先写个demo获取数据,我不会做太多介绍,基本上都会写在注释里。
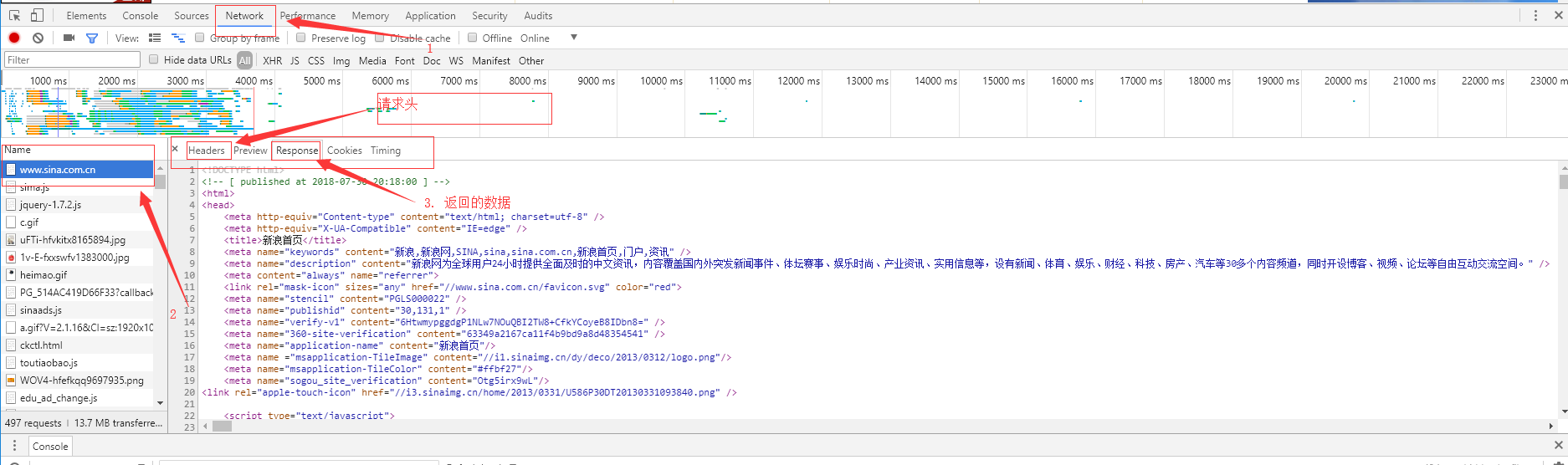
header 的数据一般就是在浏览器的调试工具里,有的网站访问需要登陆,就要加cookie。像Chrome的调试工具 快捷键是F12. 去到新浪首页,按F12调出开发者工具,然后刷新。在Network下拉到最上面就能看到一开始的请求信息(我之前是做java web的,略微会一点。)
import urllib.request header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36', } url = "http://www.sina.com" request = urllib.request.Request(url=url, headers=header) # url为爬取的链接,headers主要是假装我们不是爬虫,现在我们就假装我们是个Chrome浏览器 response = urllib.request.urlopen(request) # 请求数据 data = response.read() # 读取返回的数据 data.decode("UTF-8") # 设置字符格式为utf-8,可以处理中文
然后控制台会打印出一段html,就是新浪的首页,数据太多就不发了,发一部分截图。

然后我们用BeautifulSoup试着解析一下。
先导入BeautifulSoup, 一般都是加在最上面
import urllib.request from bs4 import BeautifulSoup
然后在最后面把 print(data) 那句去掉加上
soup = BeautifulSoup(data, "html.parser") # 把html转换成BeautifulSoup对象,这样我们就可以用BeautifulSoup的方法来解析html
print(soup) # 打印
控制台输出如下

然后我们可以
print(soup.title) # 打印标题 print(soup.find_all("a")) # 打印所有a标签
控制台输出, 因为find_all("a") 会找出所有的a标签,所以输出很多

现在就得去了解BeautifulSoup更多的知识,以便我们能更加快速得获取我们想要得信息。
忘了贴一下完整的代码
import urllib.request from bs4 import BeautifulSoup header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36' } url = "http://www.sina.com" request = urllib.request.Request(url=url, headers=header) # url为爬取的链接,headers主要是假装我们不是爬虫,现在我们就假装我们是个Chrome浏览器 response = urllib.request.urlopen(request) # 请求数据 data = response.read() # 读取返回的数据 data.decode("UTF-8") # 设置字符格式为utf-8,可以处理中文 soup = BeautifulSoup(data, "html.parser") # 把html转换成BeautifulSoup对象,这样我们就可以用BeautifulSoup的方法来解析html print(soup.title) # 打印标题 print(soup.find_all("a")) # 打印所有a标签