18.2-sed编辑器高级特性
linux世界中最广泛使用的两个命令行编辑器:
- sed
- gawk
1. sed小结
命令格式:
1 sed [options] 'command' file(s)
2 sed [options] -f scriptfile file(s)
选项:
- -e<script>或--expression=<script>:以选项中的指定的script来处理输入的文本文件;
- -f<script文件>或--file=<script文件>:以选项中指定的script文件来处理输入的文本文件;
- -h或--help:显示帮助;
- -n或--quiet或——silent:仅显示script处理后的结果;
- -V或--version:显示版本信息。
参数:
文件:指定待处理的文本文件列表。
sed命令:
- a 在当前行下面插入文本。
- i 在当前行上面插入文本。
- c 把选定的行改为新的文本。
- d 删除,删除选择的行。
- D 删除模板块的第一行。
- s 替换指定字符
- h 拷贝模板块的内容到内存中的缓冲区。
- H 追加模板块的内容到内存中的缓冲区。
- g 获得内存缓冲区的内容,并替代当前模板块中的文本。
- G 获得内存缓冲区的内容,并追加到当前模板块文本的后面。
- l 列表不能打印字符的清单。
- n 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令。
- N 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码。
- p 打印模板块的行。
- P(大写) 打印模板块的第一行。
- q 退出Sed。
- b lable 分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾。
- r file 从file中读行。
- t label if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。
- T label 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。
- w file 写并追加模板块到file末尾。
- W file 写并追加模板块的第一行到file末尾。
- ! 表示后面的命令对所有没有被选定的行发生作用。
- = 打印当前行号码。
- # 把注释扩展到下一个换行符以前。
sed替换标记:
- g 表示行内全面替换。
- p 表示打印行。
- w 表示把行写入一个文件。
- x 表示互换模板块中的文本和缓冲区中的文本。
- y 表示把一个字符翻译为另外的字符(但是不用于正则表达式)
- 1 子串匹配标记
- & 已匹配字符串标记
sed元字符集:
- ^ 匹配行开始,如:/^sed/匹配所有以sed开头的行。
- $ 匹配行结束,如:/sed$/匹配所有以sed结尾的行。
- . 匹配一个非换行符的任意字符,如:/s.d/匹配s后接一个任意字符,最后是d。
- * 匹配0个或多个字符,如:/*sed/匹配所有模板是一个或多个空格后紧跟sed的行。
- [] 匹配一个指定范围内的字符,如/[ss]ed/匹配sed和Sed。
- [^] 匹配一个不在指定范围内的字符,如:/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行。
- (..) 匹配子串,保存匹配的字符,如s/(love)able/1rs,loveable被替换成lovers。
- & 保存搜索字符用来替换其他字符,如s/love/**&**/,love这成**love**。
- < 匹配单词的开始,如:/<love/匹配包含以love开头的单词的行。
- > 匹配单词的结束,如/love>/匹配包含以love结尾的单词的行。
- x{m} 重复字符x,m次,如:/0{5}/匹配包含5个0的行。
- x{m,} 重复字符x,至少m次,如:/0{5,}/匹配至少有5个0的行。
- x{m,n} 重复字符x,至少m次,不多于n次,如:/0{5,10}/匹配5~10个0的行。
2. sed高级特性--多行命令
所有的sed编辑器命令都是针对单行数据执行操作的,那如果处理多行名利怎么处理,sed编辑器包含了3个特殊的命令:
- N 将数据流中的下一行加进来创建一个多行组来处理
- D 删除多行组中的一行
- P 打印多行组中的一行
2.1 next 命令
2.1.1 单行next命令(小写的n)
n:读入下一行到模式空间,例:’4{n;d}’ 删除第5行。

