----------------------------------------------------------------------文章1----------------------------------------------------------------------
Flash简介:
Flash全名叫做Flash Memory,属于非易失性存储设备(Non-volatile Memory Device),与此相对应的是易失性存储设备(Volatile Memory Device)。这类设备,除了Flash,还有其他比较常见的如硬盘,ROM等。
与此相对的,易失性就是断电了,数据就丢失了,比如大家常用的内存,不论是以前的SDRAM,DDR SDRAM,还是现在的DDR2,DDR3等,都是断电后,数据就没了。
Flash的内部存储是MOSFET,里面有个悬浮门(Floating Gate),是真正存储数据的单元。
Nandflash存储器是flash存储器的一种,其内部采用非线性宏单元模式,为固态大容量内存的实现提供了廉价有效的解决方案。
Nandflash存储器具有容量较大,改写速度快等优点,适用于大量数据的存储,因而在业界得到了越来越广泛的应用,如嵌入式产品中包括数码相机、MP3随身听记忆卡、体积小巧的U盘、固态硬盘等。
Nandflash根据存储原理分为三种,SLC(Single Level Cell)、MLC( Multi-Level Cell)、TLC(Tripple Level Cell):
SLC :1个存储器储存单元可存放1 bit的数据,只存在0和1两个充电值
MLC:1个存储器储存单元可存放2 bit的数据,存在00 01 10 11表示的4个值
TLC:1个存储器储存单元可存放3 bit的数据,存在000 001 010 011 100 101 110 111表示的8个值
最早出现的是SLC,一个浮栅MOS管(cell)只存储1bit数据,这种可靠性好,寿命长。
因为半导体芯片量产成本基本上与所占硅片面积成正比,为了追求存储密度,降低闪存成本,有人想到了在一个cell里存储2bit数据,也就是通过在浮栅里灌不同数量的电荷来区分4个状态。相同的半导体制程、相同的硅片面积,存储数据多了一倍。带来的缺憾就是差错率提高、读写寿命缩短。
再后来继续追求低成本,有人造出了TLC,在一个cell里存3bit,也就是将电荷量分成8个级别,这样容量提升到3倍。结果是可靠性和寿命急剧下降。当然,普通民用,通过纠错算法和各种减小磨损的算法,可以将就着用。现在大多数闪存都用了TLC。
再后来,还有人造QLC,在一个cell里存16个状态,对应4bit。结果是寿命更短,可靠性更差。大概擦写寿命几百次吧。
Nandflash工作原理:
根据NAND的物理结构,NAND是通过绝缘层存储数据的。当你要写入数据,需要施加电压并形成一个电场,这样电子就可以通过绝缘体进入到存储单元,此时完成写入数据。如果要删除存储单元(数据),则要再次施加电压让电子穿过绝缘层,从而离开存储单元。所以,NAND闪存在重新写入新数据之前必须要删除原来数据。
由于TLC的1个存储器储存单元可存放3 bit的数据,为了区分,必须使用不同电压来实现。除了能够实现和SLC一样的000(TLC)=0(SLC)和111(TLC)=1(SLC)外、还有另外六种数据格式必须采用其他不同的电压来区分,让不同数量的电子进入到存储单元,实现不同的数据表达。这样,才能让TLC实现单位存储单元存放比SLC、MLC更多数据的目的。
为什么TLC的性能在三种介质中最差?
由于数据写入到TLC中需要八种不同电压状态, 而施加不同的电压状态、尤其是相对较高的电压,需要更长的时间才能得以实现(电压不断增高的过程,直到合适的电压值被发现才算完成)。
所以,在TLC中数据所需访问时间更长,因此传输速度更慢。经过实测,同等技术条件下,TLC的SSD性能是比不上MLC SSD的。
为什么没有机械结构的SSD还是出现寿命问题?
因为按照工作原理,闪存单元每次写入或擦除的施加电压过程都会导致绝缘体硅氧化物的物理损耗。这东西本来就只有区区10纳米的厚度,每进行一次电子穿越就会变薄一些。也正因为如此,硅氧化物越来越薄,电子可能会滞留在二氧化硅绝缘层,擦写时间也会因此延长,因为在达到何时的电压之前需要更长时间、更高的加压。主控制器是无法改变编程和擦写电压的。如果原本设计的电压值工作异常,主控就会尝试不同的电压,这自然需要时间,也会给硅氧化物带来更多压力,加速了损耗。
最后,主控控制编程和擦写一个TLC闪存单元所需要的时间也越来越长,最终达到严重影响性能、无法接受的地步,闪存区块也就废了。
同时,传统的2D闪存在达到一定密度之后每个电源存储的电荷量会下降,损耗后的TLC绝缘层,相邻的存储单元也会产生电荷干扰,发展到20nm工艺之后,Cell单元之间的干扰现象更加严重,如果数据长时间不刷新的话就会出现像之前三星840 Evo那样的读取旧文件会掉速的现象。
人们为什么会担心寿命?
