纸上得来终觉浅,绝知此事要躬行。
前言
对比了原生Django和DRF的区别之后,本章就来谈谈DRF中最实用的一部分---序列化器(serializers),Django有了DRF的序列化器就可以帮我们节省很多的序列化操作(字典转Json)、反序列化操作(Json转字典)以及相关的字段校验等等。在了解DRF序列化器的使用的时候,我们先来看看他们的家谱图:
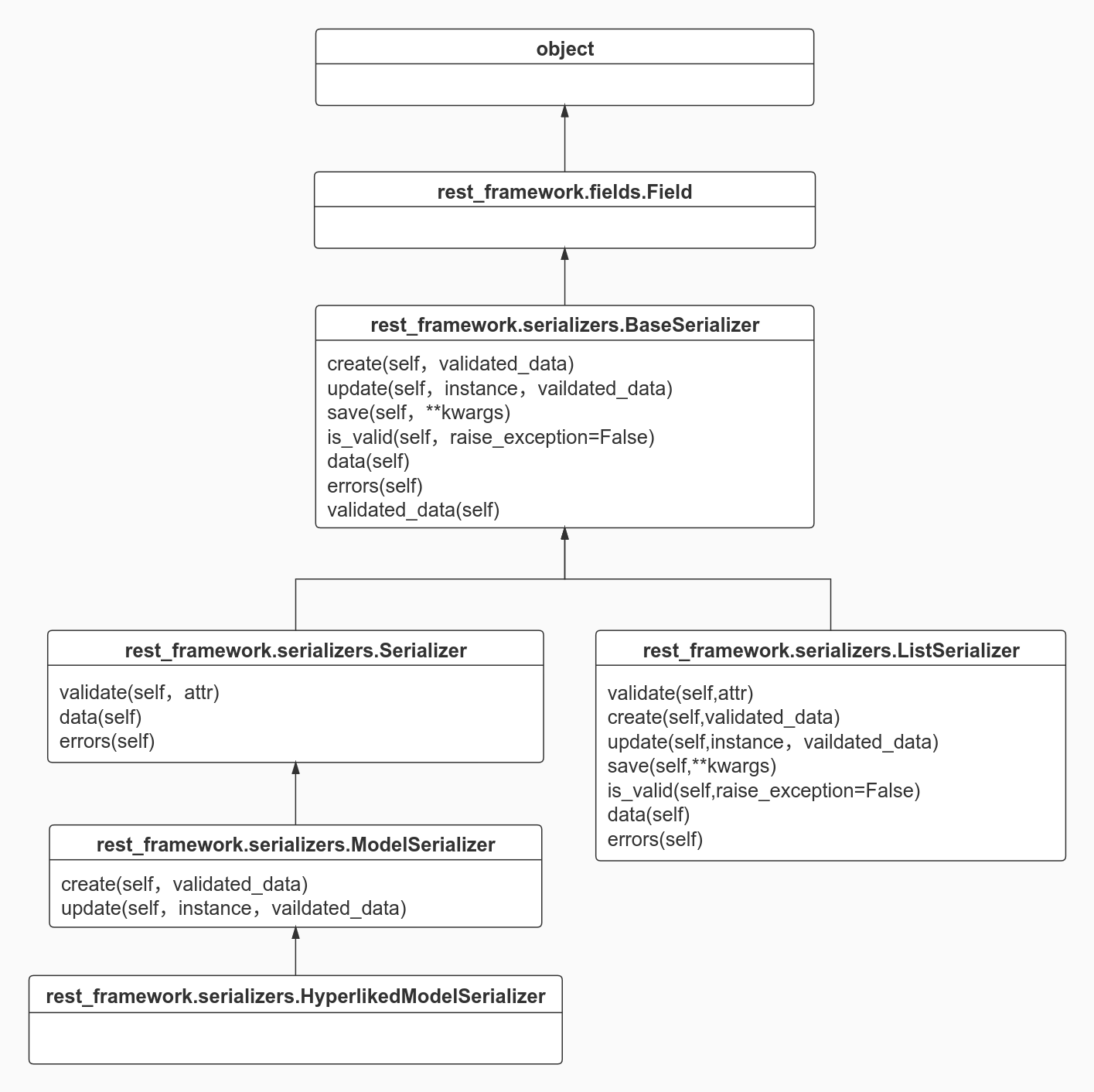
通过UML图我们可以清楚的看到每个类的的继承关系(由于有些类过于底层以及类中的方法都是起辅助作用,所以就没有展示出来),然后我们主要还是要了解Serializer、ModelSerializer、ListSerializer这三个序列化类以及他们的用法和注意点,首先我们从底层的类开始,逐步向上。
在分析之前我们先把准备一下需要用到的数据:
- models.py 定义模型类
class UserModel(models.Model):
GENDER = (
(0, '女'),
(1, '男')
)
username = models.CharField(max_length=64)
password = models.CharField(max_length=32)
phone = models.CharField(max_length=11, null=True, default=None)
gender = models.IntegerField(choices=GENDER, default=1)
avatar = models.ImageField(upload_to='avatar', default='avatar/default.jpeg')
class Meta:
db_table = "user"
verbose_name = "用户"
verbose_name_plural = verbose_name
def __str__(self):
return self.username
- views.py 定义视图
from rest_framework.views import APIView
from .models import UserModel
from . import serializers
class User(APIView):
def get(self, request, *args, **kwargs):
pk = kwargs.get("pk")
if pk:
# 查询单个用户
user = UserModel.objects.filter(pk=pk).first()
data = serializers.UserSerializer(instance=user).data
else:
# 查询多个用户
users = UserModel.objects.all()
datas = serializers.UserSerializer(instance=users, many=True).data
def post(self, request, *args, **kwargs):
data = request.data
serializer = serializers.UserDeserializer(data=data)
# 校验数据
if serializer.is_valid():
# 校验通过保存数据
serializer.save()
...
else:
# 校验失败
...
- urls.py 定义路由
from django.conf.urls import url
from . import views
urlpatterns = [
url(r'^users/$', views.User.as_view()),
url(r'^users/(?P<pk>d+)/$', views.User.as_view()),
]
Serializer定义
首先在一个Django app下创建一个serializers.py的文件,用来存放我们当前app的所有序列化和反序列化的类,之后编写以下代码框架:
from rest_framework import serializers # 导入序列化器类
class UserSerializer(serializers.Serializer): # 继承自Serializer
pass
上面我们定义了一个用户序列化类,下面我们可以给类中简单定义一些字段:
from rest_framework import serializers # 导入序列化器类
class UserSerializer(serializers.Serializer): # 继承自Serializer
id = serializers.IntergetField() # 序列化括号里面不用加条件
