深度学习之卷积神经网络CNN及tensorflow代码实例
-
什么是卷积?
-
卷积的定义
从数学上讲,卷积就是一种运算,是我们学习高等数学之后,新接触的一种运算,因为涉及到积分、级数,所以看起来觉得很复杂。
我们称
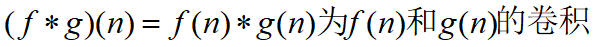
其连续的定义为:
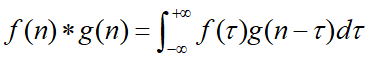
其离散的定义为:
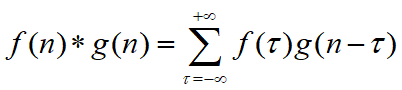
这两个式子有一个共同的特征:
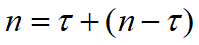
这个特征有什么意义呢?
我们令
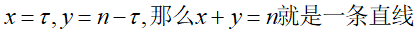 ,当n变化时,只需要平移这条直线
,当n变化时,只需要平移这条直线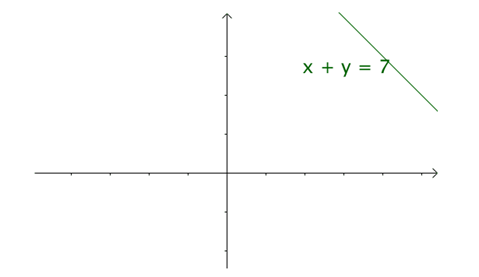
在上面的公式中,
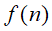 是一个函数,
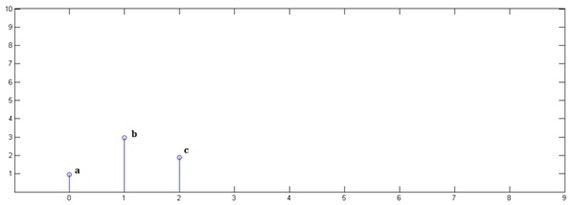
是一个函数,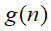 也是一个函数,例如下图所示
也是一个函数,例如下图所示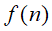 即
即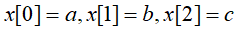
下图
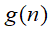 即
即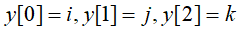
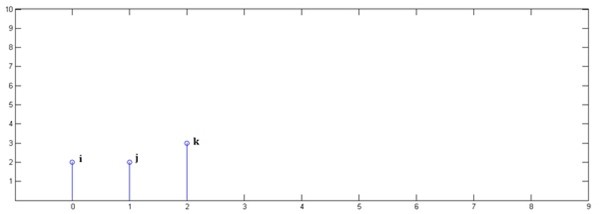
根据卷积公式,求
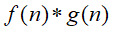 即将
即将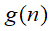 变号为
变号为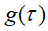 ,然后翻转变成
,然后翻转变成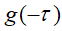 ,若我们计算的卷积值,
,若我们计算的卷积值,当n=0时:
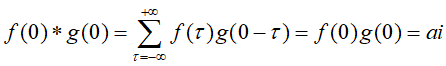
当n=1时:
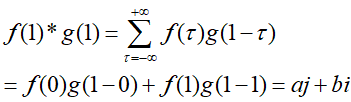
当n=2时:
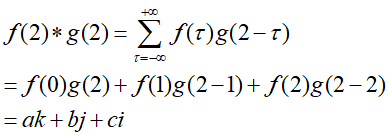
当n=3时:
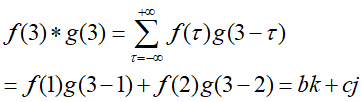
当n=4时:
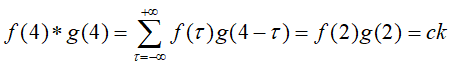
其余为0;
即计算步骤为当固定n值时:变号、翻转、求积、求和。
-
离散卷积的例子
我有两枚骰子:

把这两枚骰子都抛出去:

求两枚骰子点数加起来为4的概率是多少?