由于TLC采用不同的电压状态,加上存储容量多,击穿绝缘层次数也比其他介质多,于是加速了绝缘层的损耗过程。所以,TLC SSD的寿命比SLC、MLC短得多。
一开始TLC的P/E寿命只有不到1000次,但是经过厂商改进算法以及优化主控,提升到1000到2000次。相比之下,MLC有3000到10000次擦写寿命。如果用户的PC只有TLC SSD,那么在日常使用环境下,如果一个120GB SSD的P/E寿命只有不到1000次,并且每天写入60GB的数据,那么不到五年,SSD就会报废。在目前性能过剩时代,这寿命是十分吓人的,所以以前人们十分担心TLC SSD的寿命问题。
TLC SSD为何“倒行逆施”般井喷?
三星 850 EVO、东芝 Q300、英睿达BX200……我们耳熟能详的SSD厂商都在2015年大规模推出了TLC SSD,气势磅礴。既然我们之前说了TLC那么多的不足,为何厂商依然推广呢?不是搬石头砸自己脚吗?
这一年来,SSD厂商最大的功劳就是解决了TLC的P/E寿命问题,让TLC SSD的寿命上升到我们使用一台电脑正常周期上。主控算法的好坏会对性能和寿命造成非常大的影响,目前SSD厂商在主控技术上进行了很大的改进,信号处理,更强的ECC算法、扩大备用区域的容量增加预留空间等技术应用,从TLC的500--1000次P/E提升到目前的1000到2000次,一定程度上保证了可靠性与寿命。我们知道TLC的性能比较差,尤其写入性能上,SSD厂商就通过SLC Cache的运用,只要制造一个大容量的缓冲区用户很多时候就不会感觉得到写入速度慢,而且SLC Cache玩得好还有延长寿命的作用。另外,SSD厂商对于TLC SSD的质保提升到与MLC SSD基本一致的水平,比如三星 TLC SSD的质保一般为五年,让消费者在这五年的使用中高枕无忧。加上TLC天生的价格优势,以及金字招牌,的确有很大的吸引力。越来越多的厂商参与到TLC SSD的竞争中,价格不断走低,让不少对SSD感兴趣的朋友尝鲜一把,助长了TLC SSD的壮大。
TLC的未来?
TLC的逆袭就是扬长避短的道理。有市场,就有进步,相信厂商会对TLC技术进行更多的研究,保证物美价廉的TLC继续生存下去。
比如三星3D NAND闪存就是TLC的一个重要方向。3D NAND是不再追求缩小Cell单元,而是通过3D堆叠技术封装更多Cell单元,所以我们不必要追求更先进的制程,毕竟制程约先进,寿命反而越差。所以,可以使用相对更旧的工艺来生产3D NAND闪存,使用旧工艺的好处就是P/E擦写次数大幅提升,而且电荷干扰的情况也因为使用旧工艺而大幅减少。
未来的3D NAND可能都会做成可以MLC与TLC工作模式相互切换,也就是用TLC屏蔽一半容量、来充当MLC,也就是各种所谓的3bit MLC技术创新。类似地,东芝的Q300和OCZ TRION 100用的还是更长寿稳定的企业级eTLC听起来SLC、MLC、TLC不再是泾渭分明。
文章转载自:https://blog.csdn.net/fc34235/article/details/79584758
----------------------------------------------------------------------文章2----------------------------------------------------------------------
Nandflash结构:
