常用便捷高效
原理:
1.实例化一个etree的对象,且需要将被解析的页面源码数据加载到该对象中。
2调用etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获
环境安装:
--pip install lxml
--如何实例化一个etree对象
--1.将本地的html文档的源码数据加载到etree的对象中:
etree.parse(filepath)
--2.将从互联网上获取源码数据加载到该对象中
etree.HTML('page_text')
--xpath('xpath表达式')
-/:表示从根节点开始定位。表示的是一个层级
-//:表示多个层级。可以表示从任意位置开始定位
-属性定位://div[@class='song'] tag[@attrName='attrValue']
-索引定位://div[@class='song']/p[3] (表示:所有div下class='song'属性下的p标签下第3个标签(索引是从1开始))
-取文本:
-/text()获取的是标签中直系的文本内容
-//text()标签中非直系的文本内容(所有的文本内容)
-取属性:
/@attrName
#解析本地html文件源码
#根据层级进行定位
from lxml import etree
#lxml.etree.XMLSyntaxError: StartTag: invalid element name, line 2, column 2
#html代码书写不规范,不符合xml解析器的使用规范
'''
解决的办法:
使用parse方法的parser参数:
parser = etree.HTMLParser(encoding=“utf-8”)
selector = etree.parse(’./data/lol_1.html’,parser=parser)
result=etree.tostring(selector)
print(result)
'''
#实例化etree对象
parser=etree.HTMLParser()
tree=etree.parse('大学排名.html',parser=parser)
r=tree.xpath('/html/head/title')
print(r) #[<Element title at 0x1f82e18ec40>]
#/表示从根节点开始定位,一个斜杠表示一个层级,
n=tree.xpath('/html/body/div')
print(n) #[<Element div at 0x1e3cc13ebc0>]
#// 两个斜杠表示多个层级
a=tree.xpath('/html//div')
print(a)
b=tree.xpath('//div')
print(b) #[<Element div at 0x1f8786cbd80>, <Element div at 0x1f8786cbe00>, <Element div at 0x1f8786cbc40>, <Element div at 0x1f8786cbe40>,...]
#属性模式
#//标签名[@class='']
c=tree.xpath('/html/body//div[@class="header shadow"]')
c=tree.xpath('//div[@class="header shadow"]')
print(c)
#索引定位
#//div[@class='']/p[3]索引从1开始表示第三个p标签
#获取标签中的文本内容 乱码需要编码解码
#/text();//text()
d=tree.xpath('//title/text()')
print(d) #['Èí¿Æ-¸ßµÈ½ÌÓýÆÀ¼ÛÁìÏÈÆ·ÅÆ']
print(d[0].encode('ISO-8859-1').decode('gbk')) #软科-高等教育评价领先品牌
d=tree.xpath('//td/text()')
#如需获取标签下的属性中的标签内的text
#tree.xpath('/html/body/div[@class='header..']/p/text()')
#for i,s in enumerate(d):
#print(d[i].encode('ISO-8859-1').decode('gbk'),end=' ') #通过for循环打印出td下所有text()的内容
#获取标签中的属性值
e=tree.xpath('/html/body/div/@id')#取得div下id=属性对应的值
print(e)
#如何从子标签进行xpath获取
#for i in d:
# i.xpath('./tr/td[1]')这里的'.'表示当前i标签,没有i则默认是从html开始的根目录标签,会报错
实例:
获取html页面中的title内容
1.查看代码需要获取的内容:
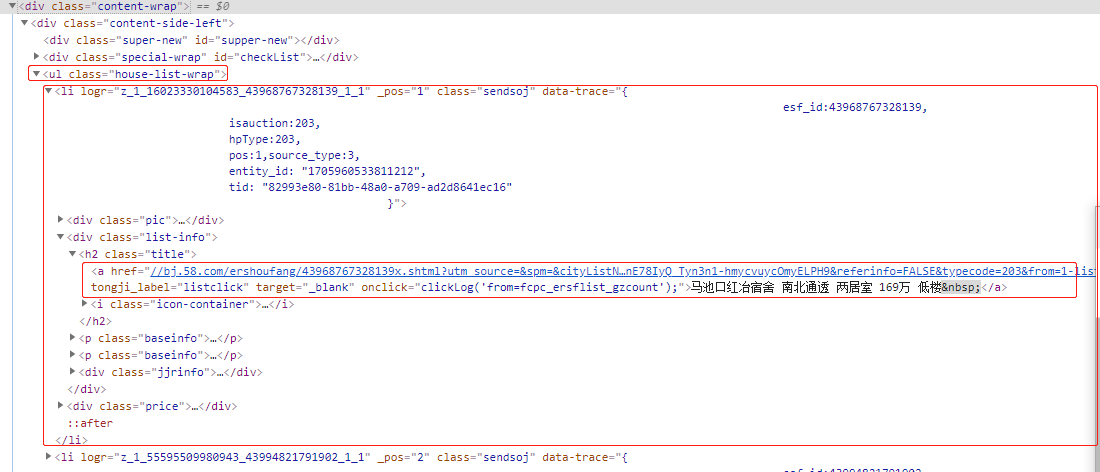

2.分析:
可以发现需要的内容在url class ="house-list-wrap"下的li标签下的第二个div标签下的a标签里
而li标签并不单一,因此需要先遍历出所有li标签,在li标签下在进行获取
3.实现:
(1)由于是本地加载会有编码上的问题,因此需要在parse中传入一个parser参数
parser=etree.HTMLParser(encoding='utf-8')
tree= etree.parse('58.html',parser=parser)
get_list=tree.xpath('//ul[@class="house-list-wrap"]/li')
(2)这里'/li'为了定位到所有'li'标签需要加上,这样返回了一个包含所有li的标签列表,(记住加了哪个标签最终定位到哪个标签,并返回该标签的列表)
[<Element li at 0x2106ef5bec0>, <Element li at 0x2106ef5be40>, <Element li at 0x2106f620680>, <Element li ....]
(3)对get_list中的li标签再进行xpath解析
li标签下的第二个div下的h2/a标签的text()

'.'表示当前li标签开始定位,若无'.'则会从根目录开始
#这里'/li'为了定位到所有'li'标签需要加上,这样返回了一个包含所有li的标签列表
print(get_list)
for i in get_list:
title=i.xpath('./div[2]/h2/a/text()')[0]
print(title)
返回所有title内容