这里问题的关键是,两个骰子加起来要等于4,这正是卷积的应用场景。
我们把骰子各个点数出现的概率表示出来:

那么,两枚骰子点数加起来为4的情况有:
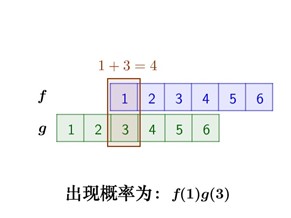
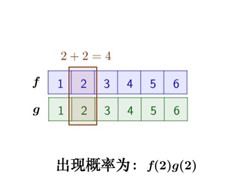
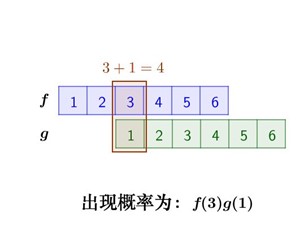
因此,两枚骰子点数加起来为4的概率为:
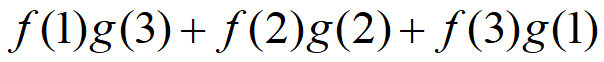
符合卷积的定义。
-
连续卷积的例子:做馒头
楼下早点铺子生意太好了,供不应求,就买了一台机器,不断的生产馒头。
假设馒头的生产速度是
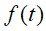 ,那么一天后生产出来的馒头总量为:
,那么一天后生产出来的馒头总量为: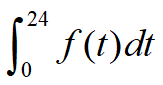
馒头生产出来之后,就会慢慢腐败,假设腐败函数为
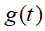 ,比如,10个馒头,24小时会腐败:
,比如,10个馒头,24小时会腐败: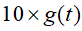 个。
个。想想就知道,第一个小时生产出来的馒头,一天后会经历24小时的腐败,第二个小时生产出来的馒头,一天后会经历23小时的腐败。
如此,我们可以知道,一天后,馒头总共腐败了:
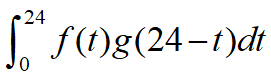 个馒头
个馒头这就是连续卷积的例子。
-
图像处理:卷积可以用来平滑高频区域。
-
-
CNN引入
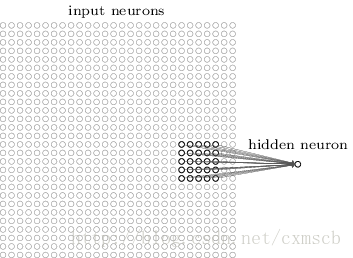
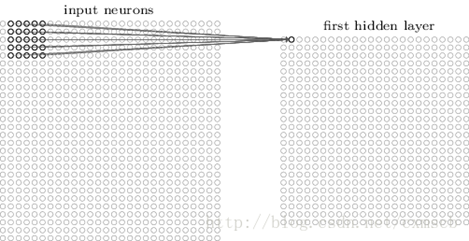
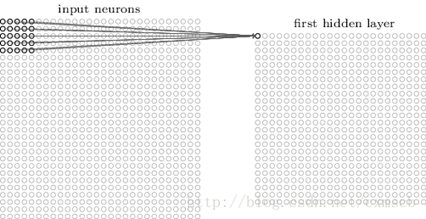
在人工的全连接神经网络中,每相邻两层之间的每个神经元之间都是有边相连的。当输入层的特征维度变得很高时,这时全连接网络"需要训练的参数"就会增大很多,计算速度就会变得很慢,例如一张黑白的28*28的手写数字图片,输入的神经元就有784个,如下图所示:
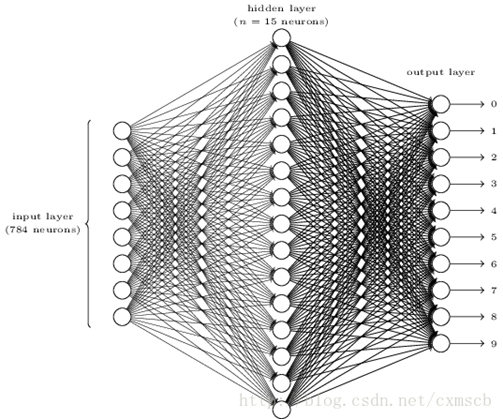
若在中间只使用一层隐藏层,参数
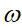 就有28*28*15=11760多个;若输入的是28*28带有颜色的RGB格式的手写数字图片,输入神经元就有28*28*3=2352个,参数
就有28*28*15=11760多个;若输入的是28*28带有颜色的RGB格式的手写数字图片,输入神经元就有28*28*3=2352个,参数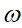 就有28*28*3*15多个。这很容易看出使用全连接神经网络处理图像时"需要训练的参数过多"的问题。
就有28*28*3*15多个。这很容易看出使用全连接神经网络处理图像时"需要训练的参数过多"的问题。而在卷积神经网络(Convolutional Neural Network)中,卷积层的神经元只与前一层的部分神经元节点相连,即它的神经元之间的连接是非全连接的,且同一层中某些神经元之间的连接的权重
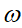 和偏移
和偏移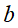 是共享的(是相同的),这样大量地减少了"需要训练的参数的数量"。
