我们拿一个婚恋网站的数据来做knn模型:
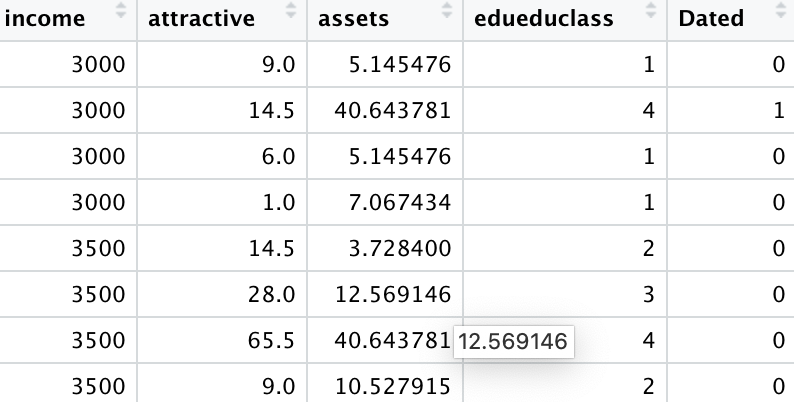
自变量收入、吸引力、资产,教育和是否约会成功。我们利用这些数据做一个小的预测约会是否成功的模型
> ##加载数据集 > Data<-read.csv("date_data2.csv") > #数据需要标准化 > x<-scale(Data[,c(1,2,3,4)]) > y<-Data[,5] > data<-data.frame(cbind(y,x)) > #y需要变为等级变量 > data$y<-as.factor(data$y) > #选择训练集和测试集 > set.seed(123) > sample<-sample(1:nrow(data),length(data$y)*0.7) > train<-data[sample,-1] > train.y<-data[sample,1] > test<-data[-sample,-1] > test.y<-data[-sample,1]
随机选择一个k值
> #使用KNN算法,设定k=10 > library(class) > predict.y<-knn(train = train,test = test,cl=train.y,k=10) > #模型验证,将预测的类别与实际类别对比。 > accuracy<-sum(predict.y==test.y)/length(test.y) > accuracy [1] 0.8666667 > #召回率和精确度 > require(gmodels) > table<-CrossTable(x =test.y, y = predict.y,prop.chisq=FALSE) Cell Contents |-------------------------| | N | | N / Row Total | | N / Col Total | | N / Table Total | |-------------------------| Total Observations in Table: 30 | predict.y test.y | 0 | 1 | Row Total | -------------|-----------|-----------|-----------| 0 | 12 | 2 | 14 | | 0.857 | 0.143 | 0.467 | | 0.857 | 0.125 | | | 0.400 | 0.067 | | -------------|-----------|-----------|-----------| 1 | 2 | 14 | 16 | | 0.125 | 0.875 | 0.533 | | 0.143 | 0.875 | | | 0.067 | 0.467 | | -------------|-----------|-----------|-----------| Column Total | 14 | 16 | 30 | | 0.467 | 0.533 | | -------------|-----------|-----------|-----------| > table$prop.row[2,2]#召回率 [1] 0.875 > table$prop.col[2,2]#精确度 [1] 0.875
其实k值的选择非常关键,下面我们写一个循环来确定较好的k值
> outdata<-data.frame() > for (i in seq(from=1,to=20,by=1)){ + predict.y<-knn(train=train,test = test,cl=train.y,k=i) + accuracy<-sum(predict.y==test.y)/length(test.y) + require(gmodels) + table<-CrossTable(x =test.y,y = predict.y,prop.chisq=FALSE) + out<-data.frame(i,accuracy,table$prop.row[2,2],table$prop.col[2,2]) + outdata<-rbind(outdata,out) + + }
> names(outdata)<-c("n","accuracy","Recall","Precision") > head(outdata) n accuracy Recall Precision 1 1 0.9333333 1.0000 0.8888889 2 2 0.9333333 0.9375 0.9375000 3 3 0.9333333 1.0000 0.8888889 4 4 0.9333333 1.0000 0.8888889 5 5 0.9000000 0.9375 0.8823529 6 6 0.9000000 1.0000 0.8421053
我们可以根据需求选择一个较好的k值,有时需要召回率高,有时需要准确率高。