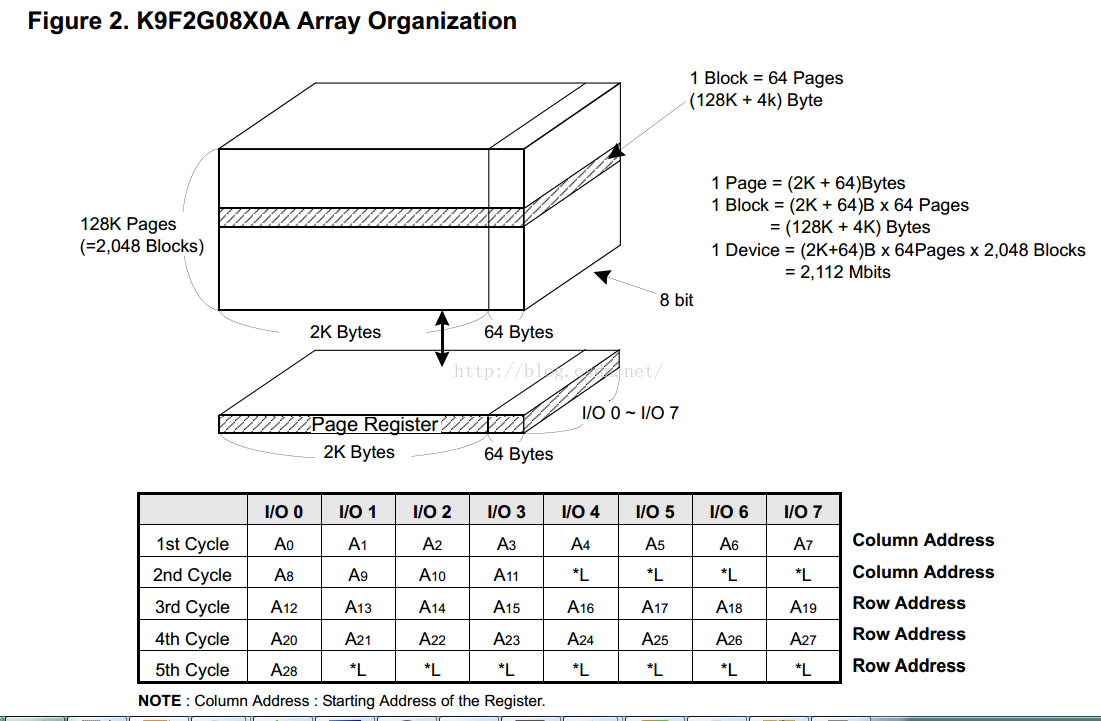
从上面的图中可以看到:一块NandFlash可以划分为2048个块,一个块分为64个页,一页分为2k+64字节的两个区,2k存放有效数据,64字节保存校验信息等。
这种划分的形式在任何NandFlash中都是一样的。只是说块数、页数、每页大小可能不一样。
Row Address - 行地址可以简单的认为是页号。
Column Address - 列地址相当于在一个页内的偏移地址。
有了页号和偏移地址便能正确的访问到每个存储单元。
块是Nandflash擦除操作的基本/最小单位。
页是Nandflash写入操作的基本/最小单位。每一个页,对应还有一块区域,叫做空闲区域(spare area)/冗余区域(redundant area),而Linux系统中,一般叫做OOB(Out Of Band),这个区域,是最初基于Nand Flash的硬件特性:数据在读写时候相对容易
错误,所以为了保证数据的正确性,必须要有对应的检测和纠错机制,此机制被叫做EDC(Error Detection Code)/ECC(Error Code Correction,或者Error Checking and Correcting),所以设计了多余的区域,用于放置数据的校验值。
Flash名称的由来
Flash的擦除操作是以block块为单位的,与此相对应的是其他很多存储设备,是以bit位为最小读取/写入的单位,Flash是一次性地擦除整个块,在发送一个擦除命令后,一次性地将一个block,常见的块的大小是128KB/256KB等,全部擦除为1,也就是里面的内容
全部都是0xFF了,由于是一下子就擦除了,相对来说,擦除用的时间很短,可以用一闪而过来形容,所以叫做Flash Memory,中文有的翻译为(快速)闪存。
Flash相对于普通设备的特殊性
|
普通设备(硬盘/内存等) |
Flash |
|
|
读取/写入的叫法 |
读取/写入 |
读取/编程(Program)① |
|
读取/写入的最小单位 |
Bit/位 |
Page/页 |
|
擦除(Erase)操作的最小单位 |
Bit/位 |
Block/块② |
|
擦除操作的含义 |
将数据删除/全部写入0 |
将整个块都擦除成全是1,也就是里面的数据都是0xFF③ |
|
对于写操作 |
直接写即可 |
在写数据之前,要先擦除,然后再写 |
Nandflash引脚功能说明
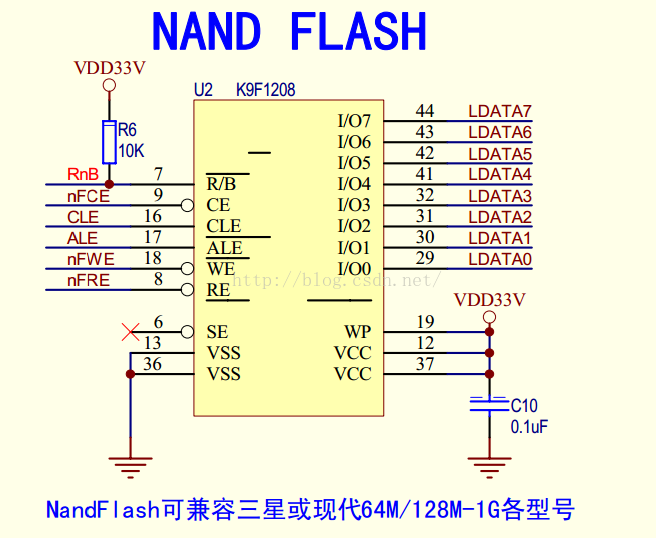
I/O0 ~ I/O7:用于输入地址/数据/命令,输出数据
CE:芯片选择
RE:读允许
WE:写允许
WP:在写或擦除期间,提供写保护
R/B:读/忙
ALE:地址锁存 ALE = 1,data0-data7上传输的是地址
CLE:命令锁存 CLE = 1,data0-data7上传输的是命令
ALE、CLE都是0的时候data0-data7上传输的是数据
WP:Write Protect,写保护
在数据手册中,你常会看到,对于一个引脚定义,有些字母上面带一横杠的,那是说明此引脚/信号是低电平有效,比如你上面看到的RE头上有个横线,就是说明,此RE是低电平有效,此外,为了书写方便,在字母下面加'_',也是表示低电平有效,比如我上面写的WP,如果字母头上啥都没有,就是默认的高电平有效,比如上面的CLE,就是高电平有效。
为何需要ALE和CLE?
