由于最近工作的关系接触到了微博数据分析这一块,觉得挺有意思的,想先练习将微博的数据抓取下来练习看看。
目标是将微博的内容和作者这两个数据储存在数据库内,由于数据量不是很大,先暂时用MySQL,如果以后要大量储存再考虑使用Hive或是HBASE。
然后代码使用Python3,因为写起来比较方便。下面就是step by step的教学了。
1、设定微博开发平台
要调取微博的数据很简单,首先登入微博开放平台,注册一个应用,取得APP_KEY和APP_SECRET,然后再将授权回调页和取消授权回调页改成
https://api.weibo.com/oauth2/default.html
基本上微博的前置作业就完成了。
2、MySQL创建数据库
打开cdm,输入mysql -u root -p,进到mysql后,输入create DATABASE weibo; 创建一个新的数据库weibo,再输入use weibo进入到weibo数据库内。
再输入下面的代码,创建一个新的表,表里面只有两列,一个储存名字,一个储存内容,如果想设定default id也行,不过我这个没必要,然后varchar的长度我故意设大一点以免输入发生问题
实际上应该不用这么多

3、查看接口
首先进入微博开放平台看一下他的API文档,主要是看一下他返回的格式
https://open.weibo.com/wiki/Business_API%E6%96%87%E6%A1%A3#.E6.95.B0.E6.8D.AEAPI

找出我要的数据,然后记录下来
4、编写代码
代码其实挺简单的,先import一些需要的包进来,sinaweibopy3是我在网上找到的一个微博工具包,可以上github下载
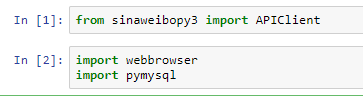
然后再利用sinaweibopy3的模块向微博接口传送授权请求,接着就会打开一个Oauth2的授权页面(关于Oauth2的授权原理接口文档有写),将url后面code=“xxxxx”的地方复制下来

将网页后面给的code输入,并且取得access token 和 expire in,接着再利用这两个向接口请求数据,到这边就差不多大功告成了。

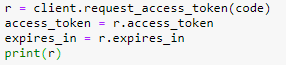

将请求到的数据先打印出来看看,返回的数据格式应该是跟接口文档里的一样。
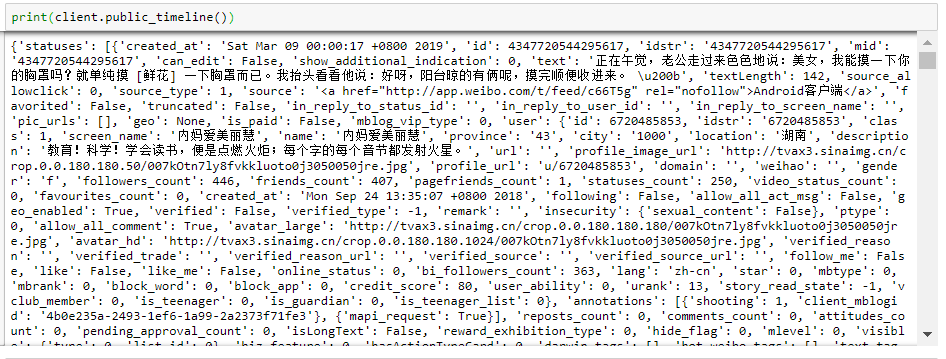
4、储存数据
由于我们只要作者跟他的内容,所以要先把需要的数据找出来,从接口文档可以找出来我要的数据位置,先打印出来检查看看。
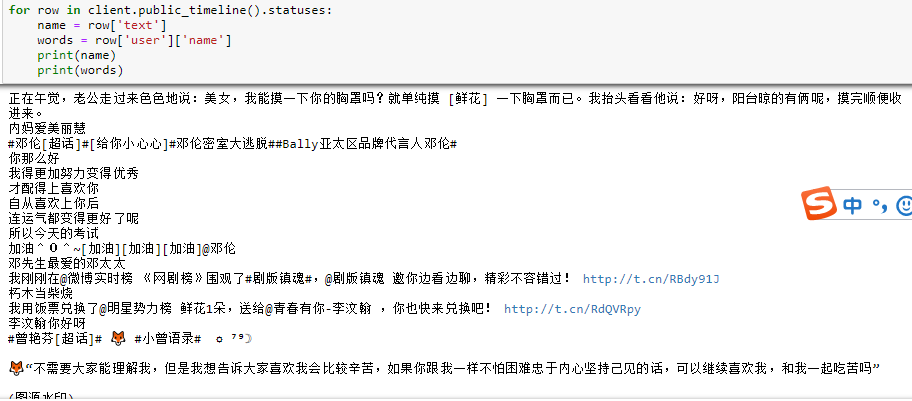
看起来是没问题的,接着就是写到MySQL库里面

然后到MySQL里面查看数据,可以看到微博的数据成功的写进了数据库内(我后来发现我把作者跟内容搞反了,不过不影响这次的练习)

接下来的想法是抓取更多维度的数据,然后用NLTK之类的对文本进行分析,做出简单的报表,不过这个工作量应该挺大的,不知道有没有时间来搞。