一、Scapy核心组件
- 引擎:用来处理整个系统的数据流处理,出发事物
- 管道:负责处理爬虫从网页上提取的实体信息,主要是持久化和验证实体的有效性,清楚不需要的信息。
- 调度器:接受引擎发过来的请求,由它决定下一个要爬取的网址,去处重复网址
- 下载器:下载网页内容,将网页发回给蜘蛛,scrapy
- 爬虫文件:即蜘蛛,从特定的网页中提取自己需要的信息,即所谓的实体。用户也可以从中取出连接,让scrapy继续抓取下一个页面
二、Scapy的POST请求
POST发起方法,重写父类start_requests()方法:
- 将scrapy.Request()的method方法修改成post(不建议该方法),默认是get方法
- 使用scrapy.FormRequest()方法来发起POST请求(推荐该方法)
项目:post提交关键字到百度翻译


# -*- coding: utf-8 -*- import scrapy class PostdemoSpider(scrapy.Spider): name = 'postDemo' #allowed_domains = ['www.baidu.com'] start_urls = ['https://fanyi.baidu.com/sug'] #方法一、修改Request()方法,将method赋值成post,不推荐 # def start_requests(self): # for url in self.start_urls: # yield scrapy.Request(url=url,callback=self.parse,method="post") #方法二、使用FormRequest方法,推荐 def start_requests(self): data={ "kw":"dog" } for url in self.start_urls: yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse) def parse(self, response): print(response.text)

三、Scapy的cookie操作
不需要可以去添加cookie,会自动携带
# -*- coding: utf-8 -*- import scrapy class DoubandemoSpider(scrapy.Spider): name = 'doubanDemo' allowed_domains = ['www.douban.com'] start_urls = ['https://accounts.douban.com/j/mobile/login/basic'] #重写父类的start_requests方法,使其发送post请求 def start_requests(self): #封装登陆信息 data={ "ck":"", "name":"用户名", "password":"密码", "remember":"false", "ticket":"" } #通过FormRequest方法发送登陆请求 for url in self.start_urls: yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse) def parse(self, response): #登陆后先保存主页数据后请求获取个人主页数据 fp=open("./index.html","w",encoding="utf-8") fp.write(response.text) fp.close() #个人主页url url="https://www.douban.com/people/191728538/" #这里会自动携带post请求之后的cookie参数 yield scrapy.Request(url=url,callback=self.parseSecongPage) def parseSecongPage(self,response): #解析个人主页数据 fp=open("./user_index.html","w",encoding="utf-8") fp.write(response.text) fp.close()
修改setting.py文件后执行爬虫
四、Scapy的proxy操作
下载中间件:拦截请求,可以将请求IP进行更换
流程:
下载中间件类的自定制,在middlewares.py文件中自定义Proxy类。重写process_request(self,request,spider)的方法
#自定义一个下载中间件类,在类中实现process_request()方法,处理中间件拦截到的请求 class MyProxy(object): def process_request(self,request,spider): #请求IP的更换 request.meta["proxy"]="https://124.107.173.110:8080"
在配置文件中开启下载中间件,即DOWNLOADER_MIDDLEWARES
DOWNLOADER_MIDDLEWARES = { # 'proxyPro.middlewares.ProxyproDownloaderMiddleware': 543, 'proxyPro.middlewares.MyProxy': 543, }
通过代理请求一个查询ip的地址

五、Scapy日志等级
ERRPR:错误,错误代码必须修改
WARAING:警告,可修改可不修改,不影响代码执行
INFO:一般信息
DEBUG:调试信息(默认)
让终端输出指定级别的信息:
在setting.py文件中添加:
指定输出某级别日志信息:LOG_LEVEL="ERROR"
将日志存储到指定文件中:LOG_FILE="log.txt"
六、请求传参
爬取的数据值不在同一个页面当中。
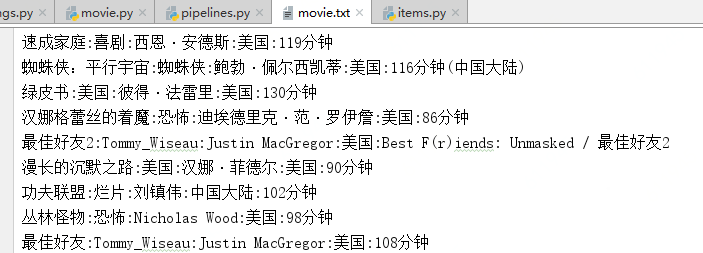
需求:将id97.com电影网站中的数据进行爬取,包括(名称,类型,导演,语言,片长)等数据
知识点:使用scrapy.Request(url,callback,meta)方式传参给callback函数
meta必须是字典类型,在callback方法中用response.meta.get("key")即可获取传入的参数
spider页面:
# -*- coding: utf-8 -*- import scrapy from moviePro.items import MovieproItem class MovieSpider(scrapy.Spider): name = 'movie' #allowed_domains = ['www.55xia.com'] start_urls = ['https://www.55xia.com/movie'] #解析二级页面内容 def parseBySecondPage(self,response): actor=response.xpath("/html/body/div[1]/div/div/div[1]/div[1]/div[2]/table/tbody/tr[1]/td[2]/a/text()").extract_first() language=response.xpath("/html/body/div[1]/div/div/div[1]/div[1]/div[2]/table/tbody/tr[5]/td[2]/a/text()").extract_first() longtime=response.xpath("/html/body/div[1]/div/div/div[1]/div[1]/div[2]/table/tbody/tr[8]/td[2]/text()").extract_first() #取出request方法的meta参数传递过来的字典 item=response.meta.get("item") item["actor"] = actor item["language"] = language item["longtime"] = longtime #所有内容都存储到了item对象,将item对象提交给管道即可 yield item def parse(self, response): #名称,类型,导演,语言,片长 div_list=response.xpath("//div[@class='movie-item-in']") for div in div_list: name=div.xpath("./div[@class='meta']/h1/a/text()").extract_first() kind = div.xpath("./div[@class='meta']/div[@class='otherinfo']/a//text()").extract_first() url="https:"+div.xpath("./a/@href").extract_first() #创建items对象 item=MovieproItem() item["name"]=name item["kind"] = kind #问题:二级页面数据怎么存入item类中。可使用meta传参给回掉函数,需字典类型 #需要对url发起请求,获取页面数据,进行指定数据解析 yield scrapy.Request(url=url,callback=self.parseBySecondPage,meta={"item":item})
我们穿给scrapy.Request()的url必须是带有协议头的完整url
pipelines管道页面:
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html class MovieproPipeline(object): fp=None def open_spider(self,spider): self.fp=open("./movie.txt","w",encoding="utf-8") def process_item(self, item, spider): detail="%s:%s:%s:%s:%s " % (item['name'],item['kind'],item['actor'],item['language'],item['longtime'],) self.fp.write(detail) return item def close_spider(self,spider): self.fp.close()
item页面:
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class MovieproItem(scrapy.Item): name=scrapy.Field() kind=scrapy.Field() actor=scrapy.Field() language=scrapy.Field() longtime=scrapy.Field()
在setting文件中关闭robots协议,添加user-agent信息,并打开ITEM_PIPELINES
执行:scrapy crawl movie --nolog
会在项目文件夹下创建一个movie.txt文件