name = serializer.CharField()
....
在我们自己定义的UserSerializer类,想要序列化某些字段必须定义该字段,而且定义的字段名称要和Model类中的字段以及字段类型保持一致,例如上面定义的id和name,更多字段类型可以参考官方文档,下面我主要整理了一下每个字段可选的参数:
max_length:验证输入的字符数不超过此数量min_length:验证输入的字符数不少于此。allow_blank:如果设置为True,则应将空字符串视为有效值。如果设置为False,则认为空字符串无效,并将引发验证错误。默认为False。read_only:表示只读字段,意思不会参与反序列化,默认Falsewrite_only:表示只写字段,意思不会参与序列化,默认Falserequired:表示反序列化必填项,否则引发错误,默认Trueallow_null:表示反序列化传递None,通常会引发错误,默认Falsedefault:如果设置,则给出默认值,如果没有提供输入值,该默认值将用于该字段error_message:自定义验证错误信息validators:验证器功能列表,应将其应用于传入字段输入,并且会引发验证错误或简单地返回,这个不太懂可以参看官方文档
源码分析序列化类实例化过程
由于我们的UserSerializer没有初始化方法,从父类Serializer查找,发现也没有,而Serializer继承自BaseSerializer,所以继续从BaseSerializer查找初始化方法,发现找到,即源码如下:
def __init__(self, instance=None, data=empty, **kwargs):
self.instance = instance
if data is not empty:
self.initial_data = data
self.partial = kwargs.pop('partial', False)
self._context = kwargs.pop('context', {})
kwargs.pop('many', None)
super().__init__(**kwargs)
说明:
- 用于序列化时,将模型类对象传入instance参数
- 用于反序列化时,将要被反序列化的数据传入data参数
- 除了instance和data参数外,在构造Serializer对象时,接受多个关键字参数,代码中已经给出
partial,context,many(在后面会见到讲到用法)
PS:再次注意为了防止字段传入赋值错误建议采用xxx=xxx的形式传入参数。
序列化
序列化使用
我们知道序列化类是帮我们完成对象到Json的转换的,下面就是讲讲UserSerializer类的使用,在前言中我们已经定义了视图,在此我们只把简单的创建序列化类创建对象的过程加一分析,代码如下:
# 查询单个用户
user = UserModel.objects.filter(pk=pk).first()
data = serializers.UserSerializer(instance=user).data
# 查询多个用户
users = UserModel.objects.all()
datas = serializers.UserSerializer(instance=users, many=True).data
通过代码我们发现序列化时UserSerializer创建对象传入了两个参数instance和many,具体什么意思?如下:
instance:对于单个查询,表示一个传入一个Model类的对象,对于多查表示传入的是一个queryset类型,可以想象成是多个对象的列表many:主要针对于多查,作为一个标识字段,表示想获取多个用户,默认为False。
序列化UserSerializer
序列化的过程比较简单,因为不涉及字段校验,我们只需要把我们想传给前台的字段定义出来即可:
from rest_framework import serializers # 导入序列化器类
class UserSerializer(serializers.Serializer): # 继承自Serializer
id = serializers.IntergetField() # 序列化括号里面不用加条件
name = serializer.CharField()
# 自定义序列化属性
gender = serializers.SerializerMethodField()
avatar = serializers.SerializerMethodField()
def get_gender(self, obj):
return obj.get_gender_display()
def get_icon(self, obj):