是共享的(是相同的),这样大量地减少了"需要训练的参数的数量"。卷积神经网络CNN的结构一般包含这几个层:
-
输入层:用于数据的输入
-
卷积层:使用卷积核进行特征提取和特征映射
-
激励层:由于卷积也是一种线性运算,因此需要增加非线性映射
-
池化层:进行下采样,对特征图稀疏处理,减少数据运算量
-
全连接层:通常在CNN的尾部进行重新拟合,减少特征信息的损失
-
输出层:用于输出结果
当然中间还可以使用一些其他的功能层:
-
归一化层(Batch Normalization):在CNN中对特征的归一化
-
切分层:对某些(图片)数据的进行分区域的单独学习
-
融合层:对独立进行特征学习的分支进行融合
-
-
CNN的层次结构
-
输入层
在CNN的输入层中,(图片)数据输入的格式与全连接神经网络的输入格式(一维向量)不太一样。CNN的输入层的输入格式保留了图片本身的结构。
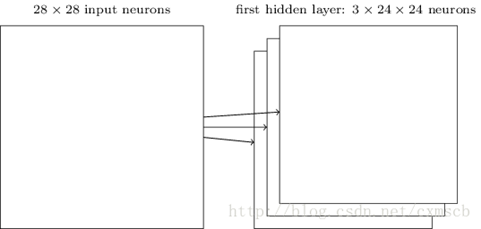
对于黑白的28*28的图片,CNN的输入是一个28*28的二维神经元,如下图所示:

而对于RGB格式的28*28图片,CNN的输入则是一个3*28*28的三维神经元(RGB中每一个颜色通道都有一个28*28的矩阵),如下图所示:

-
卷积层
在卷积层中有几个重要的概念:卷积层就是一个感受视野,它包括局部感受视野和共享权值
-
local receptive fields(感受视野)
-
shared weights(共享权值)
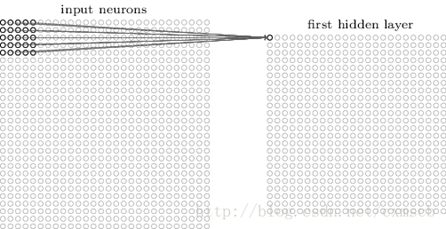
假设输入的是一个28*28的二维神经元,我们定义5*5的一个local receptive fields(感受视野),即隐藏层的神经元与输入层的5*5个神经元相连,这个5*5的区域就称之为Local Receptive Fileds(感受视野),如下图所示:
可类似看作:隐藏层中的神经元具有一个固定大小的感受视野去感受上一层的部分特征。在全连接神经网络中,隐藏层中的神经元的感受视野足够大乃至可以看到上一层的所有特征。
而在卷积神经网络中,隐藏层中的神经元的感受视野比较小,只能看到上一次的部分特征,上一层的其他特征可以通过平移感受视野来得到同一层的其他神经元,由同一层的其他神经元来看:
设移动的步长为1:从左到右扫描,每次移动1格,扫描完之后,再向下一格,再次从左到右扫描。
具体过程如动图所示:
-
可看出,卷积层的神经元是只与前一层的部分神经元节点相连,每一条相连的线对应一个权重
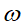 。
。一个感受视野带有一个卷积核,我们将感受视野中的权重
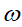 矩阵成为卷积核;将感受矩阵对输入的扫描间隔称为步长(stride);当步长比较大时(stride>1),为了扫描到边缘的一些特征,感受视野可能会"出界",这时需要对边界扩充(pad),边界扩充可以设为0或其他值。步长和边界扩充值的大小由用户来定义。
矩阵成为卷积核;将感受矩阵对输入的扫描间隔称为步长(stride);当步长比较大时(stride>1),为了扫描到边缘的一些特征,感受视野可能会"出界",这时需要对边界扩充(pad),边界扩充可以设为0或其他值。步长和边界扩充值的大小由用户来定义。卷积核的大小由用户来定义,即定义的感受视野的大小;卷积核的权重矩阵的值,便是卷积神经网络的参数,为了有一个偏移项,卷积核可附带一个偏移项b,它们的初值可以随机来生成,可通过训练进行变化。
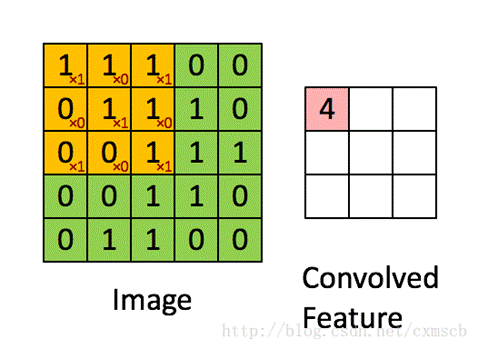
因此,感受视野扫描时可以计算出下一层神经元的值为:
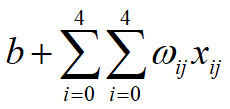