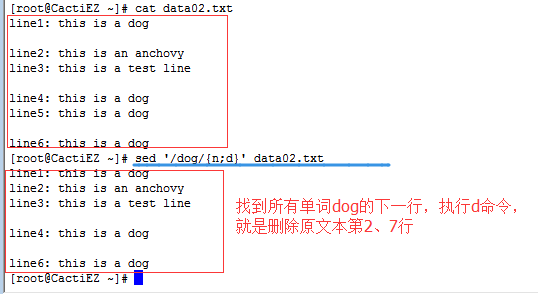
2.1.2 多行next命令(大写的N)
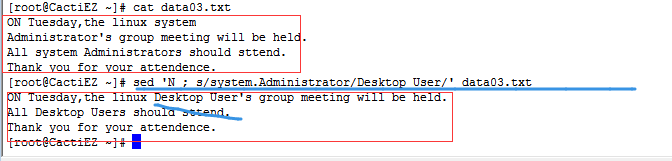
- 单行next命令n 会将数据流中的下一个文本行移动到sed编辑器的工作空间(模式空间)
- 多行next命令N 会将数据流中的下一个文本行添加到模式空间中已有的文本后,也就是讲数据流中的两个文本合并后到同一个模式空间中
①如果短语在同一行的话,N命令将下一行合并同一行,相对比较简单。
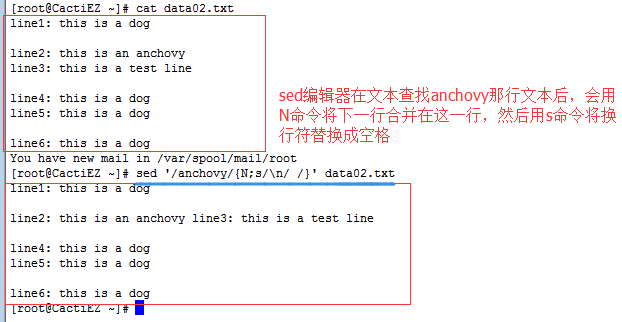
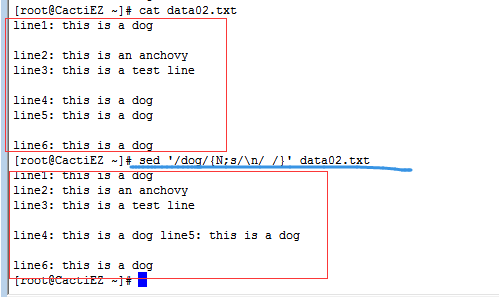
②如果短语不在同一行的话,替换命令就无法识别了,此时往往使用通配符.来匹配空格和换行符这两种情况。
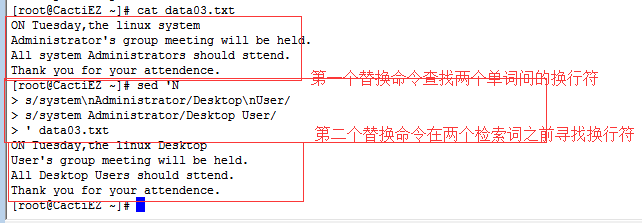
问题1:匹配了换行符时,就从字符串删掉了换行符,导致两行合并成一行。
解决办法:使用两个替换命令
- 一个用来匹配短语出现在多行的情况
- 一个用来匹配短语出现在单行的情况
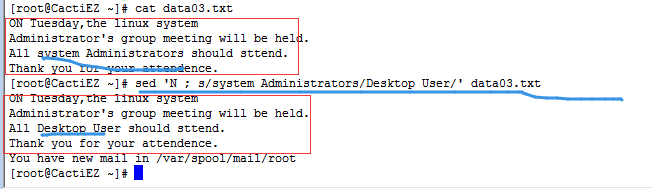
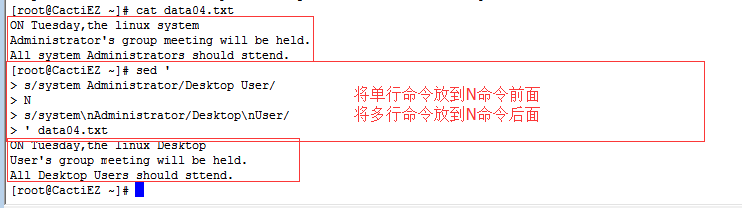
问题2:如果匹配的文本正好在数据流的最后一行,命令就不会发现匹配的数据。
解决办法:
- 将单行命令放到N命令前面
- 将多行命令放到N命令后面

2.2 delete 命令
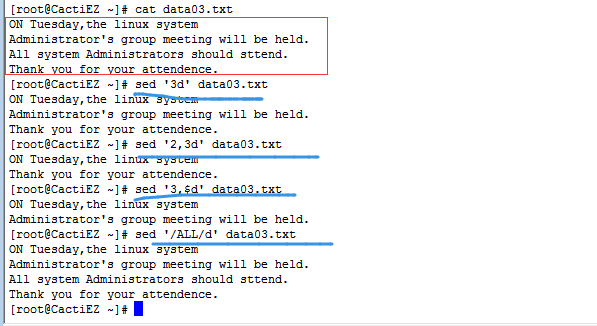
2.2.1 单行delete命令(小写的d) (上章已经介绍过了)
d:删除模式空间中的当前行
但是d 与N 一同使用的时候要注意,删除命令会在不同行查找匹配文本,然后在模式空间将所匹配的行全部删掉。
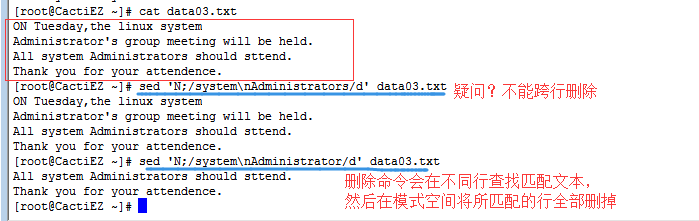
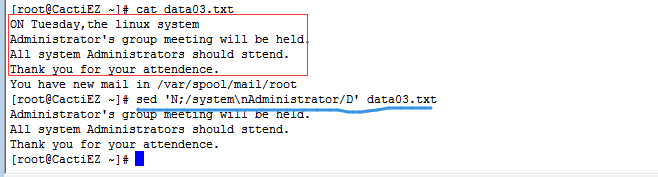
2.2.2 多行delete命令(大写的D)
D:只删除模式空间中的第一行,会删除到换行符位置的所有字符。
2.3 print命令
- p (小写) 打印模式空间的当前行
- P (大写) 打印多行模式空间的第一部分,直到第一个嵌入的换行符位置。在执行完脚本的最后一个命令之后,模式空间的内容自动输出。P命令经常出现在N命令之后和D命令之前。
3. sed高级特性--模式空间、保持空间
- 模式空间(pattern space)是一块活跃的缓冲区,在执行命令时它会保存待检查的文本
- 保持空间(hold space)在处理模式空间中的某些行时,可以保持空间来临时保存一些行
有5条命令用来操作保持空间:
- h 将模式空间复制到保持空间;
- H 将模式空间附加到保持空间;
- g 将保持空间复制到模式空间;
- G 将模式空间附加到保持空间;
- x 交换模式空间和保持空间的内容
4. sed高级特性--排除命令!
感叹号 ! 命令用来排除命令,就是让原本会起作用的命令不起作用。