那是因为,Nand Flash就8个I/O,而且是复用的,也就是,可以传数据,也可以传地址,也可以传命令,为了区分你当前传入的到底是啥,所以,先要用发一个CLE(或ALE)命令,告诉nand Flash的控制器一声,我下面要传的是命令(或地址),这样,里面才能
根据传入的内容,进行对应的动作。否则,nand flash内部,怎么知道你传入的是数据,还是地址,还是命令啊,也就无法实现正确的操作了。
Nandflash只有8个I/O引脚的好处?
1、减少外围引脚。相对于并口(Parellel)48或52个引脚的Nor Flash来说,的确是大大减小了引脚数目,这样封装后的芯片体积就小很多。现在芯片在向体积更小,功能更强,功耗更低发展,减小芯片体积就是很大的优势。同时,减少芯片接口也意味着使用此芯片
的相关的外围电路会更简化,避免了繁琐的硬件连线。
2、提高系统的可扩展性,因为没有像其他设备一样用物理大小对应的完全数目的addr引脚,在芯片内部换了芯片的大小等的改动,对于用全部的地址addr的引脚,那么就会引起这些引脚数目的增加,比如容量扩大一倍,地址空间/寻址空间扩大一倍,所以,地址线
数目/addr引脚数目,就要多加一个,而对于统一用8个I/O的引脚的Nand Flash,由于对外提供的都是统一的8个引脚,内部的芯片大小的变化或者其他的变化,对于外部使用者(比如编写nand flash驱动的人)来说,不需要关心,只是保证新的芯片,还是遵循同样的
接口,同样的时序,同样的命令就可以了,这样就提高了系统的扩展性。
Nandflash的一些典型特性
1、页擦除时间是200us,有些慢的有800us。
2、块擦除时间是1.5ms.
3、页数据读取到数据寄存器的时间一般是20us。
4、串行访问(Serial access)读取一个数据的时间是25ns,而一些旧的nand flash是30ns,甚至是50ns。
5、输入输出端口是地址和数据以及命令一起复用的。
Nandflash中的特殊硬件结构
1、页寄存器(Page Register)
由于Nand Flash读取和编程操作来说,一般最小单位是页,所以nand flash在硬件设计时候就考虑到这一特性,对于每一片都有一个对应的区域,专门用于存放将要写入到物理存储单元中去的或者刚从存储单元中读取出来的一页数
据,这个数据缓存区本质上就是一个buffer,只是名字叫法不同,datasheet里面叫做Page Register,此处翻译为页寄存器,实际理解为页缓存更为恰当些。
注意:只有写到了这个页缓存中,只有等你发了对应的编程第二阶段的确认命令0x10之后,实际的编程动作才开始,才开始把页缓存中的数据,一点点写到物理存储单元中去。
2、Nand Flash中的坏块(Bad Block)
Nand Flash中,一个块中含有1个或多个位是坏的,就成为其为坏块。
坏块的稳定性是无法保证的,也就是说,不能保证你写入的数据是对的,或者写入对了,读出来也不一定对的。而正常的块,肯定是写入读出都是正常的。
坏块有两种:
(1)一种是出厂的时候,也就是你买到的新的还没用过的Nand Flash,就可能包含了坏块。此类出厂时就有的坏块,被称作factory (masked)bad block或initial bad/invalid block,在出厂之前,就会做对应的标记,标为坏块。
具体标记的地方是,对于现在常见的页大小为2K的Nand Flash,是块中第一个页的oob起始位置(关于什么是页和oob,下面会有详细解释)的第1个字节(旧的小页面,pagesize是512B甚至256B的nand flash,坏块标记是第6个字节),如果不是0xFF,就说明是
坏块。相对应的是,所有正常的块,好的块,里面所有数据都是0xFF的。
(2)第二类叫做在使用过程中产生的,由于使用过程时间长了,在擦块除的时候,出错了,说明此块坏了,也要在程序运行过程中发现并且标记成坏块的。具体标记的位置,和上面一样。这类块叫做worn-out bad block。
对于坏块的管理,在Linux系统中,叫做坏块管理(BBM,Bad Block Managment),对应的会有一个表去记录好块,坏块的信息,以及坏块是出厂就有的,还是后来使用产生的,这个表叫做 坏块表(BBT,Bad Block Table)。在Linux内核MTD架构下的Nand
Flash驱动,和Uboot中Nand Flash驱动中,在加载完驱动之后,如果你没有加入参数主动要求跳过坏块扫描的话,那么都会去主动扫描坏块,建立必要的BBT的,以备后面坏块管理所使用。
而关于好块和坏块,Nand Flash在出厂的时候,会做出保证:
1、关于好的,可以使用的块的数目达到一定的数目,比如三星的K9G8G08U0M,整个flash一共有4096个块,出厂的时候,保证好的块至少大于3996个,也就是意思是,你新买到这个型号的nand flash,最坏的可能,有3096-3996=100个坏块。不过,事实上,
现在出厂时的坏块,比较少,绝大多数,都是使用时间长了,在使用过程中出现的。
2、保证第一个块是好的,并且一般相对来说比较耐用。做此保证的主要原因是,很多Nand Flash坏块管理方法中,就是将第一个块,用来存储上面提到的BBT,否则都是出错几率一样的块,那么也就不太好管理了,连放BBT的地方都不好找了。
一般来说,不同型号的Nand Flash的数据手册中,也会提到,自己的这个nand flash,最多允许多少个坏块。就比如上面提到的,三星的K9G8G08U0M,最多有100个坏块。
对于坏块的标记,本质上,也只是对应的flash上的某些字节的数据是非0xFF而已,所以只要是数据,就是可以读取和写入的。也就意味着,可以写入其他值,也就把这个坏块标记信息破坏了。对于出厂时的坏块,一般是不建议将标记好的信息擦除掉的。
坏块的产生,在编程的时候、在擦出的时候、在读取的时候
Nandflash中页的访问顺序
在一个块内,对每一个页进行编程的话,必须是顺序的,而不能是随机的。比如,一个块中有128个页,那么你只能先对page0编程,再对page1编程,。。。。,而不能随机的,比如先对page3,再page1,page2.,page0,page4,.。
Nandflash行地址和列地址的计算
如上图所示,Nandflash有2048Blocks,每个Block有64页,每一页含有2K的用户可以使用的数据和64B的OOB。对于用户来说这64B的数据时不用操作的,读写的时候也会忽略这部分。也就是说用户在读这一页数据的时候只会发出11位地址,不会发出12位地址(12位地址包含了读写OOB)。 如果读取0x60000地址处的数据,那么:
column_address = 0x60000 % 2048;
row_address = 0x60000 / 2048;
由于地址和数据都是通过8位引脚发送的,所以:
第一个周期发送的地址是: 0x60000 & 0xff 或column_address & 0xff;
第二个周期发送的地址为:(0x60000 >> 8) & 0x07或(column_address >> 8) & 0x07;
第三个周期发送的地址为:(0x60000 >> 11) & 0xff,这里是右移11位,不是12位,或row_address & 0xff;
第四个周期发送的地址为:(0x60000 >> 19) & 0xff,或(row_address >> 8) & 0xff;
最后一个周期发送的地址为:(0x60000 >> 27) & 0x01,或(row_address >> 16) & 0x01。
片选无关(CE don’t-care)技术
很多Nand flash支持一个叫做CE don’t-care的技术,字面意思就是,不关心是否片选,
那有人会问了,如果不片选,那还能对其操作吗?答案就是,这个技术,主要用在当时是不需要选中芯片却还可以继续操作的这些情况:在某些应用,比如录音,音频播放等应用中,外部使用的微秒(us)级的时钟周期,此处假设是比较少的2us,在进行读取一页
或者对页编程时,是对Nand Flash操作,这样的串行(Serial Access)访问的周期都是20/30/50ns,都是纳秒(ns)级的,此处假设是50ns,当你已经发了对应的读或写的命令之后,接下来只是需要Nand Flash内部去自己操作,将数据读取除了或写入进去到内部
的数据寄存器中而已,此处,如果可以把片选取消,CE是低电平有效,取消片选就是拉高电平,这样会在下一个外部命令发送过来之前,即微秒量级的时间里面,即2us-50ns≈2us,这段时间的取消片选,可以降低很少的系统功耗,但是多次的操作,就可以在很
大程度上降低整体的功耗了。
总结起来简单解释就是:由于某些外部应用的频率比较低,而Nand Flash内部操作速度比较快,所以具体读写操作的大部分时间里面,都是在等待外部命令的输入,同时却选中芯片,产生了多余的功耗,此“不关心片选”技术,就是在Nand Flash的内部的相对快速的
操作(读或写)完成之后,就取消片选,以节省系统功耗。待下次外部命令/数据/地址输入来的时候,再选中芯片,即可正常继续操作了。这样,整体上,就可以大大降低系统功耗了。
注:Nand Flash的片选与否,功耗差别会有很大。如果数据没有记错的话,我之前遇到我们系统里面的nand flash的片选,大概有5个mA的电流输出呢,要知道,整个系统优化之后的待机功耗,也才10个mA左右的。
带EDC的拷回操作以及Sector的定义(Copy-Back Operation with EDC & Sector Definition for EDC)