对下一层的所有神经元来说,它们从不同的位置去探测了上一层神经元的特征。我们将通过一个带有卷积核的感受视野扫描生成的下一层神经元矩阵称为一个feature map(特征映射图),如下图的右边便是一个feature map:
因此在同一个feature map上的神经元使用的卷积核是相同的,因此这些神经元shared weights,共享卷积核中的权值和附带的偏移。一个feature map对应一个卷积核,若我们使用3个不同的卷积核,可以输出3个feature map:(上图中,感受视野:5*5,步长stride:1)
因此在CNN的卷积层,我们需要训练的参数大大地减少到(5*5+1)*3=78个。卷积层只包含感受视野中的神经元和共享权值。
假设输入的是28*28的RGB图片,即输入的是一个3*28*28的二维神经元,这时卷积核的大小不只用长和宽来表示,还有深度,感受视野也对应的有了深度,如下图所示:
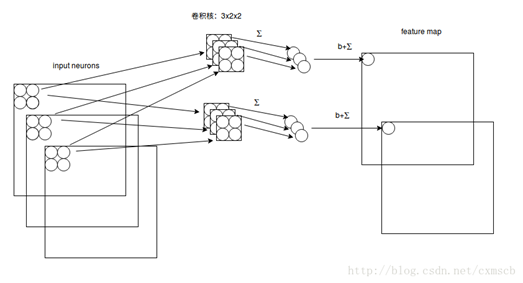
由图可知:感受视野:3*2*2;卷积核:3*2*2;深度为3;下一层的神经元的值为:
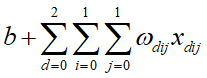 ,卷积核的深度和感受视野的深度相同,都由输入数据来决定,长度可由自己来设定,数目也可以由自己来设定,一个卷积核依然对应一个feature map(特征映射)。
,卷积核的深度和感受视野的深度相同,都由输入数据来决定,长度可由自己来设定,数目也可以由自己来设定,一个卷积核依然对应一个feature map(特征映射)。 -
注:"stride=1"步长为1表示在长和宽上的移动间隔都为1。
-
激励层
激励层主要对卷积层的输出进行一个非线性映射,因为卷积层的计算还是一种线性计算,使用的激励函数一般为ReLu函数:
修正线性单元(Rectified linear unit,ReLU)
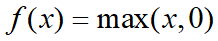

卷积层和激励层通常合并在一起称为"卷积层"。
-
池化层
当输入经过卷积层时,若感受视野比较小,步长stride比较小,得到的feature map(特征映射图)还是比较大,可以通过池化层来对每一个feature map进行降维操作,输出的深度还是不变的,依然为feature map的个数。
池化层也有一个"池化视野"来对feature map矩阵进行扫描,对"池化视野"中的矩阵值进行计算,一般有两种计算方式:
-
Max pooling:取"池化视野"矩阵中的最大值
-
Average pooling :取"池化视野"矩阵中的平均值
扫描的过程同样的会涉及到步长stride,扫描方式同卷积层一样,先从左到右扫描,结束则向下移动步长大小,再从左到右扫描。如下图示例所示:当计算方式为max pooling:取"池化视野"矩阵中的最大值,步长stride为2时:
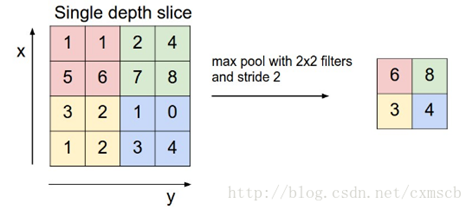
其中"池化视野"filter:2*2;步长stride:2。(注意:"池化视野"为个人叫法)
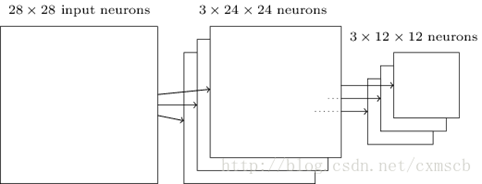
最后可将2个24*24的feature map"下采样"得到3个12*12的特征矩阵。
缩小图像(或称为下采样(subsampled)或降采样(downsampled))的主要目的有两个:1、使得图像符合显示区域的大小;2、生成对应图像的缩略图。
放大图像(或称为上采样(upsampling)或图像插值(interpolating))的主要目的是放大原图像,从而可以显示在更高分辨率的显示设备上。
-
-
归一化层
-
Batch Normalization