return f'http://127.0.0.1:8000{settings.MEDIA_URL}{str(obj.icon)}'
注意:
SerializerMethodField:表示自定义字段,因为有些字段不能满足我们的需求,比如:我们后台定义的性别是按照0,1区分,而为了前台展示的友好性,我们需要把他转换成男和女,所以原生的字段无法满足,因此我们需要自定义,自定义的规则如下:
# 我之所以写名称而不写字段名,是因为他可以随意起名称
名称 = serializers.SerializerMethodField()
# 重要,重要,重要,重要的话说三遍,下面的方法必须定义,因为我们并没有给write_only=True,所以上面的自定义字段必须接受一个返回值
# 命名规则:get_名称,必须这样,obj表示当前的模型类对象
def get_名称名(self,obj):
return xxxx
反序列化
反序列化使用
反序列化对于序列化操作相对复杂,因为主要涉及到前台传过来的数据符不符合我们的要求,所以要进行一系列的判断和校验,最终才能保存到数据库。此时就用到了我们在序列化类中定义的字段以及对应的字段类型,其目的就是帮我们完成数据的校验。主要流程如下:
- 获取前台传过来的数据
- 创建序列化对象
- 调用
is_vaild()方法进行校验,验证成功返回True,否则返回False。 - 验证失败,可以通过序列化对象的errors属性获取错误信息,返回字典,包含了字段和字段的错误。
- 验证通过,先调用
UserSerializer对象调用save()保存数据,返回对象 - 传入保存数据的对象给
instance通过序列化器对象的data属性获取数据,最后返回刚才保存的数据
代码示例:
# 获取前台传来的数据
data = request.data
# 创建序列化对象
serializer = serializers.UserDeserializer(data=data)
# 验证数据
if serializer.is_vaild():
# 保存
user = serializer.save()
# 获取保存的数据
data = serializers.UserSerializer(instance=user).data
# 返回
return Response(data = data)
else:
# 获取异常信息
err_msg = serializer.errors
return Response(data = err_msg)
注意:
在保存数据的时候,也就是调用save()方法,默认会去执行create()或者update(),因为从源码可以得知,在BaseSerializer定义了两个方法,但是都是直接抛出异常。所以我们必须重写create方法用于新增,重写update方法是修改。
反序列化UserDeSerializer
由于反序列化涉及字段的验证,在调用is_vaild()方法的时候进行字段校验,所以对于反序列化类的定义比较多,具体代码如下:
class UserDeserializer(serializers.Serializer):
username = serializers.CharField(
max_length=10,
min_length=3,
error_messages={
'max_length': '名称长度3-10',
'min_length': '名程长度3-10'
}
)
password = serializers.CharField()
phone = serializers.CharField(
required=False
)
password2 = serializers.CharField(required=True)
# 局部钩子
def validated_name(self, value):
pass
# 全局钩子
def validate(self, attrs):
pass
def create(self, validated_data):
pass
上面随便定义了几个字段,但是在实际开发中应该是我们后端需要前台传给我们的参数,这里为了演示就取了几个,会发现还定义了几个函数,下面就让我们分析一下他们的作用:
- 字段:字段定义以及字段的参数表示接受到的参数需要符合每一项的要求,否则抛出异常
- 局部钩子:有时可能字段的约束无法满足我们的需求,例如手机号的规范,我们就需要这样一个局部钩子,命名规范就是
validated_字段名(self,字段值),对应我们验证手机号就可以表示为validate_phone(self,value),value表示我们接受到的手机号,在此方法类就可以编写验证手机号的逻辑,如果正确直接返回value,否则我们直接抛出异常,代码定义如下:
from rest_framework.exceptions import ValidationError