5. sed高级特性--改变流
sed编辑器会从脚本的顶部开始,一直执行到脚本的结尾。sed编辑器提供了一个方法改变命令脚本的执行流程。
- 分支b命令用于无条件转移
- 测试t命令用于有条件转移。
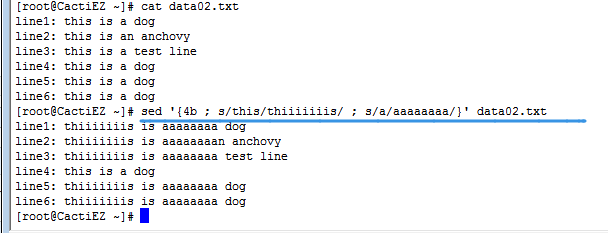
5.1 分支b命令
1 [address]b [lable]
- 跳转的位置与标签相关联:address决定了哪些行的数据会触发分支命令,lable参数决定了跳转到的位置。
- 如果有label参数则跳转到标签所在的后面行继续执行。
- 如果没有label参数,跳转命令会跳转到脚本的结尾。
- 标签:以冒号开始后接标签名,不要在标签名前后使用空格。
- 可以为分支命令指定一个模式来查找,如果没有模式,跳转就应该结束。(防止一些无穷循环)
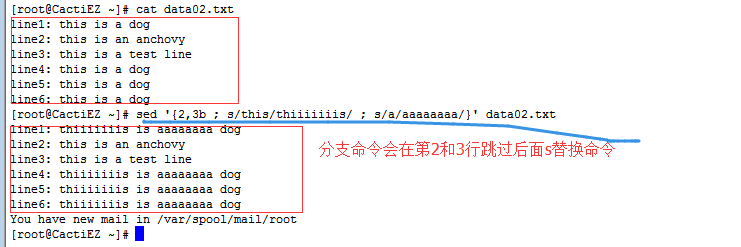
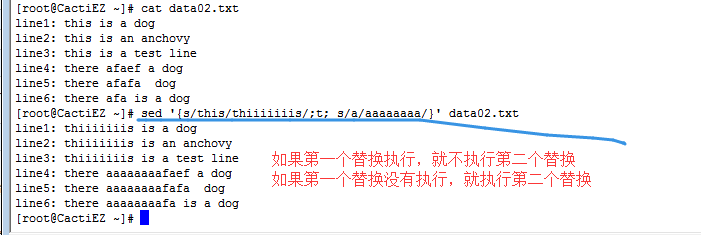
5.2 测试t命令
1 [address]t [lable]
- 测试命令t会根据替换命令结果跳转到某个标签,而不是根据地址进行跳转。
- 如果替换命令成功匹配并替换了一个模式,测试命令就会跳转指定的标签;如果替换命令没有匹配指定的模式,测试命令就不会跳转。
- 有指定标签的话,如果测试成功,跳转命令会跳转到脚本的结尾。
6. sed高级特性--模式替换
6.1 &符号用来代表替换命令中的匹配的模式

.at 当模式匹配了单词cat,“cat”就会出现在替换后的单词里。模式匹配了单词hat,“hat”就会出现在替换后的单词里。
6.2 替代单独的单词, 使用替代字符:反斜线+数字
替代字符由反斜线+数字组成,数字表明子模式的位置。sed编辑器会给第一个模式分配字符1 第二个模式分配字符2 以此类推。

7. sed高级特性--在脚本中使用sed
7.1 使用包装脚本wrapper
可以将sed命令放到shell包装脚本中,不用每次使用时都重新键入整个脚本。
7.2 重定向sed的输出
在脚本中使用$()将sed编辑器命令的输出重定向到一个变量中。