Batch Normalization(批量归一化)实现了在神经网络层的中间进行预处理的操作,即在上一层的输入归一化处理后再进入网络的下一层,这样可以有效地防止"梯度弥散",加速网络训练。
Batch Normalization具体的算法如下图所示:

每次训练时,取batch_size大小的样本进行训练,在BN层中,将一个神经元看作一个特征,batch_size个样本在某个特征维度会有batch_size个值,然后在每个神经元
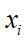 维度上计算这些样本的均值和方差,通过公式得
维度上计算这些样本的均值和方差,通过公式得 ,再通过参数
,再通过参数 进行线性映射得到每个神经元对应的输出
进行线性映射得到每个神经元对应的输出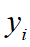 。在BN层中,可以看出每一个神经元维度上,都会有一个参数
。在BN层中,可以看出每一个神经元维度上,都会有一个参数 ,它们同权重
,它们同权重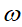 一样可以通过训练进行优化。
一样可以通过训练进行优化。在卷积神经网络中进行批量归一化时,一般对未进行ReLu激活的feature map进行批量归一化,输出后再作为激励层的输入,可达到调整激励函数偏导的作用。
一种做法是将feature map中的神经元作为特征维度,参数
 的数量和则等于
的数量和则等于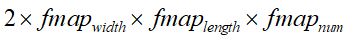 ,这样做的话参数的数量会变得很多;
,这样做的话参数的数量会变得很多;另一种做法是把一个feature map看做一个特征维度,一个feature map上的神经元共享这个feature map的参数
 ,参数
,参数 的数量和则等于
的数量和则等于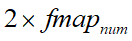 ,计算均值和方差则在batch_size个训练样本在每一个feature map维度上的均值和方差。
,计算均值和方差则在batch_size个训练样本在每一个feature map维度上的均值和方差。注意:
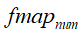 指的是一个样本的feature map的数量,feature map跟神经元一样也有一定的排列顺序。
指的是一个样本的feature map的数量,feature map跟神经元一样也有一定的排列顺序。Batch Normalization算法的训练过程和测试过程的区别
在训练过程中,我们每次都会将batch_size数目大小的训练样本放入CNN网络中进行训练,在BN层中自然可以得到计算输出所需要的均值和方差;
而在测试过程中,我们往往只会向CNN网络中输入一个测试样本,这时在BN层计算的均值和方差会均为0,因为只有一个样本输入,因此BN层的输入也会出现很大的问题,从而导致CNN网络输出的错误。所以在测试过程中,我们需要借助训练集中所有样本在BN层归一化时每个维度上的均值和方差,当然为了计算方便,我们可以在 batch_num 次训练过程中,将每一次在BN层归一化时每个维度上的均值和方差进行相加,最后再进行求一次均值即可。
-
Local Response Normalization近邻归一化
近邻归一化(Local Response Normalization)的归一化方法主要发生在不同的相邻的卷积核(经过ReLu之后)的输出之间,即输入是发生在不同的经过ReLu之后的 feature map 中。
LRN的公式如下:
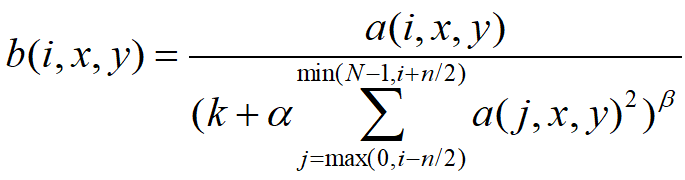
其中:
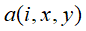 表示第i个卷积核的输出(经过ReLu层)的feature map上的