Copy-Back功能,简单的说就是,将一个页的数据,拷贝到另一个页。
如果没有Copy-Back功能,那么正常的做法就是,先要将那个页的数据拷贝出来放到内存的数据buffer中,读出来之后,再用写命令将这页的数据,写到新的页里面。
而Copy-Back功能的好处在于,不需要用到外部的存储空间,不需要读出来放到外部的buffer里面,而是可以直接读取数据到内部的页寄存器(page register)然后写到新的页里面去。而且为了保证数据的正确,要硬件支持EDC(Error Detection Code),否则在
数据的拷贝过程中,可能会出现错误,并且拷贝次数多了,可能会累积更多错误。
而对于错误检测来说,硬件一般支持的是512字节数据,对应有16字节用来存放校验产生的ECC数值,而这512字节一般叫做一个扇区。对于2K+64字节大小的页来说,按照512字节分,分别叫做A,B,C,D区,而后面的64字节的oob区域,按照16字节一个区,
分别叫做E,F,G,H区,对应存放A,B,C,D数据区的ECC的值。
总结:
512+16
2K +64 : A B C D - E F G H区
Copy-Back编程的主要作用在于,去掉了数据串行读取出来再串行写入进去的时间,这部分操作是比较耗时的,所以此技术可以提高编程效率,提高系统整体性能。
多片同时编程(Simultaneously Program Multi Plane)
对于有些新出的Nand Flash,支持同时对多个片进行编程,比如上面提到的三星的K9K8G08U0A,内部包含4片(Plane),分别叫做Plane0,Plane1,Plane2,Plane3。.由于硬件上,对于每一个Plane,都有对应的大小是2048+64=2112字节的页寄存器(Page
Register),使得同时支持多个Plane编程成为可能。K9K8G08U0A支持同时对2个Plane进行编程。不过要注意的是,只能对Plane0和Plane1或者Plane2和Plane3,同时编程,而不支持Plane0和Plane2同时编程。
交错页编程(Interleave Page Program)
多片同时编程,是针对一个chip里面的多个Plane来说的,
而此处的交错页编程,是指对多个chip而言的。
可以先对一个chip,假设叫chip1,里面的一页进行编程,然后此时,chip1内部就开始将数据一点点写到页里面,就出于忙的状态了,而此时可以利用这个时间,对出于就绪状态的chip2,也进行页编程,发送对应的命令后,chip2内部也就开始慢慢的写数据到存储
单元里面去了,也出于忙的状态了。此时,再去检查chip1,如果编程完成了,就可以开始下一页的编程了,然后发完命令后,就让其内部慢慢的编程吧,再去检查chip2,如果也是编程完了,也就可以进行接下来的其他页的编程了。如此,交互操作chip1和chip2,
就可以有效地利用时间,使得整体编程效率提高近2倍,大大提高nand flash的编程/擦写速度了。
随机输出页内数据(Random Data Output In a Page)
在介绍此特性之前,先要说说,与Random Data Output In a Page相对应的是,普通的,正常的输出页数据(sequential data output in a page)。
正常情况下,我们读取数据,都是先发读命令,然后等待数据从存储单元到内部的页数据寄存器中后,我们通过将RE(Read Enale,低电平有效)置低,然后从开始传入的列起始地址,一点点读出我们要的数据,直到页的末尾,当然有可能还没到页地址的末尾就不
再读了。所谓的顺序(sequential)读取也就是,根据你之前发送的列地址的起始地址开始,每读一个字节的数据出来,内部的数据指针就加1,移到下个字节的地址,然后你再读下一个字节数据,这样就可以读出你要的全部数据。
而此处的随机(random)读取,就是在你正常的顺序读取的过程中,先发一个随机读取的开始命令0x05命令,再传入你要将内部那个数据指针定位到具体什么地址,也就是2个cycle的列地址,然后再发随机读取结束命令0xE0,然后内部那个数据地址指针,就会移
动到你所指定的位置了,你接下来再读取的数据,就是从那个制定地址开始的数据了。
而nand flash数据手册里面也说了,这样的随机读取,你可以多次操作,没限制的。
请注意,上面你所传入的地址都是列地址,也就是页内地址,也就是说,对于页大小为2K的nand flash来说,所传入的地址应该是小于2048+64=2112的。
不过,实际在nand flash的使用中,好像这种用法很少的。绝大多数,都是顺序读取数据。
页编程(写操作)
Nand flash的写操作叫做编程Program,编程,一般情况下,是以页为单位的。
