参考自:
https://zhuanlan.zhihu.com/p/22252270
常见的优化方法有如下几种:SGD,Adagrad,Adadelta,Adam,Adamax,Nadam
1. SGD
SGD就是每一次迭代计算mini-batch的梯度,然后对参数进行更新,是最常见的优化方法了。即:
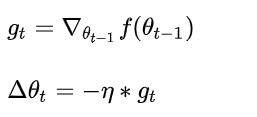

缺点:
1. 选择合适的learning rate 较难,对所有参数更新使用同样的learning rate。
2. 容易收敛到局部最优,并且在某些情况下可能被困在鞍点。
2. Momentum
momentum是模拟物理动量的概念,积累之前的动量来替代真正的梯度。公式如下:

其中 u是动量因子
特点:
下降初期时,使用上一次参数更新,下降方向一致,乘上较大的动量因子能够进行很好的加速
下降中后期时,在局部最小值来回震荡的时候,梯度接近0,动量因子使得更新幅度增大,跳出陷阱
在梯度改变方向的时候,动量因子能够减少更新 总而言之,momentum项能够在相关方向加速SGD,抑制振荡,从而加快收敛
3. Adagrad、Adadelta、RMSprop
这三者都是对学习率加以调整的优化方法。
4. Adam
Adam(Adaptive Moment Estimation)本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。