表示第i个卷积核的输出(经过ReLu层)的feature map上的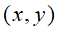 位置上的值。
位置上的值。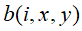 表示
表示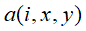 经过LRN后的输出。
经过LRN后的输出。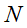 表示卷积核的数量,即输入的feature map的个数。
表示卷积核的数量,即输入的feature map的个数。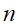 表示近邻的卷积核(或feature map)个数,由自己来决定。
表示近邻的卷积核(或feature map)个数,由自己来决定。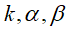 是超参数,由用户自己调整或决定。
是超参数,由用户自己调整或决定。与BN的区别:BN依据mini batch的数据,近邻归一仅需要自己来决定,BN训练中有学习参数;BN归一化主要发生在不同的样本之间,LRN归一化主要发生在不同的卷积核的输出之间。
-
-
切分层
在一些应用中,需要对图片进行切割,独立地对某一部分区域进行单独学习。这样可以对特定部分进行通过调整感受视野进行力度更大的学习。
-
融合层
融合层可以对切分层进行融合,也可以对不同大小的卷积核学习到的特征进行融合。
例如在GoogleLeNet 中,使用多种分辨率的卷积核对目标特征进行学习,通过 padding 使得每一个 feature map 的长宽都一致,之后再将多个 feature map 在深度上拼接在一起:
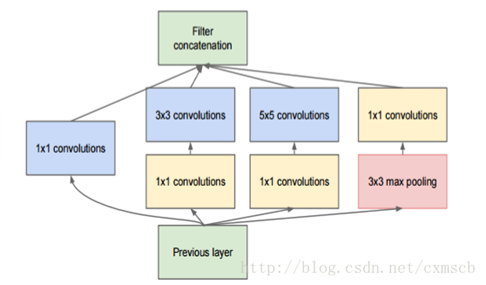
融合的方法有几种,一种是特征矩阵之间的拼接级联,另一种是在特征矩阵进行运算 (+,−,x,max,conv)。
-
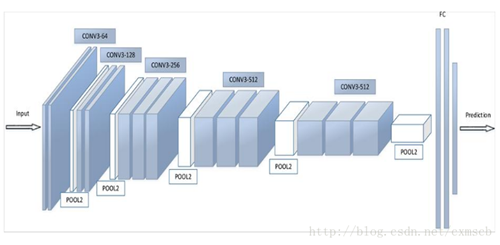
全连接层和输出层
全连接层主要对特征进行重新拟合,减少特征信息的丢失;输出层主要准备做好最后目标结果的输出。例如VGG的结构图,如下图所示:
-
典型的卷积神经网络
卷积神经网络是一个多层的神经网络,每层由多个二维平面组成,而每个平面由多个独立神经元组成。
图:卷积神经网络的概念示范:输入图像通过和三个可训练的滤波器和可加偏置进行卷积,滤波过程如图一,卷积后在C1层产生三个特征映射图,然后特征映射图中每组的四个像素再进行求和,加权值,加偏置,通过一个Sigmoid函数得到三个S2层的特征映射图。这些映射图再进过滤波得到C3层。这个层级结构再和S2一样产生S4。最终,这些像素值被光栅化,并连接成一个向量输入到传统的神经网络,得到输出。
每个层有多个Feature Map,每个Feature Map通过一种卷积滤波器提取输入的一种特征,然后每个Feature Map有多个神经元。
CNN一个牛逼的地方就在于通过感受野和权值共享减少了神经网络需要训练的参数的个数,所谓权值共享就是同一个Feature Map中神经元权值共享,该Feature Map中的所有神经元使用同一个权值。因此参数个数与神经元的个数无关,只与卷积核的大小及Feature Map的个数相关。但是共有多少个连接个数就与神经元的个数相关了,神经元的个数也就是特征图的大小。
-
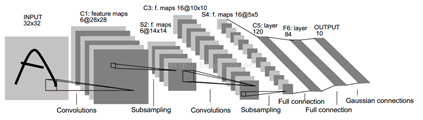
LeNet-5模型
-
LeNet-5各层参数及连接个数
-
下面以最经典的LeNet-5例子来逐层分析各层的参数及连接个数。