有的Nand Flash,比如K9K8G08U0A,支持部分页编程,但是有一些限制:在同一个页内的,连续的部分页的编程,不能超过4次。一般情况下,很少使用到部分页编程,都是以页为单位进行编程操作的。
一个操作,用两个命令去实现,看起来是多余,效率不高,但是实际上,有其特殊考虑,
至少对于块擦除来说,开始的命令0x60是擦除设置命令(erase setup comman),然后传入要擦除的块地址,然后再传入擦除确认命令(erase confirm command)0xD0,以开始擦除的操作。
这种分两步:开始设置,最后确认的命令方式,是为了避免由于外部由于无意的/未预料而产生的噪音,假设此时即使被nand flash误认为是擦除操作,但是没有之后的确认操作0xD0,nand flash就不会去擦除数据,这样使得数据更安全,不会由于噪音而误操作。
读操作过程
(1) 操作准备阶段:此处是读(Read)操作,所以先发一个读命令的第一个阶段命令0x00,,表示让硬件先准备一下,接下来的操作是读。
(2) 发送两个周期的列地址,也就是页内地址,表示我要从一个页的什么位置开始读取数据。
(3) 接下来再传入三个行地址,对应的也就是页号。
(4) 然后再发一个读操作的第二个周期命令0x30,接下来就是硬件内部自己的事情了。
(5) Nand Flash内部硬件逻辑,负责去按照你的要求,根据传入的地址,找到哪个块中的哪个页,然后把整个这一页的数据,都一点点搬运到页缓存中去。而在此期间,你所能做的事,也就只需要去读取状态寄存器,看看对应的位的值,也就是R/B那一位,是1
还是0,0的话就表示系统是busy,仍在”忙“(着读取数据),如果是1,就说系统活干完了,忙清了,已经把整个页的数据都搬运到页缓存里去了,你可以接下来读取你要的数据了。
对于这里估计有人会问了,这一个页一共2048+64字节,如果我传入的页内地址,就像上面给的1028一类的值,只是想读取1028到2011这部分数据,而不是页开始的0地址整个页的数据,那么内部硬件却读取整个页的数据出来,岂不是很浪费吗?答案是,的确很
浪费,效率看起来不高,但是实际就是这么做的,而且本身读取整个页的数据,相对时间并不长,而且读出来之后,内部数据指针会定位到你刚才所制定的1208的那个位置。
(6) 接下来,就是你“窃取“系统忙了半天之后的劳动成果的时候了。通过先去Nand Flash的控制器中的数据寄存器中写入你要读取多少个字节(byte)/字(word),然后就可以去Nand Flash控制器的FIFO中,一点点读取你要的数据了。
至此,整个Nand Flash的读操作就完成了。
spare area/oob
Nand由于最初硬件设计时候考虑到,额外的错误校验等需要空间,专门对应每个页,额外设计了叫做spare area空区域,在其他地方,比如jffs2文件系统中,也叫做oob(out of band)数据。
其具体用途,总结起来有:
1. 标记是否是坏快
2. 存储ECC数据
3. 存储一些和文件系统相关的数据,如jffs2就会用到这些空间存储一些特定信息,yaffs2文件系统,会在oob中,存放很多和自己文件系统相关的信息。
内存技术设备MTD(Memory Technology Device)
MTD,是Linux的存储设备中的一个子系统。其设计此系统的目的是,对于内存类的设备,提供一个抽象层,一个接口,使得对于硬件驱动设计者来说,可以尽量少的去关心存储格式,比如FTL,FFS2等,而只需要去提供最简单的底层硬件设备的读/写/擦除函数就
可以了。而对于数据对于上层使用者来说是如何表示的,硬件驱动设计者可以不关心,而MTD存储设备子系统都帮你做好了。
对于MTD字系统的好处,简单解释就是,他帮助你实现了很多对于以前或者其他系统来说,本来也是你驱动设计者要去实现的很多功能。换句话说,有了MTD,使得你设计Nand Flash的驱动,所要做的事情要少很多很多,因为大部分工作,都由MTD帮你做好了。
当然,这个好处的一个“副作用”就是,使得我们不了解的人去理解整个Linux驱动架构,以及MTD,变得更加复杂。但是,总的说,觉得是利远远大于弊,否则,就不仅需要你理解,而且还是做更多的工作,实现更多的功能了。
此外,还有一个重要的原因,那就是,前面提到的nand flash和普通硬盘等设备的特殊性:
有限的通过出复用来实现输入输出命令和地址/数据等的IO接口,最小单位是页而不是常见的bit,写前需擦除等,导致了这类设备,不能像平常对待硬盘等操作一样去操作,只能采取一些特殊方法,这就诞生了MTD设备的统一抽象层。
MTD,将nand flash,nor flash和其他类型的flash等设备,统一抽象成MTD设备来管理,根据这些设备的特点,上层实现了常见的操作函数封装,底层具体的内部实现,就需要驱动设计者自己来实现了。具体的内部硬件设备的读/写/擦除函数,那就是你必须实现的