def validate_phone(self,value):
if not xxxx:
raise exceptions.ValidationError('手机号不合法')
return value
- 全局钩子:当所有的字段以及所有的局部钩子走完,下面就可以在全局钩子继续完成之前无法完成的步骤,例如上面的密码校验,假如我们这个是一个注册校验,需要比对两次密码是否一致就需要用到全局钩子,因为全局钩子的参数包含了接受到的所有值,即
attrs(可以随便取名称)是一个字典类型可以直接获取,同样验证成功返回attrs,失败抛出异常,代码定义如下:
def validate(self, attrs):
password = attrs.get('password')
password2 = attrs.pop('password2')
if password != password2:
raise exceptions.ValidationError('两次密码不一致')
return attrs
注意:由于我们数据库不需要保存password2,所以在校验完成需要把该值从字典去除,方便后续直接入库
上面的这些步骤是当我们在视图类调用is_valid()是逐个判断调用,成功之后就会返回True,之后就是我们的save()方法,其作用是将验证通过的数据保存在数据库,但是我们需要重写create()方法,如果是针对于数据修改也会经过上面的步骤只不过在调用save()默认调用update(),所以我们需要重写update()。代码示例如下:
# 要完成新增,必须自己重写 create 方法,validated_data是校验的数据
def create(self, validated_data):
# 尽量在所有校验规则完毕之后,数据可以直接入库
return models.User.objects.create(**validated_data)
对于Serializer的使用我们了解到了他的基础用法,对于序列化以及反序列化有了一定的改进,下面我们就要讲讲他的子类ModelSerializer,这个类很强大,也是最实用的。
ModelSerializer定义
由于ModelSerializer是Serializer的子类,他拥有Serializer所有的特性,所以本次主要介绍不同之处。通过文章开头的类关系图,我们发现它帮我们实现了create和update方法,当然还有一些其他功能,具体定义如下:
from rest_framework import serializers
class UserDetailModelSerializer(serializers.ModelSerializer):
pass
class UserModelSerializer(serializers.ModelSerializer):
phone = serializers.SerializerMethodField()
id = serializers.IntegerField()
user_detail = UserDetailModelSerializer() # 可以进行关联
gender = serializers.SerializerMethodField()
class Meta:
# 序列化关联的类
model = models.BookModel
# 参与序列化的字段
fields = ('name', 'phone', 'id', 'password')
# fields = "__all__" # 所有字段
# exclude = ("is_delete", "id") # 去除某些字段
# depth = 1 # 关联深度
# 用来反序列化字段 系统校验规则
extra_kwargs = {
'name': {
'required': True,
'min_length': '10',
'error_messages': {
'required': '必填项',
'min_length': '长度不小于10'
}
}
}
def get_gender(self,obj):
pass
def valitade_phone(self,value):
pass
def valitade(self,attrs):
pass
总结:
- 可以通过字段以及字段类型定义
- 在Meta类中定义需要序列化的Model类,以及字段
fields:需要序列化的模型类字段,__all__表示所有exclude:序列化不包含某些字段,不能和fields共用depth:用于关联字段(一般不用)层级深度,例如:用户信息关联用户详情信息,通过该字段在序列化用户信息时,关键的外键也会被自动序列化,而不是一个外键idextra_kwargs:字段校验规则,写法和字段类型参数定义一样
