insert all into Employee values(1,'张三','5000','开发部') into Employee values(2,'李四','2000','销售部') into Employee values(3,'王麻子','2500','销售部') into Employee values(4,'张三表叔','8000','开发部') into Employee values(5,'李四表叔','5000','开发部') into Employee values(6,'王麻子表叔','5000','销售部') 1。SELECT EmpDepartment,SUM(EmpSalary) sum_sala FROM Employee GROUP BY EmpDepartment 2。SELECT EmpSalary,EmpDepartment,SUM(EmpSalary) OVER(PARTITION BY EmpDepartment) sum_sala FROM Employ
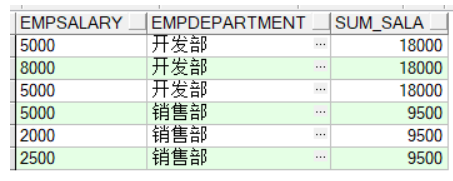
此处小结:group by 和 partition by 都有分组统计的功能,但是partition by并不具有group by的汇总功能。
partition by统计的每一条记录都存在,
而group by将所有的记录汇总成一条记录(类似于distinct EmpDepartment 去重)。
partition by可以和聚合函数结合使用,同时具有其他高级功能。
在partition by 后在加上order by:
3. SELECT EmpSalary,EmpDepartment,SUM(EmpSalary) OVER(PARTITION BY EmpDepartment ORDER BY EmpSalary) sum_sala FROM Employee
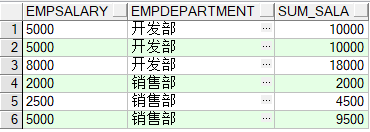
加上by后部门和 薪资相同的累加,根据排序不同的再累加。
依次类推;开发部,由于2个5000是并列的,所以计算的时候是几个并列数据之和即5000+5000=10000。本人小白,如有错误,还望指出,谢谢!!!
转自:
https://blog.csdn.net/dwt1415403329/article/details/87835383