题目:Implement Trie (Prefix Tree)
实现字典树。
什么是字典树?
Trie树,又叫字典树、前缀树(Prefix Tree)、单词查找树 或 键树,是一种多叉树结构。如下图:
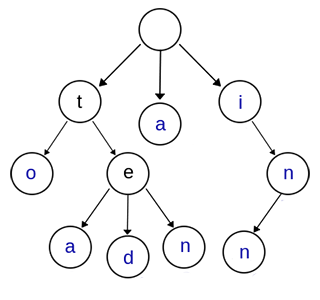
上图是一棵Trie树,表示了关键字集合{“a”, “to”, “tea”, “ted”, “ten”, “i”, “in”, “inn”} 。从上图可以归纳出Trie树的基本性质:
- 根节点不包含字符,除根节点外的每一个子节点都包含一个字符。
- 从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串。
- 每个节点的所有子节点包含的字符互不相同。
通常在实现的时候,会在节点结构中设置一个标志,用来标记该结点处是否构成一个单词(关键字)。
可以看出,Trie树的关键字一般都是字符串,而且Trie树把每个关键字保存在一条路径上,而不是一个结点中。另外,两个有公共前缀的关键字,在Trie树中前缀部分的路径相同,所以Trie树又叫做前缀树(Prefix Tree)。
更详细的内容请参照:http://www.cnblogs.com/yeqluofwupheng/p/6793516.html
树的节点结构如下:
struct TrieNode{ int count = 0;//该节点代表的单词的个数,由此判断当前节点是否构成一个单词 vector<TrieNode*> children;//26个小写字母,以它们的值为下标 };
上面count用来记录访问次数,同时也可以标志从根节点到当前节点的字符串是否为一个单词。
第一次插入的时候讲最后一个字母对应的树节点的count设为1.
下面包括void insert(string word);bool search(string word);bool startsWith(string prefix);三个操作。
class Trie { public: /** Initialize your data structure here. */ Trie() { root = new TrieNode(); root->count = 0; for (size_t i = 0; i < 26; i++) { root->children.push_back(nullptr); } } /** Inserts a word into the trie. */ void insert(string word) { auto it = word.cbegin(); auto p = root; while (it != word.cend()){ auto pos = *it - 'a'; if (!p->children.at(pos)){//创建字典树节点 TrieNode* newChild = new TrieNode(); newChild->count = 0; for (size_t i = 0; i < 26; i++) { newChild->children.push_back(nullptr); } p->children.at(pos) = newChild;//连接 } p = p->children.at(pos); ++it; } ++(p->count);//增加他的访问,p是最后的节点 } /** Returns if the word is in the trie. */ bool search(string word) { auto it = word.cbegin(); auto p = root; while (it != word.cend()){//正常退出表示找到了该单词的末尾位置 auto pos = *it - 'a'; if (!p->children.at(pos))return false;//不能构成单词 p = p->children.at(pos); ++it; } if (p->count)return true;//count>0表示当前节点构成一个单词 return false; } /** Returns if there is any word in the trie that starts with the given prefix. */ bool startsWith(string prefix) { auto it = prefix.cbegin(); auto p = root; while (it != prefix.cend()){//正常退出表示找到了该单词的末尾位置 auto pos = *it - 'a'; if (!p->children.at(pos))return false;//不能构成单词 p = p->children.at(pos); ++it; } return true; } private: struct TrieNode{ int count = 0;//该节点代表的单词的个数,由此判断当前节点是否构成一个单词 vector<TrieNode*> children;//26个小写字母,以它们的值为下标 }; TrieNode* root; };
题目:Add and Search Word - Data structure design
字典树的简单应用,在查找上增加了'.'的正则表达式;注意题目中只有一个'.',而没有省略号,不要搞错了。
基本思想就是使用字典树,树节点结构,创建,添加和上面都是一样的。主要在查找上有一点区别。