get_xxx:同Serializervalitade_xxx:同Serializervalitade:同Serializer
我们可以发现ModelSerializer基本和Serializer一样,主要是字段定义以及校验的区别,所以我们可以把序列化和反序列化合并在一起
序列化与反序列化整合
- 模型类
from django.db import models
# Create your models here.
class UserModel(models.Model):
GENDER = (
(0, '女'),
(1, '男')
)
username = models.CharField(max_length=64)
phone = models.CharField(max_length=11, null=True, default=None, blank=True)
gender = models.IntegerField(choices=GENDER, default=1)
avatar = models.ImageField(upload_to='avatar', default='avatar/default.jpeg')
class Meta:
db_table = "user"
verbose_name = "用户"
verbose_name_plural = verbose_name
def __str__(self):
return self.username
- 路由
from django.conf.urls import url
from . import views
urlpatterns = [
url(r'^v1/users/$', views.UserAPIView.as_view()),
url(r'^v1/users/(?P<pk>.*)/$', views.UserAPIView.as_view()),
]
- 序列化类
from rest_framework import serializers
from rest_framework.exceptions import ValidationError
from . import models
class UserModelSerializer(ModelSerializer):
gender = serializers.SerializerMethodField()
class Meta:
model = models.User
fields = ('name', 'phone', 'id', 'gender','avatar')
extra_kwargs = {
'id':{
'read_only':True
},
'name': {
'required': True,
'min_length': 1,
'error_messages': {
'required': '必填项',
'min_length': '长度不得小于1位',
}
},
'phone': {
'min_length': 11,
'max_length': 11
}
}
def get_gender(self, obj):
return obj.get_gender_display()
- 视图
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework import status
from . import models, serializers
class UserAPIView(APIView):
def get(self, request, *args, **kwargs):
pk = kwargs.get('pk')
# 单查
if pk:
user = models.UserModel.objects.filter(pk=pk).first()
if user:
serializer = serializers.UserModelSerializer(instance=user)
return Response(data=serializer.data, status=status.HTTP_200_OK)
else:
return Response(data="用户不存在", status=status.HTTP_404_NOT_FOUND)
# 群查
else:
users = models.UserModel.objects.all()
if users:
serializer = serializers.UserModelSerializer(instance=users, many=True)
return Response(data=serializer.data, status=status.HTTP_200_OK)
else:
return Response(data="用户不存在", status=status.HTTP_404_NOT_FOUND)
def post(self, request, *args, **kwargs):
data = request.data
print(data)
print(type(data))
# 单增
if data and isinstance(data, dict):
serializer = serializers.UserModelSerializer(data=data)
if serializer.is_valid():
user = serializer.save()
info = serializers.UserModelSerializer(instance=user).data
return Response(data=info, status=status.HTTP_201_CREATED)
# 群增
elif data and isinstance(data, list):
serializer = serializers.UserModelSerializer(data=data, many=True)
if serializer.is_valid():
users = serializer.save()
info = serializers.UserModelSerializer(instance=users, many=True).data
return Response(data=info, status=status.HTTP_201_CREATED)
return Response(data="参数有误", status=status.HTTP_400_BAD_REQUEST)
def put(self, request, *args, **kwargs):
data = request.data
pk = kwargs.get('pk')
# 单改全部更新
if data and isinstance(data, dict):
user = models.UserModel.objects.filter(pk=pk).first()
serializer = serializers.UserModelSerializer(instance=user,data=data)
if serializer.is_valid():
user = serializer.save()
info = serializers.UserModelSerializer(instance=user).data
return Response(data=info, status=status.HTTP_201_CREATED)
return Response(data="参数有误", status=status.HTTP_400_BAD_REQUEST)
def patch(self, request, *args, **kwargs):
data = request.data
pk = kwargs.get('pk')
# 单改部分更新,主要参数 partial
if data and isinstance(data, dict):
user = models.UserModel.objects.filter(pk=pk).first()
serializer = serializers.UserModelSerializer(instance=user, data=data, partial=True)
if serializer.is_valid():
user = serializer.save()
info = serializers.UserModelSerializer(instance=user).data
return Response(data=info, status=status.HTTP_200_OK)
return Response(data="参数有误", status=status.HTTP_400_BAD_REQUEST)
以上进行了简单的定义,基本实现单查、群查、单增、群增、单个全改、单个局部更改,下面是在视图类使用他们的一些不同之处:
- 单查(get):
serializers.UserModelSerializer(instance=user).data - 群查(get):
serializers.UserModelSerializer(instance=user,many=True).data - 单增(post):
serializers.UserModelSerializer(data=request.data).data - 群增(post):
serializers.UserModelSerializer(data=request.data,many=True).data - 单个全改(put):
serializers.UserModelSerializer(instance=user,data=data) - 单个局部改(patch):
serializers.UserModelSerializer(instance=user, data=data, partial=True)
最后还有一个群局部改、群整体改,需要继承ListSerializer,在类关系图中我们看到你也存在create()和update()方法,但是他的源码并没有update()的代码,而是直接抛出了一个异常:
def update(self, instance, validated_data):
raise NotImplementedError(
"Serializers with many=True do not support multiple update by "
"default, only multiple create. For updates it is unclear how to "
"deal with insertions and deletions. If you need to support "
"multiple update, use a `ListSerializer` class and override "
"`.update()` so you can specify the behavior exactly."
)
所以当我们需要有群改的业务时,就需要重写update()的方法,再此先留一个坑,想要了解可参考这篇博文
相关参考:
https://www.cnblogs.com/wangcuican/p/11691298.html
https://www.cnblogs.com/yaya625202/articles/11080644.html