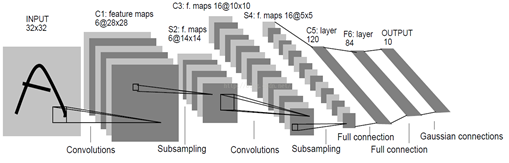
-
C1层是一个卷积层,
由6个特征映射图feature map构成,每个feature map都有一个卷积核和共享权值矩阵。特征图中每个神经元与输入为5*5的领域相连。特征图的大小为28*28(为什么是28*28呢?这样能防止输入的连接掉到边界之外(32-5+1=28),如果原图是一个 n*n的图片,我们用m*m的感受视野对其进行卷积,则得到像素为
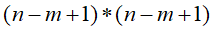 特征映射图为),C1有156个可训练参数(每个滤波器5*5个unit参数和一个bias参数,一共得到6个特征映射图,也就是需要6个滤波器,所以共有
特征映射图为),C1有156个可训练参数(每个滤波器5*5个unit参数和一个bias参数,一共得到6个特征映射图,也就是需要6个滤波器,所以共有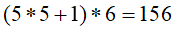 个参数),所以C1层与输入层的连接的个数就是(C1层的每个神经元通过这156个参数映射到的输入层)。
个参数),所以C1层与输入层的连接的个数就是(C1层的每个神经元通过这156个参数映射到的输入层)。下图1显示了一输入层和感受视野卷积成下一层节点矩阵的其中一个节点的连接方式,即先使用输入层的一个5*5的区域与感受视野卷积,然后在加上偏置bias就得到了特征映射图feature map。
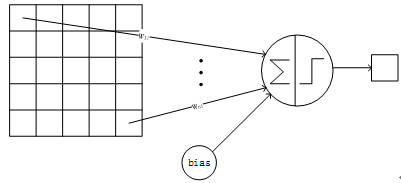
图1 一个卷积节点的连接方式
下图2显示了卷积神经网络连接与矩阵卷积的对应关系:
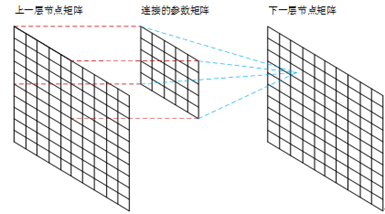
图2 卷积神经网络连接与矩阵卷积的对应关系
-
S2层是一个下采样层(池化层),
有6个14*14的特征图(为什么是14*14的特征图呢?因为特征图中的每个单元与C1中相对应特征图的2*2邻域相连接。S2层每个单元的输入相加,乘以一个可训练参数,再加上一个可训练偏置,每个单元的2*2感受视野并不重叠,因此S2中每个特征图的大小是C1中特征图大小的1/4(行和列各1/2),所以S2层有12个(6*(1个可训练+1个可训练偏置))个可训练参数和(14*14)*(2*2+1)*6=5880个连接。
注意:可训练参数与连接不能混谈,连接与神经元和感受视野有关
在下采样层这里使用的是2*2的"池化视野",采用均值采样(CNN的池化(图像下采样)方法很多:Mean pooling(均值采样)、Max pooling(最大值采样)、Overlapping (重叠采样)、L2 pooling(均方采样)、Local Contrast Normalization(归一化采样)、Stochasticpooling(随即采样)、Def-pooling(形变约束采样)。其中最经典的是最大池化)在这一层可训练的参数只有两个:下图3为一个下采样节点的连接方式:
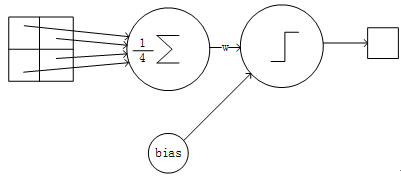
图3 一个下采样节点的连接方式
-
C3层也是一个卷积层
它同样通过5x5的卷积核去卷积层S2,然后得到的特征map就只有10x10个神经元,但是它有16种不同的卷积核,所以就存在16个特征map了。 C3中的每个特征图由S2中所有6个或者几个特征的map组合而成。为什么不把S2中的每个特征图连接到每个C2的特征图呢?原因有2点。
-
不完全的连接机制将连接的数量保持在合理的范围内。
-
也是最重要的,其破坏了网络的对称性。由于不同的特征有不同的输入,所以迫使他们抽取不同的特征(希望是互补的)。
