本科毕业设计需要,最近开始进行Surveillance Monitering的入门学习。对看过的论文进行一些摘录和整理,一方面方便自己勘察,另一方面可以与大家进行交流学习。由于水平、基础有限,希望大家不吝赐教,谢谢~
论文来自:
[1]胡琼,秦磊,黄庆明. 基于视觉的人体动作识别综述[J]. 计算机学报,2013,12:2512-2524.
*******************************************************
部分内容为网上摘录,由于时间有限未能列出所有引用网站,请见谅。如有侵权,请联系ycjing@foxmail.com,会尽快删除文章和致歉。
*******************************************************
- 基于视觉的人体动作识别综述
[1]胡琼,秦磊,黄庆明. 基于视觉的人体动作识别综述[J]. 计算机学报,2013,12:2512-2524.
引言:
1. 人体动作识别是通过分析由视频得出的图像序列来学习人体的动作和行为。基础是运动检测、特征提取。
2. 步骤:(1)检测运动信息,提取特征。(2)对行为模式进行建模。(3)建立特征与动作行为类别之间的对应关系。
3. 计算机视觉领域三大顶级期刊: TPAMI, IJCV, TIP(TIP可能较前两个差一些——小木虫)。
4. 三类方法: a非参数方法、b立方体分析方法、c参数化时间序列分析。
a 很简单,只是将特征与template进行匹配。
b 不基于帧,而是看做一个三维的时空立方体。(不太懂)
c 最高端,给出运动模型,通过训练得出模型参数。常见模型:隐马尔可夫模型(HMMS),线性动态系统(LDSs)。
动作识别特征:
1. 影响因素:目标远近
2.特征分类:a静态特征,b动态特征,c时空特征,d描述性特征
a 包括尺寸,颜色,边缘,轮廓(contour),形状,深度。
缺点是 边缘与轮廓信息的获取很难,或者说不准确。
方法:用Canny边缘检测器检测边缘数据来表示形状信息。
扩展SFS(Shape from Silhouette轮廓)估计人体关节所在位置,从而识别动作。
Fiedler Embedding方法利用了旋转图像
可以从深度(图像深度:存储每个像素所用的位数,深度图像:深度图中每一个像素值表示场景中某一点与摄像机之间的距离)图像中预测人体关节三维时空位置。
b 包括运动速度,运动方向,运动轨迹。轨迹可以得出速度和方向。但轨迹特征很容易出错。
故开始研究光流特征。 何为光流特征?先说光流场是啥。空间中,运动可以用运动场描述。在图形中,物体运动通过图像序列中不同图像灰度分布的不同来体现,这个就是光流场,其实就是由三维到二维的一个投影。光流场反映的是图像上每一点灰度的变化趋势。再说光流,光流是空间运动物体在成像平面上的像素运动的瞬时速度,光流法是通过相邻帧之间在时间域上的变化来计算物体运动信息的一种方法,需要通过光流场找到图片中每个像素点的速度向量。
想一想,其实光流法需要考虑的一个问题是如何确定前一帧和后一帧哪个和哪个像素点是对应的,光流法有这样的假设:颜色(亮度)一致,微小运动,同一子图像像素点运动相同。有个这样的假设,就好办多了。
只需要在周围找一些亮度颜色相同的点就好,而且找到了一个其他周围的很多点也可以找到了。
但是可以想象,光流法虽然很多人提出了各种基于光流法的改进方法,但时间复杂度太高。故又有研究者开始想到对特征点进行追踪。可以找一些关键点来进行。
c (x,y,t)下研究 。
方法:
时空模板法:连接静态帧成运动序列,得到Motion Energy Image或Motion History Image,来表征动作。还有人将图像通过滤波,得出响应作为特征。另外,还可以直接从(x,y,t)空间内提取三维的形状。
缺点:依赖预处理(人体轮廓)或匹配。
局部时空兴趣点法:应用Harris角点(角点是二维图像亮度变化剧烈的点或图像边缘曲线上曲率极大值的点,知管来说就是水平和数值两个方向变化均较大的点,角点的检测主要有基于图像边缘的方法和基于图像灰度的方法,Harris算子属于后者)还可以应用线性滤波器。
缺点:局部特征之间的空间几何关系没有很好的进行利用。
时空上下文特征法:关注局部特征之间的空间几何关系,对其进行建模。
d 与以上三种方法相比的优势在于充分利用了动作视频中的语义信息。如定义一个动作属性空间,每一维表示一个语义属性,每个动作表示为属性空间中的一个点。
总结:从大类上说可以归结为3类:基于底层跟踪或姿态估计的方法(静态特征和基于运动信息的动态特征),基于图像处理技术直接从图像中提取特征的方法(基于光流的动态特征和时空特征),基于学习方法得到的属性描述(物体、姿态和场景等中层语义特征)
动作识别方法:
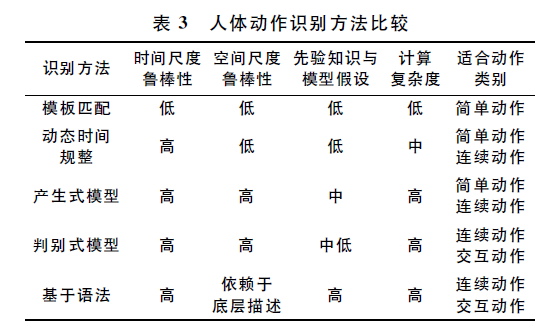
1. 基于模板的方法:
模板匹配(一个静态模式,模板特征可以是颜色,形状等,距离可以用欧式距离等)
动态时间规整(一组静态模式,解决同一个动作在不同视频中持续时间不同的问题,缩短时间)
2. 基于概率统计的方法:
产生式模型:可处理数据不完整的情况,常见模型有高斯混合模型,隐马尔可夫模型(Hidden Markov Model,HMM),概率潜在语义分析(Probabilistic Latent Semantic Analysis, PLSA)和潜在狄利克雷分配(Latent Dirichlet Allocation, LDA)。缺点在于依靠简化的统计假设来计算特征和状态之间的联合概率,不能直接计算条件概率。
判别式模型:在给定特征后可以直接计算条件概率分布,常见模型有线性判别分析,支持向量机,提升方法(Boosting),条件随机场(CRF)。
3. 基于语法的方法:
动作表示为一连串的符号,每一个符号表示原子动作。
常用数据库:
TREC国际评测:主要是英国伦敦国际机场的监控视频数据
IPETS竞赛
SDHA竞赛:人体行为语义描述的竞赛,对视频中行为进行语义标注
UCF101是目前最大的动作数据集,包含101个动作类别。
比较表格: