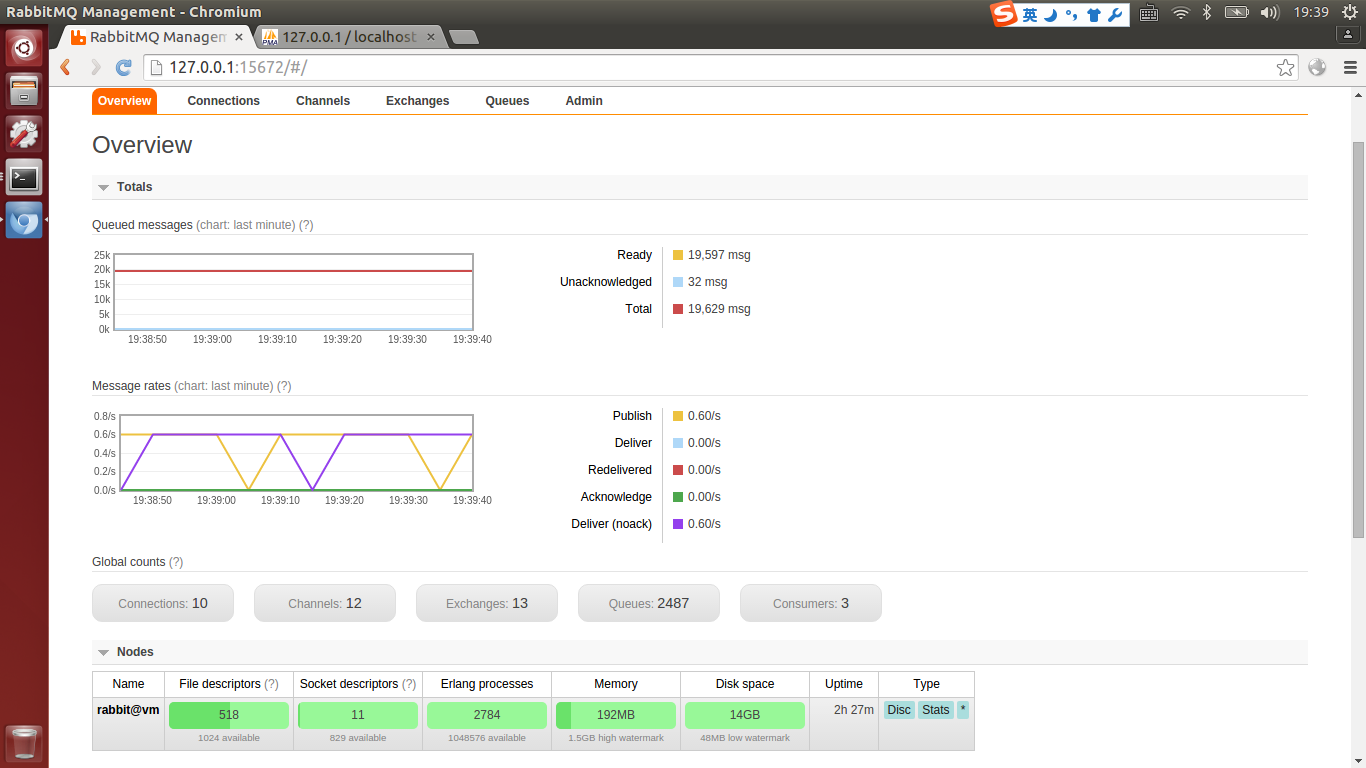
首先,记录下遇到的问题吧,在抓取的过程中为了避免IO操作,主要用Redis做插入缓存,当内存占用率很大时,会周期性的持续到Mysql里
虽然是拆东墙补西墙,但把数据抓取完毕后持续化可以慢慢进行,毕竟数据已经保存到内存里了,但问题来了,由于Redis的内存管理机制
并不会在数据删除后立即释放内存,使得将数据删除后Redis的内存占用率还是很高,这里引出官方说明,希望能说明些情况:
Redis will not always free up (return) memory to the OS when keys are removed. This is not something special about Redis, but it is how most malloc() implementations work. For example if you fill an instance with 5GB worth of data, and then remove the equivalent of 2GB of data, the Resident Set Size (also known as the RSS, which is the number of memory pages consumed by the process) will probably still be around 5GB, even if Redis will claim that the user memory is around 3GB. This happens because the underlying allocator can't easily release the memory. For example often most of the removed keys were allocated in the same pages as the other keys that still exist.
把问题记录下来,贴图占坑吧,有时间慢慢更新,找工作哟找工作,真不易.