例如,存在的一个方式是:C3的前6个特征图以S2中3个相邻的特征图子集为输入。接下来6个特征图以S2中4个相邻特征图子集为输入。然后的3个以不相邻的4个特征图子集为输入。最后一个将S2中所有特征图为输入。这样C3层有1516(6*(3*25+1)+6*(4*25+1)+3*(4*25+1)+(25*6+1)=1516)个可训练参数和151600
(10*10*1516=151600)个连接。
下图4为一种卷积方式:
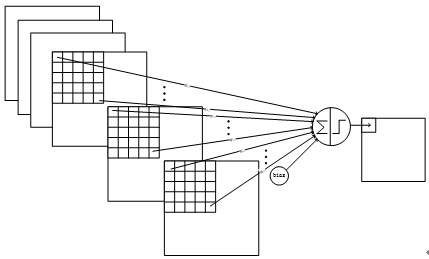
图4 C3与S2中前3个图相连的卷积结构
这种不对称的组合连接的方式有利于提取多种组合特征
-
-
S4层是一个下采样层,
由16个5*5大小的特征图构成。特征图中的每个单元与C3中相应特征图的2*2邻域相连接,跟C1和S2之间的连接一样。S4层有32个可训练参数(每个特征图1个因子和一个偏置16*(1+1)=32)和2000(16*(2*2+1)*5*5=2000)个连接
-
C5层是一个卷积层,
有120个特征图。每个单元与S4层的全部16个单元的5*5邻域相连。由于S4层特征图的大小也为5*5(同滤波器一样),故C5特征图的大小为1*1(5-5+1=1):这构成了S4和C5之间的全连接。之所以仍将C5标示为卷积层而非全相联层,是因为如果LeNet-5的输入变大,而其他的保持不变,那么此时特征图的维数就会比1*1大。C5层有48120(120*(16*5*5+1)=48120由于与全部16个单元相连,故只加一个偏置)个可训练连接。
下图5为C5层的网络结构:
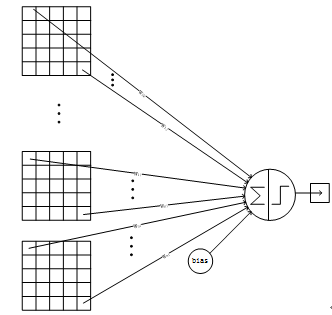
图5 C5层的网络结构
-
F6层有84个单元
(之所以选这个数字的原因来自于输出层的设计),与C5层全相连。有10164(84*(120*(1*1)+1)=10164)个可训练参数。如同经典神经网络,F6层计算输入向量和权重向量之间的点积,再加上一个偏置。然后将其传递给sigmoid函数产生单元i的一个状态。

图6 编码的比特图
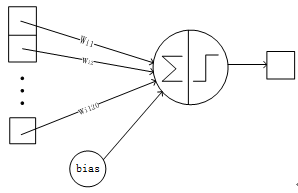
F6层的连接方式
-
最后,输出层
由欧式径向基函数(Euclidean Radial Basis Function)单元组成,每类一个单元,每个有84个输入。
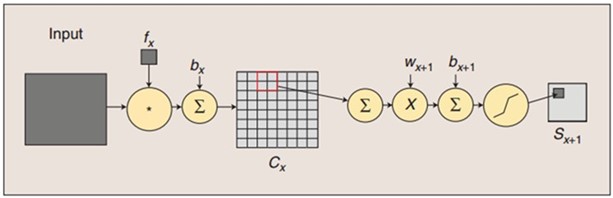
图:卷积和子采样过程:卷积过程包括:用一个可训练的滤波器fx去卷积一个输入的图像(第一阶段是输入的图像,后面的阶段就是卷积特征map了),然后加一个偏置bx,得到卷积层Cx。子采样过程包括:每邻域四个像素求和变为一个像素,然后通过标量Wx+1加权,再增加偏置bx+1,然后通过一个sigmoid激活函数,产生一个大概缩小四倍的特征映射图Sx+1。
-
AlexNet模型
-
局限性
早在1989年,Yann LeCun(现纽约大学教授)和他的同事们就发表了卷积神经网络(Convolution NeuralNetworks,简称CNN),在很长时间里,CNN虽然在小规模的问题上,如手写数字,取得过当时世界最好结果,但一直没有取得巨大成功。这主要原因是,CNN在大规模图像上效果不好,比如像素很多的自然图片内容理解上,所以没有得到计算机视觉领域的足够重视。
这个惊人的结果为什么在之前没有发生?原因当然包括算法的提升,比如dropout等防止过拟合技术,但最重要的是,GPU带来的计算能力提升和更多的训练数据。
①首先,我们先回顾一下LeNet-5网络
-
为什么F6中神经元是84维?
-
②
-
-
-
VGGNet模型
-
GoogleNet模型
-
ResNet模型
-
-
Tensorflow代码
代码后期贴!
-
详细解释CNN卷积网络各层的参数和链接个数的计算
本文转自https://www.leiphone.com/news/201705/HH3BbIfCqAtOAMbu.html