class WordDictionary { public: /** Initialize your data structure here. */ WordDictionary() { dict = new TrieNode(); dict->isKey = false; for (size_t i = 0; i < 26; i++) { dict->children.push_back(nullptr); } } /** Adds a word into the data structure. */ void addWord(string word) { auto it = word.cbegin(); auto p = dict; while (it != word.cend()){ auto pos = *it - 'a'; if (!p->children.at(pos)){ TrieNode* newChild = new TrieNode(); newChild->isKey = false; for (size_t i = 0; i < 26; i++) { newChild->children.push_back(nullptr); } p->children.at(pos) = newChild; } p = p->children.at(pos); ++it; } p->isKey = true; } /** Returns if the word is in the data structure. A word could contain the dot character '.' to represent any one letter. */ bool search(string word) { return query(word, dict); } private: struct TrieNode{ bool isKey = false;//标记从树根到断当前节点是否构成一个单词 vector<TrieNode*> children;//26个小写字母,以它们的值为下标 }; TrieNode* dict; bool query(string word, TrieNode* root){ if (!root)return false; auto p = root; for (size_t i = 0; i < word.size(); ++i){//正常退出表示找到了该单词的末尾位置 if (word[i] == '.'){//一个点 string sub = i == word.size() - 1 ? word.substr(i, 0) : word.substr(i + 1, word.size() - 1 - i); for (size_t i = 0; i < p->children.size(); i++){ if (query(sub, p->children.at(i)))return true;//找到符合的单词 } return false; } auto pos = word[i] - 'a'; if (!p->children.at(pos))return false;//不能构成单词 p = p->children.at(pos); } if (p->isKey)return true;//count>0表示当前节点构成一个单词 return false; } };
bool search(string word)需要使用递归实现,所以有了query()的实现。主要就是当遇到'.'的时候循环递归判断当前树节点的每一个子节点。
注意:
1.空串的情况:string sub = i == word.size() - 1 ? word.substr(i, 0) : word.substr(i + 1, word.size() - 1 - i);此时单词的最后一个字符是'.',substr中不能传i+1;
2.空节点的情况:if (!root)return false;
题目:Word Search II
给定一个字符数组和一组单词,将单词的每个字母在字符数组中邻接(单词前一个字母和后一个字母是在前后左右某一个方向上相邻)的单词输出。
例如
Given words = ["oath","pea","eat","rain"] and board =
[ ['o','a','a','n'], ['e','t','a','e'], ['i','h','k','r'], ['i','f','l','v'] ]
Return ["eat","oath"].
思路:
使用Trie树,将单词放入空的Trie树中,然后遍历字符数组,递归查找,每当找到Trie树的单词节点(可以组成一个单词的节点),就将单词放入数组中,最后返回该数组即可。
实现如下:
Trie树的构造方式:
class TrieNode{ public: int count;//该节点代表的单词的个数,由此判断当前节点是否构成一个单词 vector<TrieNode*> children;//26个小写字母,以它们的值为下标 TrieNode() :count(0){ children = vector<TrieNode*>(26, nullptr); } }; class Trie { public: /** Initialize your data structure here. */ Trie() { root = new TrieNode(); } Trie(vector<string>& words) { root = new TrieNode(); for (size_t i = 0; i < words.size(); ++i) { insert(words.at(i)); } } TrieNode* getRoot(){ return root; } /** Inserts a word into the trie. */ void insert(string word) { auto it = word.cbegin(); auto p = root; while (it != word.cend()){ auto pos = *it - 'a'; if (!p->children.at(pos)){//创建字典树节点 TrieNode* newChild = new TrieNode(); newChild->count = 0; for (size_t i = 0; i < 26; i++) { newChild->children.push_back(nullptr); } p->children.at(pos) = newChild;//连接 } p = p->children.at(pos); ++it; } p->count = 1;//增加他的访问,p是最后的节点 } /** Returns if the word is in the trie. */ bool search(string word) { auto it = word.cbegin(); auto p = root; while (it != word.cend()){//正常退出表示找到了该单词的末尾位置 auto pos = *it - 'a'; if (!p->children.at(pos))return false;//不能构成单词 p = p->children.at(pos); ++it; } if (p->count)return true;//count>0表示当前节点构成一个单词 return false; } /** Returns if there is any word in the trie that starts with the given prefix. */ bool startsWith(string prefix) { auto it = prefix.cbegin(); auto p = root; while (it != prefix.cend()){//正常退出表示找到了该单词的末尾位置 auto pos = *it - 'a'; if (!p->children.at(pos))return false;//不能构成单词 p = p->children.at(pos); ++it; } return true; } private: friend class TrieNode;//不能丢,否则会报“不能将TrieNode*类型的值分配到TrieNode*类型的实体”的错误 TrieNode* root; };
这里完全使用C++的语法实现,注意Trie中friend class TrieNode;不能少;
其他和上面类似,不再赘述。
vector<string> LeetCode::findWords(vector<vector<char>>& board, vector<string>& words){ Trie tree(words); set<string> result;//防止添加重复的单词 for (size_t i = 0; i < board.size(); ++i){ for (size_t j = 0; j < board.at(0).size(); ++j){ findWords(board, i, j, tree.getRoot(), string(""), result); } } vector<string> strs; for each (auto s in result){ strs.push_back(s); } return strs; } void LeetCode::findWords(vector<vector<char>>& board, int i, int j, TrieNode* root, string& word, set<string>& result){ if (i < 0 || i >= board.size() || j < 0 || j >= board.at(0).size() || board.at(i).at(j) == ' ')return;//越界返回 TrieNode* p = root->children.at(board.at(i).at(j) - 'a'); if (p){ word += board.at(i).at(j); if (p->count)result.insert(word);//找到一个单词 char ch = board.at(i).at(j); board.at(i).at(j) = ' ';//一个字符不能重复使用 findWords(board, i - 1, j, p, word, result);//左边 findWords(board, i, j - 1, p, word, result);//下边 findWords(board, i + 1, j, p, word, result);//右边 findWords(board, i, j + 1, p, word, result);//上边 board.at(i).at(j) = ch; word.pop_back(); } }
注意:
1.单词的回溯
word.pop_back();
2.避免字符数组中字符的重复使用
board.at(i).at(j) = ' ';//一个字符不能重复使用
上面为了避免重复的单词,使用了set容器,实际上因为有Trie树中count字段代表频度,可以使用它来避免重复单词。
vector<string> findWords(vector<vector<char>>& board, vector<string>& words) { Trie tree(words); vector<string> result;//防止添加重复的单词 string word; for (size_t i = 0; i < board.size(); ++i){ for (size_t j = 0; j < board.at(0).size(); ++j){ findWords(board, i, j, tree.getRoot(), word, result); } } return result; } void findWords(vector<vector<char>>& board, int i, int j, TrieNode* root, string& word, vector<string>& result){ if (i < 0 || i >= board.size() || j < 0 || j >= board.at(0).size() || board.at(i).at(j) == ' ')return;//越界返回 TrieNode* p = root->children.at(board.at(i).at(j) - 'a'); if (p){ word += board.at(i).at(j); if (p->count == 1){//初次(除了创建树的时候)访问时,添加 result.push_back(word);//找到一个单词 p->count += 1;//访问过一次频度加一 } char ch = board.at(i).at(j); board.at(i).at(j) = ' ';//一个字符不能重复使用 findWords(board, i - 1, j, p, word, result);//左边 findWords(board, i, j - 1, p, word, result);//下边 findWords(board, i + 1, j, p, word, result);//右边 findWords(board, i, j + 1, p, word, result);//上边 board.at(i).at(j) = ch; word.pop_back(); } }