1结构介绍
是一个seq2seq的任务模型,将输入的时间序列转化为输出的时间序列。
有encoder和decoder两个模块,分别用于编码和解码,结合时是将编码的最后一个输出 当做 解码的第一个模块的输入
encoder模块有两个操作: self-attention、feed-forward
decoder模块有三个操作:self-attention、encoder-decoder-attention、feed-forward
两种attention用的都是 multi-head-attention
2 enbedding
enbedding 操作不是简单地enbedding,而是加入了位置信息的enbedding,称之为position-enbedding,
3.multi-head-attention
3.1 attention 简单回顾
attention 理解为计算相关程度;
进行如下表述:表示为将query 和k-v pairs 映射到输出上其中query,每个k,每个v都是向量,输出是V中所有v的加权,其中权重是由q和每个k计算出来的,计算方法分为三步:
(1)计算比较q和k的相似度,用f来表示:

(2)将得到的相似度进行softmax归一化
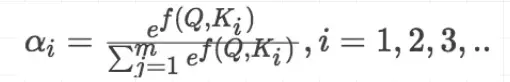
(3)针对计算出来的权重,对所有的v进行加权求和,得到attention向量
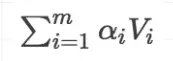
理解为:
q与一个k进行f运算,运算结果为标量,得到一个原始权重,原始权重经过softmax后变为正式权重,
对所有的v进行加权求和,得到attention向量。
计算相似度的方法有四种:

在paper中使用的是第一种方式。
接下来介绍multi-head-attention的简单版本scaled-dot-product-attention