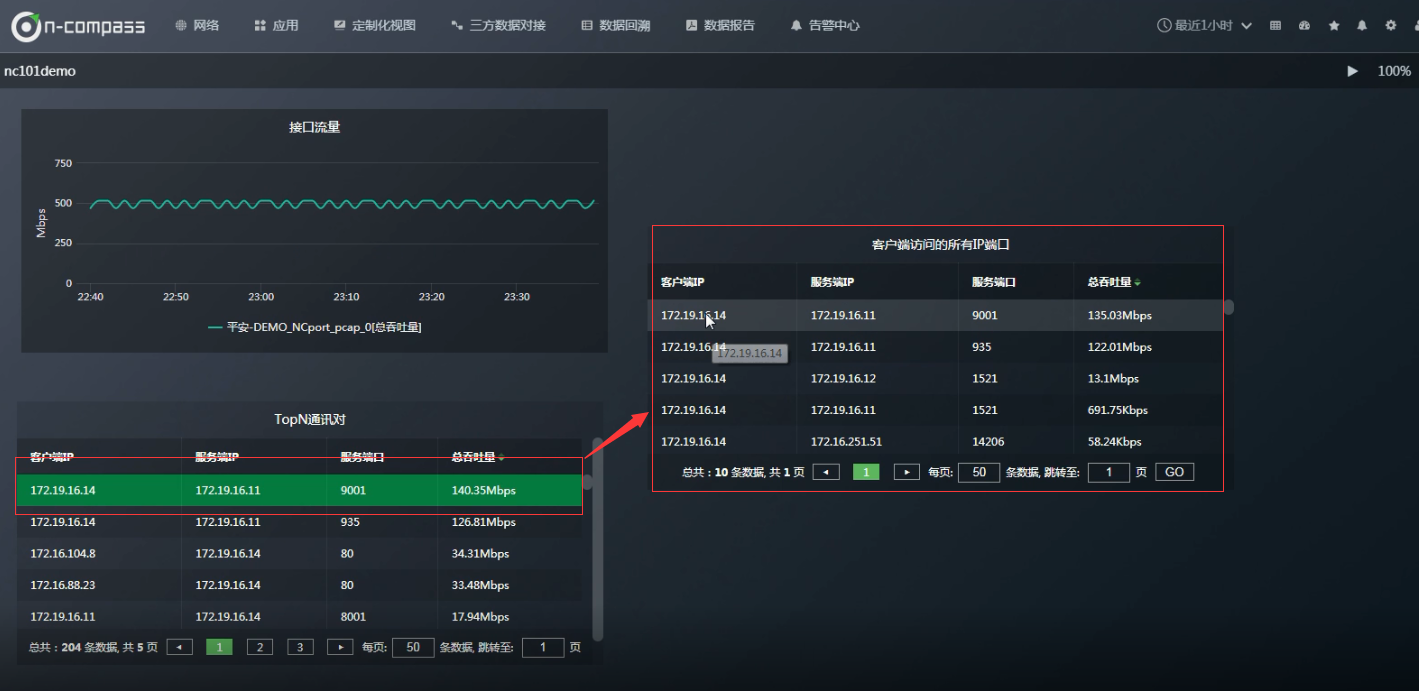
以上为列出所有客户端IP为172.19.16.14访问的所有ip端口。
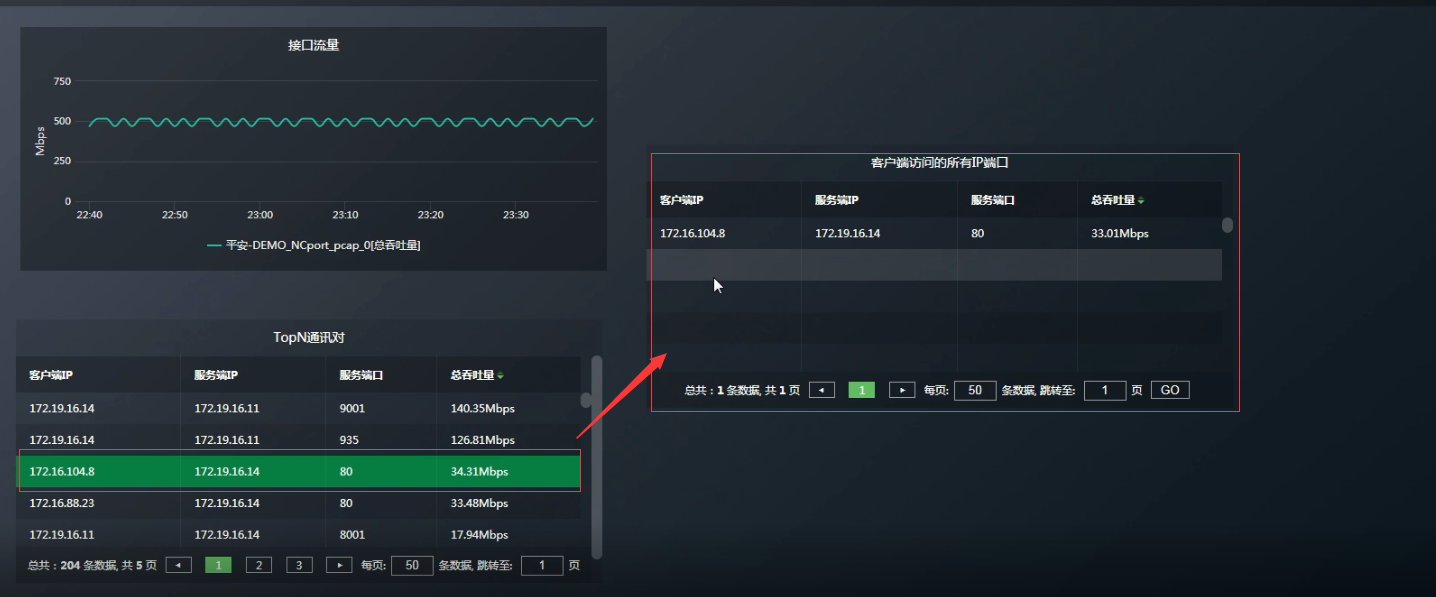
以上为列出所有客户端IP为172.16.104.8访问的所有ip端口。