了。
错误校验码
Nand Flash物理特性上使得其数据读写过程中会发生一定几率的错误,所以要有个对应的错误检测和纠正的机制,于是才有此ECC,用于数据错误的检测与纠正。Nand Flash的ECC,常见的算法有海明码和BCH,这类算法的实现,可以是软件也可以是硬件。不同
系统,根据自己的需求,采用对应的软件或者是硬件。
相对来说,硬件实现这类ECC算法,肯定要比软件速度要快,但是多加了对应的硬件部分,所以成本相对要高些。如果系统对于性能要求不是很高,那么可以采用软件实现这类ECC算法,但是由于增加了数据读取和写入前后要做的数据错误检测和纠错,所以性能
相对要降低一些,即Nand Flash的读取和写入速度相对会有所影响。其中,Linux中的软件实现ECC算法,即NAND_ECC_SOFT模式,就是用的对应的海明码。而对于目前常见的MLC的Nand Flash来说,由于容量比较大,动辄2GB,4GB,8GB等,常用BCH算
法。BCH算法,相对来说,算法比较复杂。笔者由于水平有限,目前仍未完全搞懂BCH算法的原理。
BCH算法,通常是由对应的Nand Flash的Controller中,包含对应的硬件BCH ECC模块,实现了BCH算法,而作为软件方面,需要在读取数据后,写入数据之前,分别操作对应BCH相关的寄存器,设置成BCH模式,然后读取对应的BCH状态寄存器,得知是否有错
误,和生成的BCH校验码,用于写入。其具体代码是如何操作这些寄存器的,由于是和具体的硬件,具体的nand flash的controller不同而不同,无法用同一的代码。如果你是nand flash驱动开发者,自然会得到对应的起nand flash的controller部分的datasheet,按
照手册说明,去操作即可。
不过,额外说明一下的是,关于BCH算法,往往是要从专门的做软件算法的厂家购买的,但是Micron之前在网上放出一个免费版本的BCH算法。
位反转
Nand Flash的位反转现象,主要是由以下一些原因/效应所导致:
漂移效应(Drifting Effects):漂移效应指的是,Nand Flash中cell的电压值,慢慢地变了,变的和原始值不一样了
编程干扰所产生的错误(Program-Disturb Errors):此现象有时候也叫做,过度编程效应(over-program effect),对于某个页面的编程操作,即写操作,引起非相关的其他的页面的某个位跳变了。
读操作干扰产生的错误(Read-Disturb Errors):此效应是,对一个页进行数据读取操作,却使得对应的某个位的数据,产生了永久性的变化,即Nand Flash上的该位的值变了。
Nand Flash位反转类型和解决办法
一种是nand flash物理上的数据存储的单元上的数据,是正确的,只是在读取此数据出来的数据中的某位,发生变化,出现了位反转,即读取出来的数据中,某位错了,本来是0变成1,或者本来是1变成0了。此处可以成为软件上位反转。此数据位的错误,当然可以
通过一定的校验算法检测并纠正。
另外一种,就是nand flash中的物理存储单元中,对应的某个位,物理上发生了变化,原来是1的,变成了0,或原来是0的,变成了1,发生了物理上的位的数据变化。此处可以成为硬件上的位反转。此错误,由于是物理上发生的,虽然读取出来的数据的错误,可以
通过软件或硬件去检测并纠正过来,但是物理上真正发生的位的变化,则没办法改变了。不过个人理解,好像也是可以通过擦除Erase整个数据块Block的方式去擦除此错误,不过在之后的Nand Flash的使用过程中,估计此位还是很可能继续发生同样的硬件的位反
转的错误。
以上两种类型的位反转,其实对于从Nand Flash读取出来的数据来说,解决其中的错误的位的方法,都是一样的,即通过一定的校验算法,常称为ECC,去检测出来,或检测并纠正错误。
如果只是单独检测错误,那么如果发现数据有误,那么再重新读取一次即可。
实际中更多的做法是,ECC校验发现有错误,会有对应的算法去找出哪位错误并且纠正过来。
其中对错误的检测和纠正,具体的实现方式,有软件算法,也有硬件实现,即硬件Nand Flash的控制器controller本身包含对应的硬件模块以实现数据的校验和纠错的。
文章参考自https://blog.csdn.net/zxcv1234qwert/article/details/42460697、https://blog.csdn.net/doccode/article/details/46963855、https://blog.csdn.net/luopingfeng/article/details/23621229